




- @ckc108727ckc
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2026年7月15日,上海世界人工智能大会(WAIC)前期,地瓜机器人于上海举办“开启具身智能机器人量产新纪元”媒体沟通会,对外发布旭日S600算力平台的客户落地、技术适配与生态共建成果。

2026年7月15日,上海世界人工智能大会(WAIC)前期,地瓜机器人于上海举办“开启具身智能机器人量产新纪元”媒体沟通会,对外发布旭日S600算力平台的客户落地、技术适配与生态共建成果。
RH20T数据集规模:数据集总数据量达20TB,包含超 11 万个高接触度机器人操作序列与等量的11万个人类演示视频,共计超 5000 万帧图像。该数据集包含视觉、触觉、音频等多模态信息,覆盖147种任务与42种技能。

在具身智能快速演进的时代,傅利叶持续推进 “硬件开放 + 算法共享 + 数据互通” 的开源战略,通过 Fourier Nexus 开源生态平台 搭建全球协作体系。

智元 Genie 业务部生态及解决方案总监沈咏剑表示,本届赛事是去年赛事的全面迭代升级,在赛事设计、工具链层面和选手支持方面均做了优化。一方面旨在降低开发者参赛门槛、提升参与体验,另一方面也是希望能够助力参与者在赛事实践中深化对具身智能产业的理解与认知。

国内具身智能机器人开源数据集:RoboMIND。目前,数据集包含10.7万条机器人轨迹(任务成功的轨迹),涵盖479种任务、96种物体类别和38种操作技能;

2026年初,中国具身智能赛道资本市场热度持续高涨,星海图、千寻智能、智平方这三家以“大脑”见长的企业接连完成大额融资,继宇树科技、智元机器人、银河通用之后,成功跻身百亿估值独角兽行列,行业“第一梯队”格局进一步明晰。

To B or To C ,生存还是毁灭—— 这对创业公司而言,是个值得探讨的问题。落地场景的选择,最终很有可能决定一家创业公司的生死。
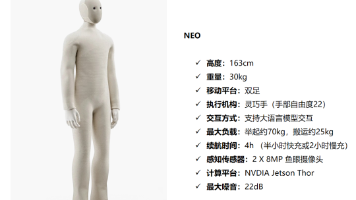
英伟达在具身智能领域的布局,正以「底层算力驱动者+ 开发生态构建者」的定位重塑具身智能机器人产业格局。其通过Jetson系列芯片提供高性能边缘计算支持,结合 Isaac/Omniverse 开发平台与 GR00T 通用基础大模型,构建了从硬件到软件的全栈技术闭环。
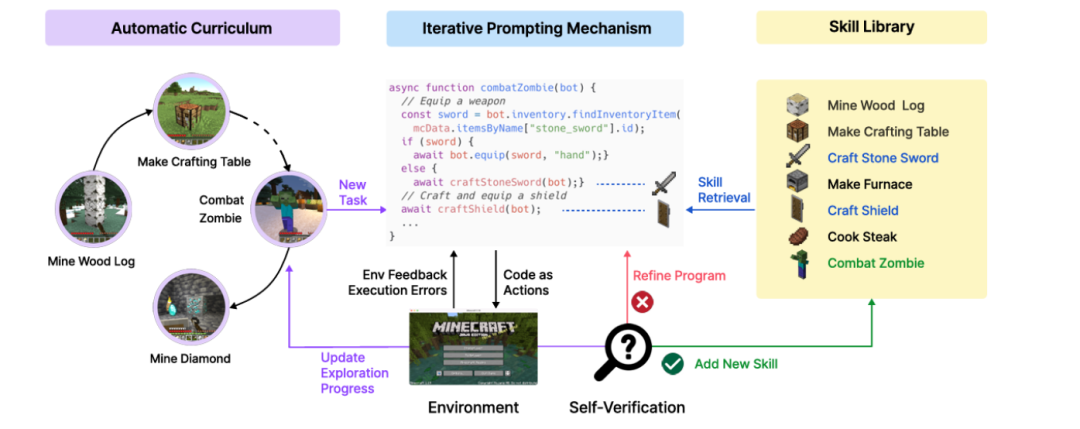
5家主流的具身智能开源数据集:Open X-Embodiment、RoboMIND、AgiBot World、RH20T和AIRO。
