




- @ai2000ai
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
今天执行git diff filename ,出现 old mode 100644 new mode 100755 的提示,如下图:但是发现文件内容并没有发生改变想起来中间执行过chmod 的操作,产生这个问题的原因就是:filemode的变化,文件chmod后其文件某些位是改变了的,如果严格的比较原文件和chmod后的文件,两者是有区别的,但是源代码通常只关心文本内容,因此chmod产生的变
在开发过程中,看到某些文件改动了,但不清楚这个改动的作者和原因,也不知道对应的BUG号,也就是说无从查到这些改动的具体原因了~【注】:某个文件的改动是有限次的,而且每次代码修改的提交都会有commit描述,我们可以从这里进行入手;一、切换到目录首先切换到要查看的文件所在的目录:[root@test01 hdt_adengine_select]# cd select_
但由于谐波的多少不同,并且各谐波的幅度各异,因而产生了不同的音色。轻轻敲鼓时,鼓膜振动的幅度小,发出的声音弱。音色是人们区别具有同样响度、同样音调的两个声音之所以不同的特性,或者说是人耳对各种频率、各种强度的声波的综合反应。另外,人们对响度的感觉还和声波的频率有关,同样强度的声波,如果其频率不同,人耳感觉到的响度也不同。通过改变它们的振幅(amplitude),即这个震动的具有的能量大小,被称为音

对于语音电话信道,每秒采集 8,000 个样本就足够了,即每 125 μs 采集一个样本,因为根据采样定理,当采集频率为最大频率两倍的电信号样本时信号,这些样本将包含重建原始信号所需的所有信息。PCM指的是脉冲编码调制(Pulse Code Modulation),是一种数字信号处理技术,将由波形表示的模拟音频信号转换为由1和0表示的数字音频信号。在电话交谈的采样中,由于样本在语音强度范围内可以有

但由于谐波的多少不同,并且各谐波的幅度各异,因而产生了不同的音色。轻轻敲鼓时,鼓膜振动的幅度小,发出的声音弱。音色是人们区别具有同样响度、同样音调的两个声音之所以不同的特性,或者说是人耳对各种频率、各种强度的声波的综合反应。另外,人们对响度的感觉还和声波的频率有关,同样强度的声波,如果其频率不同,人耳感觉到的响度也不同。通过改变它们的振幅(amplitude),即这个震动的具有的能量大小,被称为音
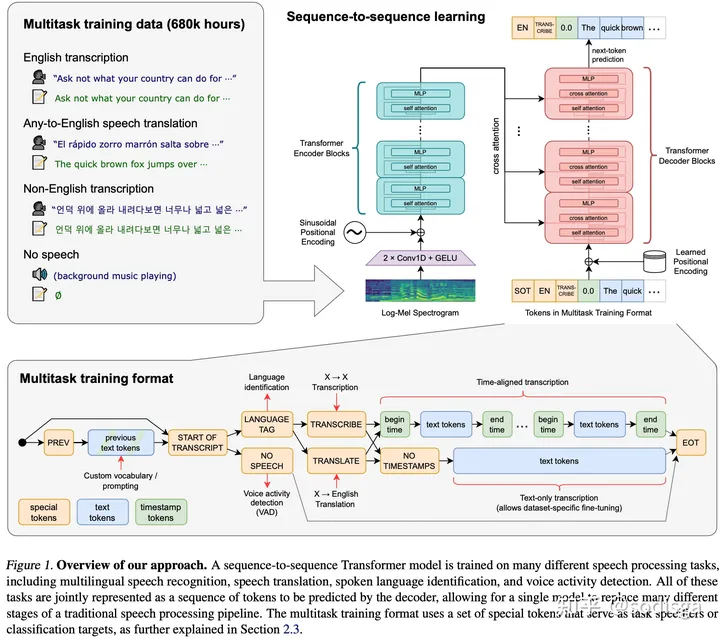
Whisper模型方法证明了只需要用大量的弱标签数据,不需要很复杂的模型和调优方法,就可以到达非常不错的识别性能,尤其是在鲁棒性和泛化性上。这也是大家比较公认的一个结论,即数据才是模型性能提升的最大影响因素。
https://trac.ffmpeg.org/wiki/HWAccelIntrohttp://www.cnblogs.com/my_life/articles/6728784.html ffmpeg -hwaccels 显示所有可用的硬件加速器watch -n 10 nvidia-smilspci -vnn | grep VGA -A 12 lshw -C displa...
但由于谐波的多少不同,并且各谐波的幅度各异,因而产生了不同的音色。轻轻敲鼓时,鼓膜振动的幅度小,发出的声音弱。音色是人们区别具有同样响度、同样音调的两个声音之所以不同的特性,或者说是人耳对各种频率、各种强度的声波的综合反应。另外,人们对响度的感觉还和声波的频率有关,同样强度的声波,如果其频率不同,人耳感觉到的响度也不同。通过改变它们的振幅(amplitude),即这个震动的具有的能量大小,被称为音
1. 下载libx265 源码下载路径: http://download.videolan.org/videolan/x265/2. 安装cmake因为libx265 是基于cmake 编译的,所以先安装cmakeapt-get install cmake -y3.编译安装libx265基于README.rst , 查看安装步骤./bootstrap &a...
Whisper模型方法证明了只需要用大量的弱标签数据,不需要很复杂的模型和调优方法,就可以到达非常不错的识别性能,尤其是在鲁棒性和泛化性上。这也是大家比较公认的一个结论,即数据才是模型性能提升的最大影响因素。