




- @ZgZg050929
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通过仅编辑静态3D高斯模型,并引入基于分数distill的时序精炼,在保证高质量编辑效果的同时,将编辑时间缩短一半以上(例如,从2小时减至40分钟),实现了显著的效率提升。监督信号生成:如图3所示,仅选取第一时刻(t=0) 的多视角图像,使用 Coherent-IP2P(一种改进了自注意力为交叉注意力以提升视图一致性的模型)根据用户指令进行编辑,生成一组已编辑的2D监督图像。与原始的形变场直接组合
主线基础论文演进方向代表论文多视角生成MVDream通用→垂直领域MEAT(人体生成)视觉编辑→语义理解4D LangSplat(4D语言场)视频生成静态稀疏→动态稀疏AdaSpa(自适应注意力)镜头内→镜头间Long Context Tuning(场景级)注意力→替代方案ΔConvFusion(卷积替代)、ViT-Linearizer(线性模型)
对比了三种范式:(a) 每帧独立3DGS(质量高,成本巨大),(b) 典型4DGS(单一规范空间+运动估计),(c) 可流式4DGS(将高斯编码为2D图像)。如图1所示,以第一帧为关键帧,到第25帧时,画面中人物的手部细节严重模糊,PSNR显著降低。视觉对比显示,AirGS在动态场景(如挥动的手)中能清晰重建细节,而基线方法(如4DGS、V³)出现明显的模糊和伪影。在训练和预览渲染中统计每个高斯被
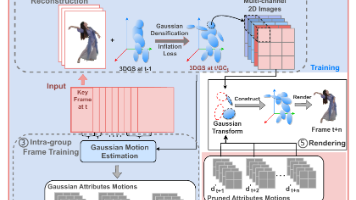
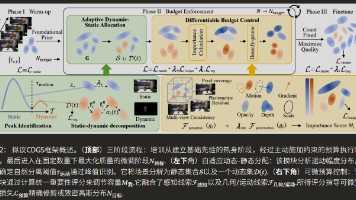
则利用其属性在时间维度上的连续性,将量化后的数据重塑为2D图像序列(类似视频帧),然后利用成熟的视频编码器(H.264)进行高效压缩。,其最终高斯数量与预设目标的误差稳定在2%以内(如图7的收敛曲线所示),并能智能分配静态与动态部分的比例。:直接量化移除该高斯会导致的渲染图像质量下降(光度残差)、该高斯在屏幕上的覆盖面积,以及其在各训练视角下贡献的一致性。,将更多的高斯“配额”分配给复杂的动态区域
肖像视频生成在游戏、影视、教育等领域应用广泛,当前行业对更真实的动画效果和更快的生成速度需求日益迫切。现有方法主要存在两大路径局限:一呢,依赖3DMM、人脸关键点等人工设计的显示运动表征(容易丢失细颗粒度运动,场景适应度差,仅仅适用于特定面部场景);二是基于预训练视频生成模型做适配(时空注意力计算量大、多步去噪流程导致推理效率低,形成生成瓶颈)。本文从“视频运动存在大量冗余可以压缩”和“自监督表征
