




- @OpenGVLab
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
作者在当下,视频无疑是连接我们日常沟通与分享的纽带。据最新数据表明,互联网上超过70%的流量都来源于视频内容,然而,AI大模型做视频理解并非易事,LeCun就曾在访谈中谈及他在视频理解领域数十年的经验心得(书生系列大模型是最早在此领域取得突破的大模型之一。2022年,InternVideo已经成在视频理解标杆Kinetics 700和Kinetics400上获得SOTA性能,且成为世界首个在K40

与其他采用300M或600M视觉编码器的多模态大模型相比,InternVL2.5-78B搭载了一个6B的视觉编码器,在仅使用1/10的训练数据量的情况下,实现了更优的性能。图1: 在OpenCompass榜单上,书生·万象2.5(InternVL2.5)在10亿~780亿量级多模态大模型中展示出强大的多模态能力,可与闭源模型相媲美,MMMU性能突破70%基于此现状,书生·万象2.5在训练、测试策略

近日,上海人工智能实验室(上海AI实验室)联合南京大学、中科院深圳先进技术研究院共同开源视频多模态大模型书生InternVideo2.5。在视频理解领域,全新升级的InternVideo2.5取得时间跨度与细粒度的双维提升,“记忆力”较前代模型扩容6倍,具备万帧长视频中精准“大海捞针”能力,AI视频理解既能“短平快”,亦可“长深细”。让AI得以更准确“看懂”纷繁的真实世界,更为多领域应用注入新质生

作者在当下,视频无疑是连接我们日常沟通与分享的纽带。据最新数据表明,互联网上超过70%的流量都来源于视频内容,然而,AI大模型做视频理解并非易事,LeCun就曾在访谈中谈及他在视频理解领域数十年的经验心得(书生系列大模型是最早在此领域取得突破的大模型之一。2022年,InternVideo已经成在视频理解标杆Kinetics 700和Kinetics400上获得SOTA性能,且成为世界首个在K40
多模态大模型迎来“迷你版”。近日,上海人工智能实验室(上海AI实验室)与清华大学等联合团队推出Mini-InternVL多模态大模型,包括1B、2B和4B三个参数版本,满足不同需求层级。评测结果显示,Mini-InternVL-4B仅以5%的参数量,即实现了InternVL2-76B约九成性能,显著减少计算成本。为适应多领域任务,联合团队提出了简单有效的迁移学习框架,使模型知识“一键”域迁移。同时

与其他采用300M或600M视觉编码器的多模态大模型相比,InternVL2.5-78B搭载了一个6B的视觉编码器,在仅使用1/10的训练数据量的情况下,实现了更优的性能。图1: 在OpenCompass榜单上,书生·万象2.5(InternVL2.5)在10亿~780亿量级多模态大模型中展示出强大的多模态能力,可与闭源模型相媲美,MMMU性能突破70%基于此现状,书生·万象2.5在训练、测试策略
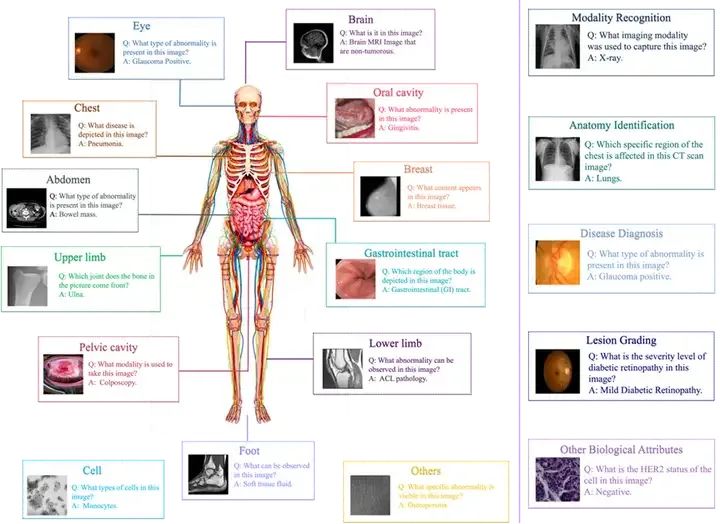
在过去的两年里,计算机视觉领域涌现出了多种不同的多模态大模型(LVLM),如BLIP2, MiniGPT4等。这些大模型在多种不同的视觉任务上取得了亮眼的效果。为了准确评估多模态大模型的能力,许多研究人员从不同角度对模型进行了评测[1,2]。结果显示,LVLM在各种多模态任务中展示了卓越的能力。但是,这些评测工作大多只关注LVLM在通用视觉任务中的效果,它们在医学领域的潜力尚未被充分探索。这些多模
与其他采用300M或600M视觉编码器的多模态大模型相比,InternVL2.5-78B搭载了一个6B的视觉编码器,在仅使用1/10的训练数据量的情况下,实现了更优的性能。图1: 在OpenCompass榜单上,书生·万象2.5(InternVL2.5)在10亿~780亿量级多模态大模型中展示出强大的多模态能力,可与闭源模型相媲美,MMMU性能突破70%基于此现状,书生·万象2.5在训练、测试策略
作者在当下,视频无疑是连接我们日常沟通与分享的纽带。据最新数据表明,互联网上超过70%的流量都来源于视频内容,然而,AI大模型做视频理解并非易事,LeCun就曾在访谈中谈及他在视频理解领域数十年的经验心得(书生系列大模型是最早在此领域取得突破的大模型之一。2022年,InternVideo已经成在视频理解标杆Kinetics 700和Kinetics400上获得SOTA性能,且成为世界首个在K40
近日,上海人工智能实验室(上海AI实验室)联合南京大学、中科院深圳先进技术研究院共同开源视频多模态大模型书生InternVideo2.5。在视频理解领域,全新升级的InternVideo2.5取得时间跨度与细粒度的双维提升,“记忆力”较前代模型扩容6倍,具备万帧长视频中精准“大海捞针”能力,AI视频理解既能“短平快”,亦可“长深细”。让AI得以更准确“看懂”纷繁的真实世界,更为多领域应用注入新质生