




- @HySpark
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
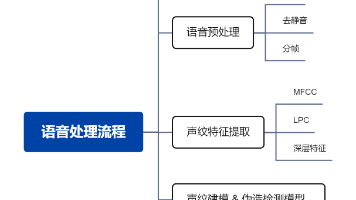
在 AI 语音识别场景中,语音数据来源复杂,通话环境不可控,往往伴随强背景噪声、回声、通道失真以及大量无效静音片段。如果直接对原始语音进行识别或声纹建模,效果会明显下降。因此,在整个系统中,。熙瑾会悟系统,基于“可落地、可部署”的原则,设计了一套基于声纹预处理的智能语音处理流程,为后续的诈骗识别、说话人建模和行为分析提供高质量输入。

针对AI合成语音的检测方案。采用多特征融合策略,结合传统声学特征(MFCC、LPC)和深层声纹特征(x-vector等),从声纹提取和伪造检测两个维度构建识别能力。针对合成语音,系统采用"传统规则+深度学习"的混合方法:先用频谱异常、韵律节奏等规则快速筛选,再通过CNN/LSTM/Transformer等深度模型进行精细检测。方案注重实际部署,通过捕捉声学细节的人工痕迹,在保证
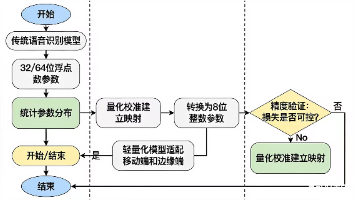
智能语音识别通过模型压缩(量化、剪枝)优化存储与运算,提升效率与实时性;增量学习应对新型语音,保证模型更新;利用TensorFlow Lite等工具实现高效部署,适应移动端和边缘设备。
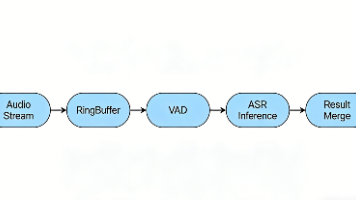
本文探讨了实时语音识别(ASR)系统面临的两大核心问题:低音量导致的识别不稳定和断句过碎问题。通过自适应过滤(音频前处理)和多级分句策略(文本后处理)的协同优化,显著提升了系统性能。音频处理采用自适应增益(AGC)和降噪技术改善输入质量,文本处理则通过三级分句(时间窗口、标点恢复、语义规则)和缓冲机制实现自然流畅的输出。特别推荐WebRTC Audio Processing模块进行音频处理,并强调
《离线AI助手开发核心问题与解决方案》摘要:本文分享了熙瑾会悟离线转记产品开发中的实战经验,重点解决了离线场景下的四大技术难题:1)通过滑动窗口和权重排序机制优化多轮对话连贯性;2)采用轻量化ASR模型和分片预处理技术提升语音识别准确率;3)构建分层记忆管理体系解决存储冗余问题;4)应用INT8量化和向量检索技术实现端侧高效推理。最终使多轮对话连贯率提升95%,语音识别准确率达98%,存储冗余降低
本文分享了离线语音转写系统开发中的技术难点与解决方案。针对静音幻觉问题,采用三层降噪+VAD增强方案;基于Qwen-ASR模型优化时间戳对齐,误差控制在50ms内;通过多进程隔离、内存复用等技术实现32路高并发稳定运行。系统最终实现了纯净转写、精准时间戳、低延迟等目标,适用于企业本地化部署场景。文章详细介绍了从音频预处理、模型优化到高并发架构的全链路技术方案,为离线语音识别项目提供了实战参考。
近期在迭代熙瑾会悟离线会议转记功能时,深度集成 Qwen-ASR 离线语音模型与第三方实时纠错 SDK。实际开发联调阶段,频繁遇到 SDK 初始化失败、流式纠错失效、长音频内存溢出、文本错乱等一系列线上从未出现的适配问题。本文结合真实项目排坑经历,从技术栈、问题复现、根因分析、分步解决方案、优化效果全方位复盘,记录离线环境下 ASR + 文本纠错 SDK 联动开发的实战经验,给做端侧离线语音、会议
针对熙瑾会悟离线会议转记项目开发过程中,遇到的WebRTC VAD人声检测不准、流式ASR静音幻觉、音频分片错位、端侧推理卡顿四大问题进行深度复盘。结合Qwen-ASR离线流式模型、WebRTC VAD、FFmpeg音频处理技术,给出可落地的工程优化方案。通过防抖帧校验、静音阻断输入、固定分片时长、异步队列解耦等优化方式,大幅度提升离线转写的流畅度与准确率。本文所有方案均已落地生产,适合端侧离线A
《实时ASR系统的工程优化实践》摘要:实时语音识别系统的典型工程问题及解决方案。针对吞字、重复识别、延迟抖动和中英混杂识别差等问题,通过重构处理链路为状态机驱动模型、优化并发调度与GC策略、升级至WhisperV2模型等系统性改进,使重复率下降90%,延迟稳定在400ms内,显著提升了系统稳定性。
针对AI合成语音的检测方案。采用多特征融合策略,结合传统声学特征(MFCC、LPC)和深层声纹特征(x-vector等),从声纹提取和伪造检测两个维度构建识别能力。针对合成语音,系统采用"传统规则+深度学习"的混合方法:先用频谱异常、韵律节奏等规则快速筛选,再通过CNN/LSTM/Transformer等深度模型进行精细检测。方案注重实际部署,通过捕捉声学细节的人工痕迹,在保证