




- @GateWorld
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
从MCU到MIPI的显示通信演进 本文系统剖析了主流LCD显示接口技术,揭示了不同应用场景下的接口选择逻辑。文章首先建立了从应用层到物理层的三层通信模型框架,随后详细解析了四种关键接口技术:MCU接口适用于小尺寸低功耗场景,通过GRAM实现简单控制;RGB接口采用实时像素流传输,适合中低分辨率视频应用;LVDS接口利用差分信号解决高速传输难题,支持更高分辨率;MIPI DSI作为移动设备主流方案,

I2C协议通过SCL时钟线和SDA数据线实现高效硬件握手,采用三层握手机制:字节级(ACK/NACK)、事务级(START/STOP)和时钟级(时钟拉伸)。其核心是利用线与逻辑实现总线仲裁,从机可通过保持SCL低电平控制通信节奏。典型传输包含地址确认、数据交换和应答机制,状态机设计确保可靠通信。这种简洁的两线制协议完美展现了硬件握手在嵌入式系统中的精妙应用。

DSP Slice是FPGA中用于高速计算的专用硬件模块,可高效执行数字信号处理、图像处理和AI推理等计算密集型任务。相比通用逻辑实现,DSP Slice具有高性能、低功耗和高密度优势,支持数百MHz运算频率。 典型DSP Slice包含预加法器、乘法器、累加器/加法器和流水线寄存器等核心部件,支持多种工作模式: 乘法模式(MULT) 乘加/乘减模式(MULT-ADD/MULT-SUB) 累加模式

Xilinx Vivado高度支持2009标准大部分特性(接口、枚举等),Intel Quartus良好支持2005标准核心功能,Microchip/Lattice仅支持基本特性。三大厂商均完全支持always_comb/ff/latch、logic/bit类型、打包数组等核心语法。建议根据目标器件选择工具版本:Vivado 2018.1+、Quartus 18.0+、Diamond 3.12+可

FPGA芯片中的DSP硬核是高性能计算的关键资源,但使用不当会导致功能错误、性能下降等问题。本文总结了三大类常见陷阱: 功能正确性:有符号/无符号数混用导致隐式转换错误;复位策略不匹配造成初始值异常;乘累加模式下饱和/进位逻辑配置不当。 性能优化:流水线深度不足限制频率;位宽过度扩展浪费资源;跨时钟域数据引发时序问题。 系统集成:IP核配置冲突;功耗热效应导致性能衰减;仿真模型与硬件行为差异;工具

本文深入解析了FPGA中DDR3内存的Training Process(训练过程),这是确保高速存储稳定性的关键机制。DDR3在高频率下会面临信号传输延迟、时钟偏移等问题,需要通过训练来动态补偿。训练过程分为三个阶段:写电平校准(调整写时序)、读门训练(确定读使能时机)和读数据眼训练(定位最佳采样点)。当训练失败时,90%的问题源于硬件,需检查电源、时钟和PCB走线等,并利用Vivado调试工具分

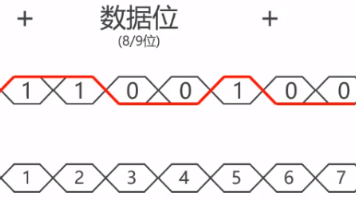
UART是一种异步串行通信协议,通过起始位、数据位(5-9位)、可选校验位及停止位构成数据帧,支持全双工点对点通信。其核心优势是硬件简单、成本低,但需严格匹配波特率(误差<5%)。物理层扩展包括RS-232(单端信号)、RS-485(差分抗干扰)及低功耗LVTTL。局限性包括无法直接组网、缺乏流控(可软件XON/XOFF替代)及长距传输瓶颈(需桥接芯片)。典型应用涵盖嵌入式调试、工业控制等场景。
本文深入解析了FPGA中DDR3内存的Training Process(训练过程),这是确保高速存储稳定性的关键机制。DDR3在高频率下会面临信号传输延迟、时钟偏移等问题,需要通过训练来动态补偿。训练过程分为三个阶段:写电平校准(调整写时序)、读门训练(确定读使能时机)和读数据眼训练(定位最佳采样点)。当训练失败时,90%的问题源于硬件,需检查电源、时钟和PCB走线等,并利用Vivado调试工具分