




- @Damon_X
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在大多数现代设备(包括 Android 手机、嵌入式设备等)上,确实是使用类型的内存。
这两个函数都与 VSync 相关,但它们的作用和触发时机不同。,然后开始新的帧合成(Frame Composition)。(例如 60Hz 设备,每 16.67ms 触发一次)。,请求 SurfaceFlinger 开始新的合成。发现需要更新某些图层(不依赖 VSync),调用。触发,用于通知 SurfaceFlinger。,让 SurfaceFlinger 重新提交帧。开始新的合成(compos
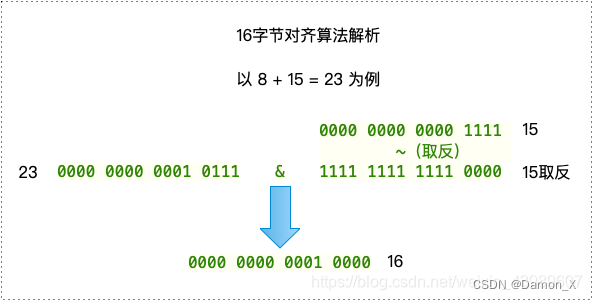
最后将 23 与 15的取反结果 进行 &(与)操作,&(与)的规则是:都是1为1,反之为0,最后的结果为 16,即内存的大小是以16的倍数增加的。原理为 首先若x=8 将原始的内存 8 与 size_t(15)相加,得到 8 + 15 = 23。将 size_t(15) 即 15进行~(取反)操作,~(取反)的规则是:1变为0,0变为1。类似 (8 + 15 ) >> 4 << 416字节对齐。
一 上一篇介绍了 Linux 的显示驱动drm 的架构,在这里按一定顺序回顾一下: 1 我把显示器连到显卡的DVI输出口, 这个连接抽象成 Connector 2 在 DVI 的 Connector 上驱动会分配 DVI 信号的 Encoder , 如果没分配, connector 资源上会找到 所有可用的 encoders 3 encoder 是为图像扫描现场
参数物理意义DMA 每消耗 period_size frames,就触发一次 IRQring buffer 中 period 的个数,用于双缓冲或多缓冲ring buffer 总容量示例:period_size = 240 frames period_count = 2 buffer_size = 480 frames sample_rate = 48000 Hz latency = 480 /
以上是对卷积的优化。如果你一次只处理一个元素:需要 16 次 mul需要 16 次 add需要 16 次 loadCPU 负担重NEON 版本一次处理 4 个元素:4 次 load → 1 次 vld1q4 次 mul → 1 次 vmulq4 次 add → 1 次 vaddq🚀。
在大多数现代设备(包括 Android 手机、嵌入式设备等)上,确实是使用类型的内存。
特性MP4MKVF4V核心理念国际标准,严谨模块化开源灵活,高度可扩展基于MP4的Flash专用变种结构基础盒子EBML元素盒子MIME类型video/mp4audio/mp4通常被识别为video/mp4或通常由或处理核心理解:容器的“盒子/原子”结构与Android的“MIME驱动Extractor”机制,共同构成了多媒体处理的基石。ftyp是容器自我声明的起点,系统据此选择正确的“翻译官”。
特性Power Rail本质关时钟信号关电源供应电源供应网络本身目的降低动态功耗消除动态+静态功耗分配和输送电源电压实现层级RTL/门级,自动系统级,需特殊单元物理设计(布局布线)省电效果中等(只省动态)极强(全消除)不直接省电,是供电基础唤醒延迟极短(1个周期)很长(几千周期)不适用设计复杂性低高非常高(影响芯片成败)类比停掉生产线传送带拉掉整个工厂电闸工厂的输电网和电线Power Rail是“