




- @CPWWHSU
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
上一章深入剖析了vsg::RenderGraph对Vulkan渲染流程的封装,重点探讨了vsg::FrameBuffer、vsg::RenderPass和vsg::ImageView三个Vulkan渲染过程中的核心组件。本章将在该基础上,进一步探讨Vulkan渲染过程中的另一核心组件——VkPipeline,以及vsg中针对图形渲染管线的封装GraphicsPipeline。目录1 Graphic

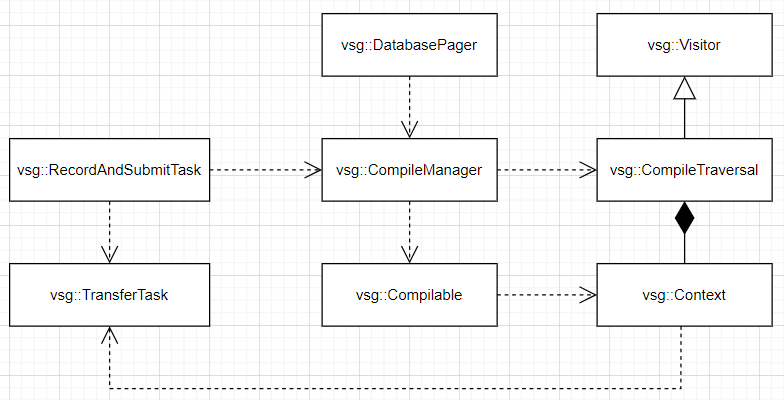
上一章深入剖析了GPU资源内存及其管理,vsg中为了提高设备内存的利用率,同时减少内存(GPU)碎片,采用GPU资源内存池机制(vsg::MemoryBufferPools)管理逻辑缓存(VkBuffer)与物理内存(VkDeviceMemory)。本章将深入vsg中vulkan资源的编译(包含视景器编译),着重于当vsg::TransferTask不为空时,vulkan资源的创建与收集过程,包含
大语言模型无法直接处理原始字符串,必须先将文本切分为词元(Token);随后结合模型内置的词汇表与嵌入(Embedding)矩阵,将词元数组映射为高维向量序列,作为后续模型推理计算的输入基础。本章将深入探讨大语言模型推理的关键准备环节——词汇表与分词,从基础知识、实验与现象和分析与结论三个方面展开详细的介绍。
摘要:本文深入探讨了基于GGUF格式的大语言模型加载与初始化过程。首先介绍了GGUF格式的特点和文件结构,包括头文件、张量信息和数据三部分。随后从代码层面分析了llama.cpp中的模型加载流程,详细阐述了从server_context到llama_model的调用路径,以及gguf_context和ggml_context的解析过程。文章还提及了GPU计算后端加载和tensor处理等关键环节,为

llama-server是llama.cpp中用于发布大模型服务的工具。它通过极简的命令行配置,将复杂的模型推理过程封装为通用的 HTTP 接口;在底层,它选择以纯 C++ 编写的 cpp-httplib 作为服务框架的底层。本章分为应用实战与底层架构两部分。首先,我们将介绍不同参数下的大模型服务发布;接着,我们将详细解析 cpp-httplib 在项目中的具体实现,帮助读者掌握该服务端在网络调度

llama-server是llama.cpp中用于发布大模型服务的工具。它通过极简的命令行配置,将复杂的模型推理过程封装为通用的 HTTP 接口;在底层,它选择以纯 C++ 编写的 cpp-httplib 作为服务框架的底层。本章分为应用实战与底层架构两部分。首先,我们将介绍不同参数下的大模型服务发布;接着,我们将详细解析 cpp-httplib 在项目中的具体实现,帮助读者掌握该服务端在网络调度