




- @Alex_StarSky
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
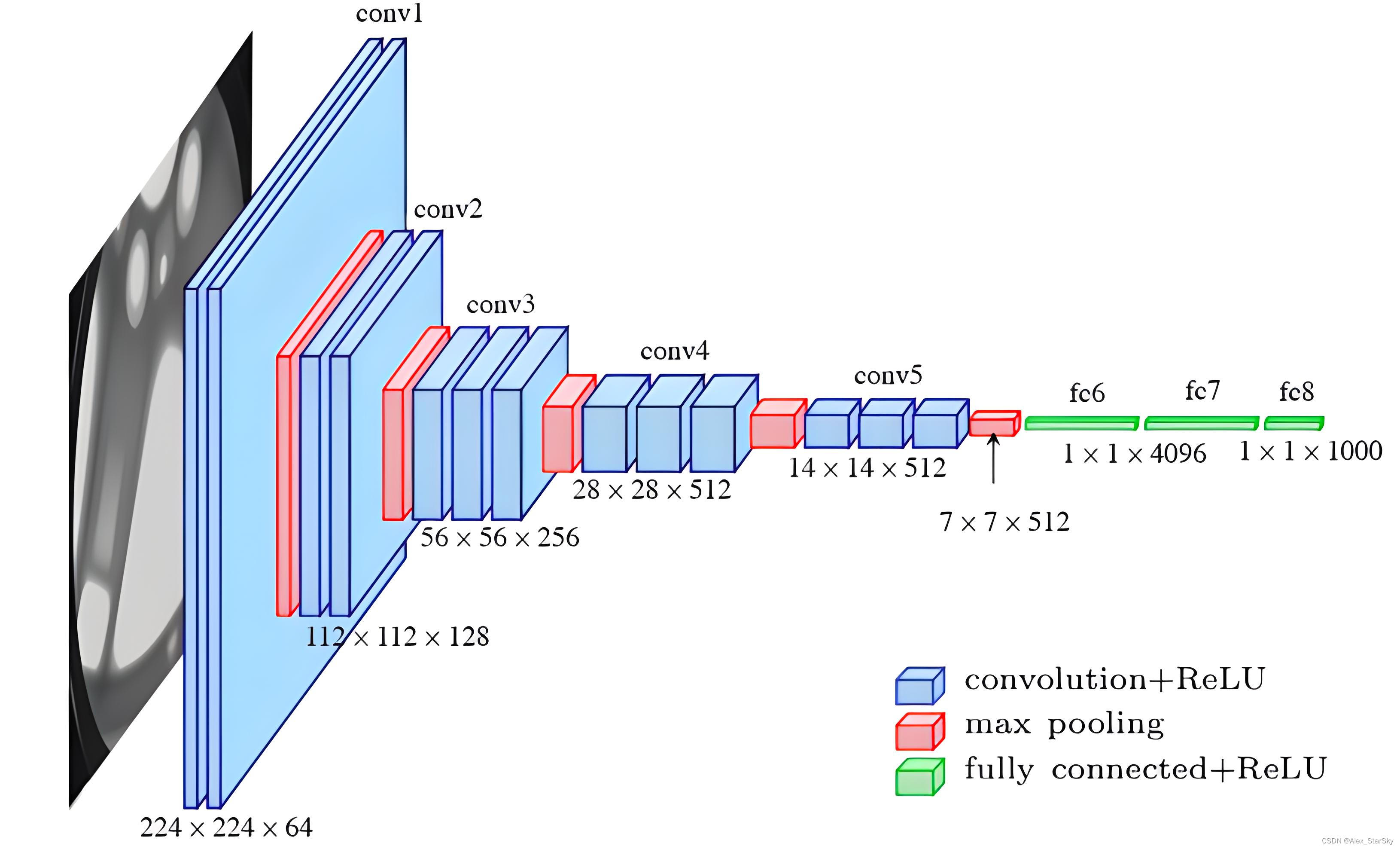
深度学习中,经典网络引领一波又一波的技术革命,从LetNet到当前最火的GPT所用的Transformer,它们把AI技术不断推向高潮。2012年AlexNet大放异彩,它把深度学习技术引领第一个高峰,打开人们的视野。2014年,牛津大学计算机视觉组(**V**isual **G**eometry **G**roup)和DeepMind公司一起研发了新的卷积神经网络,并命名为VGGNet。VGGN
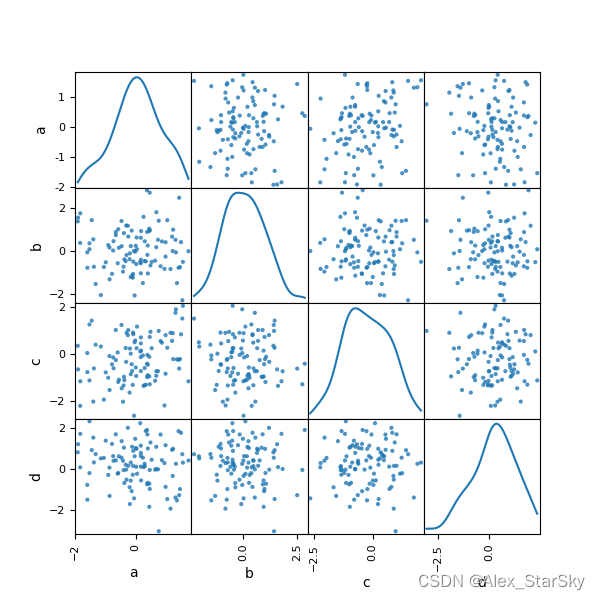
数据表如何整合,尤其是多源表,属性表,时间序列数据表的整合,在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。数据分析过程中重新调整,重塑数据表是很重要的技巧,此处选择,以及巴黎、伦敦欧洲城市NO2作为样例。NO2。

散点图矩阵是一种显示多个变量之间关系的数据可视化工具,特别是当数据集包含三个或多个变量时非常有用。通常在探索性数据分析中使用,以便快速理解数据集中变量之间的关系。
深度学习中,经典网络引领一波又一波的技术革命,从LetNet到当前最火的GPT所用的Transformer,它们把AI技术不断推向高潮。2012年AlexNet大放异彩,它把深度学习技术引领第一个高峰,打开人们的视野。2014年,牛津大学计算机视觉组(**V**isual **G**eometry **G**roup)和DeepMind公司一起研发了新的卷积神经网络,并命名为VGGNet。VGGN
在指定磁盘(如 E 盘)新建文件夹,命名为如 "article_trainer"。比如想让模型在医疗领域表现更好,就收集医疗相关的文本数据,像医学论文、病例、医疗问答等。如果是基于 DeepSeek 模型做通用文本生成的微调,也可以收集各种类型的优质文本,如新闻、小说、科普文章等。:去除数据中的噪声和错误,比如乱码、重复数据、不完整的数据等。同时,删除带特殊符号的内容,统一文章长度,如每篇 500

在指定磁盘(如 E 盘)新建文件夹,命名为如 "article_trainer"。比如想让模型在医疗领域表现更好,就收集医疗相关的文本数据,像医学论文、病例、医疗问答等。如果是基于 DeepSeek 模型做通用文本生成的微调,也可以收集各种类型的优质文本,如新闻、小说、科普文章等。:去除数据中的噪声和错误,比如乱码、重复数据、不完整的数据等。同时,删除带特殊符号的内容,统一文章长度,如每篇 500
一个免费查询股票信息的API接口。股票研究的实践中需要查询股票市场接口,百度搜索大多链接都要收费或者注册。

prompt 用于向模型明确指定要执行的任务。例如,在文本生成任务中,如果。

在指定磁盘(如 E 盘)新建文件夹,命名为如 "article_trainer"。比如想让模型在医疗领域表现更好,就收集医疗相关的文本数据,像医学论文、病例、医疗问答等。如果是基于 DeepSeek 模型做通用文本生成的微调,也可以收集各种类型的优质文本,如新闻、小说、科普文章等。:去除数据中的噪声和错误,比如乱码、重复数据、不完整的数据等。同时,删除带特殊符号的内容,统一文章长度,如每篇 500
什么预训练?什么是pretraining?什么是Base model,什么是SFT model?CPT和ChatGPT是一样的吗?以GPT为例,LLM训练流程分为4个阶段:预训练,监督微调训练,奖励评价训练,强化学习。分别生成预训练模型(Base model,基础模型),如GPT3,GPT4;监督精调模型SFT模型,RM奖励评价模型,和最后的生成模型,如ChatGPT。