




- @2609_95049439
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
下面是一套可以在 K8s 集群外侧或 Custom Metrics Adapter 中运行的 Python 监控与自动化伸缩评估代码。"""生产级 vLLM 显存利用率与 K8s 动态扩缩容评估探针作者: 苏沁宁 (苏苏)""""""vLLM 推理引擎 Prometheus 指标拉取与 HPA 决策器"""try:# 提取浮点数值logger.error(f"查询 Prometheus 指标失败
掉拍子的鼓手留不住听众,容易崩溃失忆的 Agent 留不住用户。通过把大模型 Agent 的运行逻辑收拢为 LangGraph 强类型状态图,结合持久化 Checkpoint 与 K8s 节点容错,才能让 Agent 在面对云原生环境的网络抖动与 Pod 重启时,依然像打了稳固节拍一样死死卡住执行节奏,提供真正工业级的稳定性。
掉拍子的鼓手留不住听众,容易崩溃失忆的 Agent 留不住用户。通过把大模型 Agent 的运行逻辑收拢为 LangGraph 强类型状态图,结合持久化 Checkpoint 与 K8s 节点容错,才能让 Agent 在面对云原生环境的网络抖动与 Pod 重启时,依然像打了稳固节拍一样死死卡住执行节奏,提供真正工业级的稳定性。
随着机器学习和人工智能的快速发展,在Kubernetes上部署和管理ML工作负载已经成为趋势。本文将深入探讨如何在Kubernetes环境中高效运行机器学习训练和推理工作负载。
训练调度:使用Kubeflow管理ML工作流模型管理:使用MLflow进行模型版本控制GPU资源:配置GPU节点池和资源调度数据存储:部署MinIO管理数据集开发环境:使用JupyterHub提供交互式开发可视化:配置TensorBoard进行实验追踪模型部署:使用TensorFlow Serving部署模型监控告警:建立训练指标和资源使用监控建议根据团队规模和业务需求选择合适的组件,构建高效的M
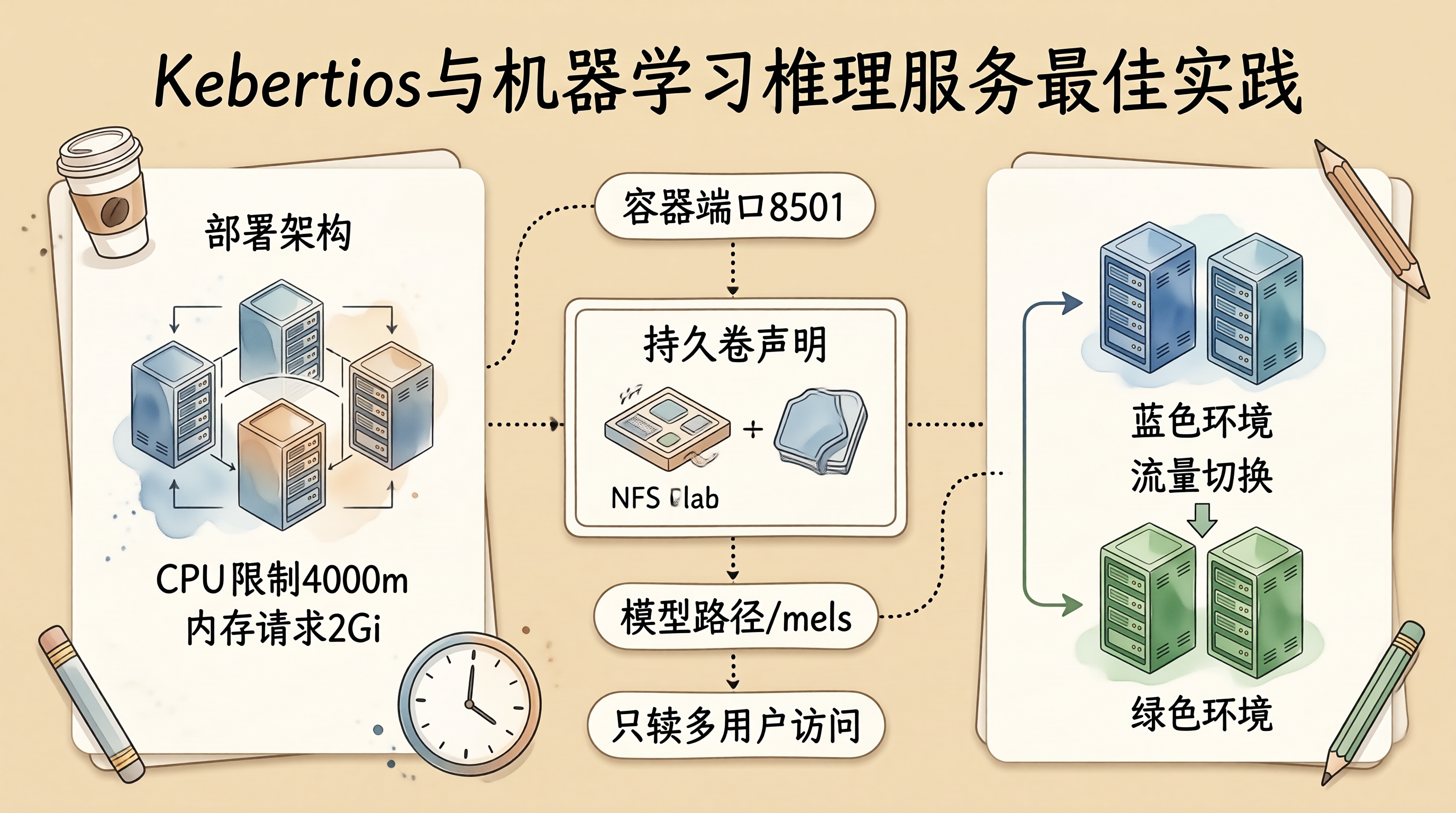
实践领域关键要点模型存储使用只读多挂载PVC,确保模型一致性部署策略采用蓝绿部署,实现零停机更新资源管理根据推理需求合理设置资源请求和限制自动扩缩容结合CPU利用率和QPS指标进行弹性伸缩模型优化使用TensorRT、ONNX Runtime等优化推理性能监控告警监控推理延迟、吞吐量和错误率安全防护实施请求认证和访问控制Kubernetes为机器学习推理服务提供了强大的基础设施支撑。通过合理的架构
冷热备方案的冷启动超时排查需要按"确认现象→分段测量→根因分析→修复验证"四步走。80% 的超时问题集中在镜像拉取和模型加载两个阶段,通过镜像缓存、模型量化、GPU 预留和探针宽容配置,可以将冷备切换时间从 120s+ 压缩到 30s 以内。本文介绍了该技术的核心原理和实践应用。理解核心算法的工作原理实现优化策略提升性能注意资源管理避免内存泄漏根据实际场景选择合适的配置进行性能测试确定瓶颈逐步引入

优化策略适用场景性能提升实施复杂度NCCL 算法调优AllReduce 瓶颈+30%低网络拓扑感知多节点训练+50%中并行策略自动选择异构网络+40%高高性能训练+200%高核心思路:通过 Kubeflow Pipeline 自动化诊断网络瓶颈、选择并行策略、配置 NCCL 参数,将分布式训练的网络优化从"手动调参"升级为"自动决策"。实测表明,网络感知的调度模型可将大模型训练效率提升 40-60
Kubeflow 多租户 GPU 隔离的核心是三步走:先共享(Volcano GPU Share),再隔离(MPS + cgroup),最后监控(ResourceQuota + Prometheus)。在保障租户公平性的同时,将 GPU 利用率从 35% 提升到 80%+,实现算力的最大化利用。大语言模型的流式输出技术显著提升了用户体验。使用 SSE 或 WebSocket 实现流式传输实现增量渲
GPU HPA 冷启动超时的核心矛盾是:HPA 的检测速度与 Pod 冷启动速度不匹配。通过 KEDA 缩短检测周期到 5s、共享内存加速模型加载到 <5s、优化 StartupProbe 参数,可将端到端扩容延迟从 85s 压缩到 20s 以内,使 GPU HPA 真正实现"实时弹性"。本文介绍了该技术的核心原理和实践应用。理解核心算法的工作原理实现优化策略提升性能注意资源管理避免内存泄漏根据实
