
写文章




- @2403_87082399
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
提升 LLM 推理效率的秘密武器:LM Cache 架构与实践
LM Cache 是以记忆机制提升 LLM 系统性能的有效路径。通过缓存 prompt、token 或 KV 状态,系统能以更低延迟、更高吞吐显著缩减成本,广泛用于聊天机器人、内容生成、代码辅助、RAG 等核心场景。如果你正在构建或优化 LLM 推理服务,LM Cache 无疑值得你纳入技术架构考量中。

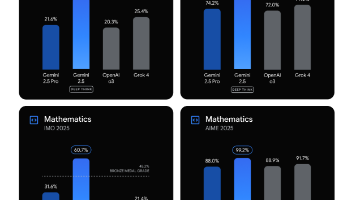
Google 推出 Gemini 2.5 Deep Think:多 Agent 推理模型,AI 推理迈向深度思考
是 Google DeepMind 最新推出的多 Agent 推理模型,它能同时生成多个思路(parallel reasoning paths),然后交叉比较、筛选最佳答案。区别于传统单一模型的推理方式,这种架构能在复杂任务上取得更优效果TechCrunchAI Insider。是 Google DeepMind 推出的第一个商业可用的多 Agent 推理模型;它提供了人类式多思路并行推理能力,在
YAML 嵌入式語言:不仅是配置,更是逻辑容器
所谓嵌入式语言(Embedded Domain-Specific Language,eDSL),指的是嵌套于主语言或系统内部的小型专用语言,通常用于配置、规则、任务定义等场景。它的特点包括:具备有限的语义能力(表达规则/条件/参数)嵌套于宿主系统中运行被工具链或引擎解析执行易读性高,非程序员也能上手YAML 的简洁结构和天然的键值/层级语义,使它非常适合承载这类嵌入式逻辑。
到底了