




- @2301_79239314
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文深入剖析 AI Agent(AI智能体) 记忆管理的生产级设计方案。从 Vector DB(向量数据库)的三大边界问题(精确查询失效、语义噪声污染、时间盲区)出发,提出平行记忆架构(精确通道 + 摘要通道 + Sliding Window(滑动窗口)),引入双时间戳状态管理(Valid Time(有效时间) + Transaction Time(记录时间))解决状态错乱,最后通过 Workfl
本文深入剖析 AI Agent(AI智能体) 记忆管理的生产级设计方案。从 Vector DB(向量数据库)的三大边界问题(精确查询失效、语义噪声污染、时间盲区)出发,提出平行记忆架构(精确通道 + 摘要通道 + Sliding Window(滑动窗口)),引入双时间戳状态管理(Valid Time(有效时间) + Transaction Time(记录时间))解决状态错乱,最后通过 Workfl
本文档介绍斯坦福大学 CS336《从零开始的语言模型》课程的 5 个作业内容及其作用,帮助学习者了解这门硬核实践课程的核心训练环节。

本文档详细解释神经网络中偏置(bias)的概念,涵盖数学定义(y=wx+b 中的 b)、几何意义(y 轴截距)、为什么需要偏置、PyTorch 代码示例对比带偏置与无偏置的区别,以及偏置在深度学习和现代大语言模型中的角色 🛠️
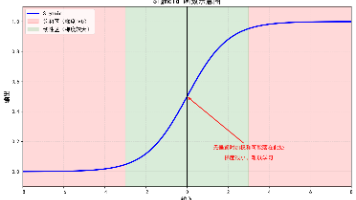
本文档详细解释层归一化(Layer Normalization, LayerNorm)的核心概念,涵盖数学定义、计算步骤、与 BatchNorm 的核心区别,以及 Transformer 选择 LayerNorm 的原因,最后提供 PyTorch 代码示例
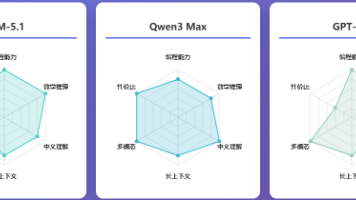
本文档基于 2026 年最新市场数据,从价格、模型能力、平台稳定性、合规性等多个维度,深度分析国内外主流大模型 API 调用平台的性价比表现,为个人开发者提供科学的选型指南
本文档深入解析 Pi Agent——一个由 Mario Zechner 开发的最小化编码 Agent,也是 OpenClaw(曾被称作 ClawdBot / MoltBot)的底层引擎。文章涵盖 Pi 的核心设计哲学、架构特点、与主流 AI 编码工具的对比,以及围绕它的社区争议和前景分析,帮助读者客观判断这一新兴工具的定位与价值。
高级Java工程师面试核心能力指南 摘要 本文针对高级Java工程师面试中的三大核心能力进行剖析: 线上问题排查 - 展示结构化分析流程,从链路追踪到JVM诊断(P99延迟/CPU飙升场景) 高并发架构设计 - 解析秒杀系统关键设计,涵盖限流/熔断/缓存一致性等核心技术 遗留系统重构 - 提出渐进式重构策略(绞杀者模式),平衡业务需求与技术债务 关键亮点 深度诊断工具链:集成SkyWalking

本文详细介绍了Python中的控制结构,包括条件语句和循环语句。主要内容涵盖: 条件语句:if-elif-else结构、逻辑运算符、三元运算符以及多条件判断示例 循环语句:for循环遍历列表和range()函数、while循环计数器、嵌套循环演示 循环控制:break跳出循环、continue跳过迭代、pass占位符的使用方法 实际应用:猜数字游戏、成绩统计和线性查找等实用案例 通过学习这些控制结

Python语言特性摘要 本文深入讲解了Python的核心语言特性,包括解释器、缩进规则和注释语法。主要内容: Python解释器:详细介绍了CPython标准实现和PyPy等替代方案的工作原理及性能特点 缩进规则:强调Python使用缩进表示代码块结构,必须保持一致性(推荐4个空格),避免混用空格和Tab 注释语法: 单行注释使用# 多行注释使用三引号 特殊注释标记如TODO、FIXME等 最佳
