SocioVerse是如何使用个人数据通过AI对个人建模的
SocioVerse 通过真实用户数据(千万级社交媒体数据)和大语言模型(多 LLM 协同标注与行为生成)的结合,实现了对个体的高精度建模。数据驱动的用户画像:从真实行为中提取多维特征。LLM 增强的行为模拟:通过提示工程和微调使虚拟个体生成人类化行为。多维度对齐框架:确保模拟环境、用户群体、交互行为与现实高度一致。这种方法为社会科学研究(如选举预测、舆情分析、经济调查)提供了可扩展、高保真的实验
·
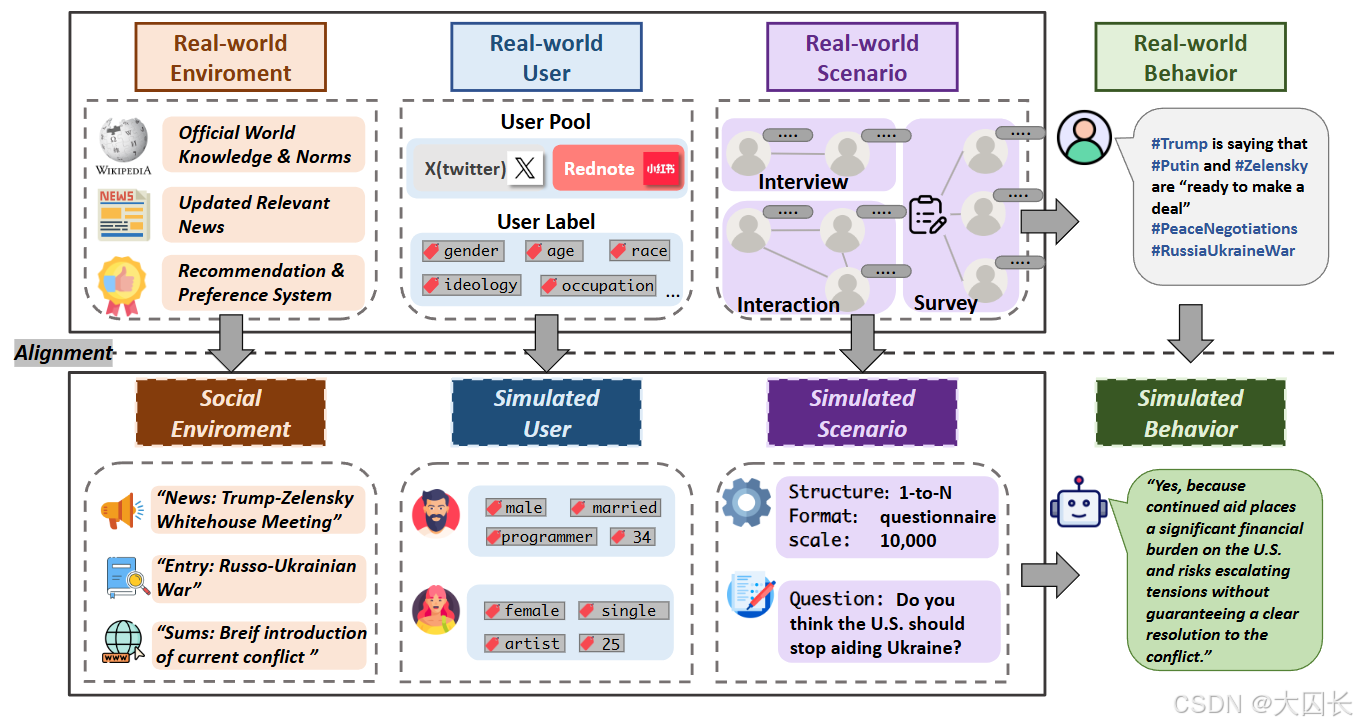
SocioVerse 通过整合大规模真实用户数据和大语言模型(LLM)的能力,实现了对社会模拟器中个体的高保真建模。其核心是通过数据驱动和模型增强的方法,构建具有真实人类特征和行为模式的虚拟个体(智能体)。
🔍 一、数据来源与处理
-
大规模真实用户池:
SocioVerse 从社交媒体平台(如 X/Twitter 和 Rednote/小红书)收集了超过 1000 万真实用户的公开数据,包括文本内容(发言、评论)、互动行为(点赞、转发)和基础元数据。- 数据清洗:通过文本相似度分析(阈值 >0.3)过滤机器人和广告账户,确保数据质量。
- 隐私保护:仅使用公开数据,并采用匿名化处理,避免直接暴露用户身份。
-
用户标签体系:
- 硬标签:包括年龄、性别、职业、收入、教育水平、地区等 15 类人口统计学属性。
- 软标签:通过语义分析提取政治倾向、消费偏好、价值观等深层特征。
- 标注流程:
- 多 LLM 协同标注:使用 GPT-4o、Claude 3.5、Gemini 1.5 等模型对用户初始标签进行生成。
- 人工校验:由标注员对 LLM 输出进行验证,一致性达 84.9% 以上。
- 训练分类器:用校验后的数据训练 Bert-base-chinese(中文)和 LongFormer(英文)分类器,实现大规模自动标注,准确率超 92%。
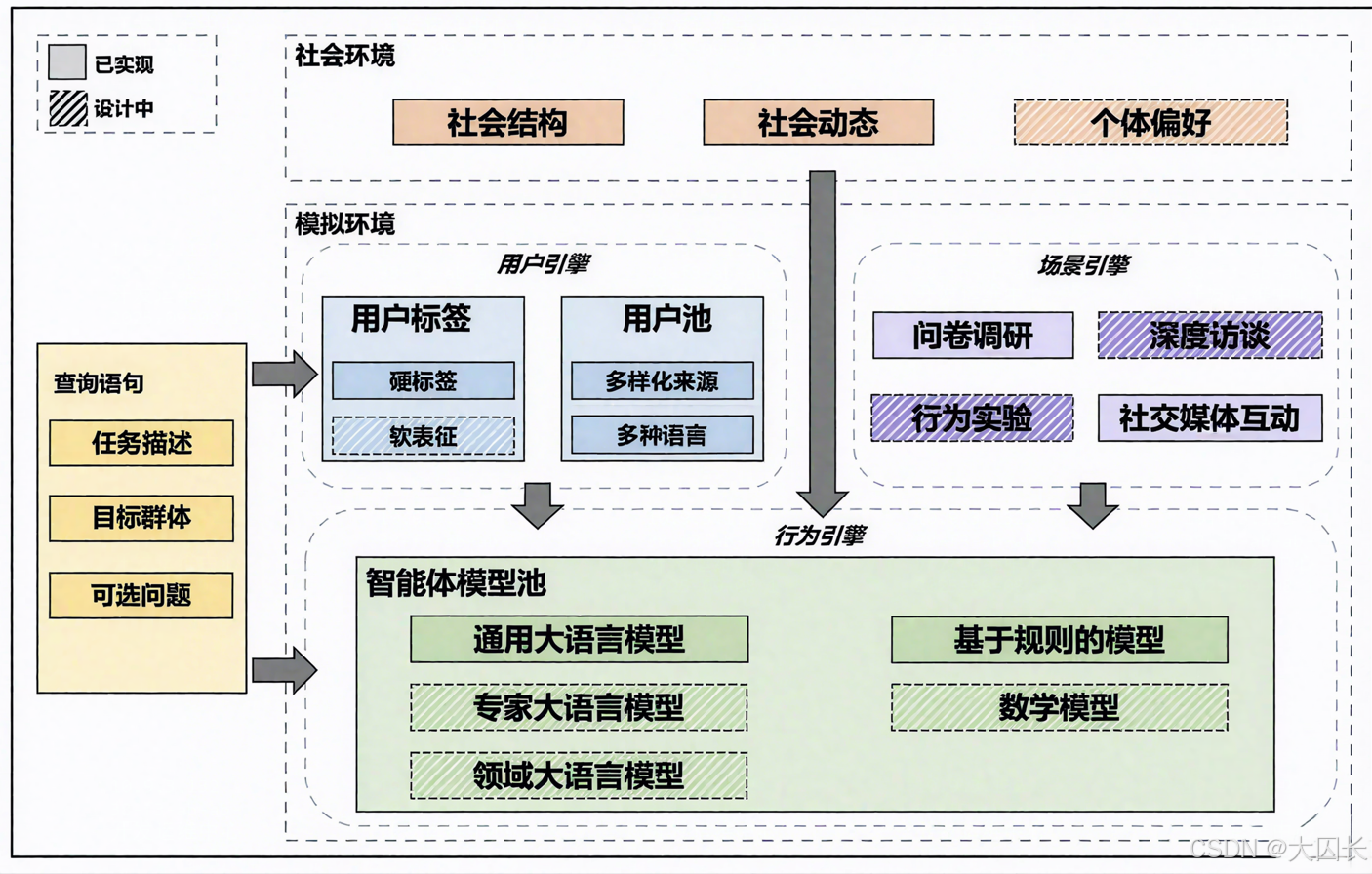
🧠 二、个体建模技术
-
用户引擎(User Engine):
- 从用户池中采样目标群体,构建虚拟个体的画像,包括:
- 静态属性:人口统计学特征(如年龄、性别)。
- 动态属性:兴趣偏好、社交关系、行为历史。
- 通过表征学习将用户编码为高维向量,保留其多维特征。
- 从用户池中采样目标群体,构建虚拟个体的画像,包括:
-
行为引擎(Behavior Engine):
- 双轨行为生成机制:
- LLM 智能体:
- 通用 LLM(如 GPT、Qwen):通过提示词注入用户画像,生成个性化行为(如发言、决策)。
- 专家 LLM:针对特定领域(如经济、政治)微调,用于专业场景。
- 传统代理模型(ABM):基于规则或数学理论处理简单行为(如投票、点赞),提高效率。
- LLM 智能体:
- 行为上下文整合:结合用户画像、实时事件(来自社会环境引擎)和场景规则(来自场景引擎),驱动智能体生成合理行为。
- 双轨行为生成机制:
⚙️ 三、模拟对齐与验证
SocioVerse 通过四大对齐模块确保模拟与现实的一致性:
- 环境对齐:注入实时事件和社会统计数据(如新闻、人口分布),使模拟环境动态更新。
- 用户对齐:通过真实用户池和标签体系,确保虚拟群体的分布与真实人口统计学一致(如地区、年龄)。
- 交互对齐:支持多种场景(问卷、访谈、社交互动),模拟现实社交结构。
- 行为对齐:通过 LLM 和 ABM 混合生成行为,使个体和群体行为符合真实模式。
验证结果:
- 选举预测:模拟美国大选,关键州误差低于 3.1%。
- 新闻反馈:模拟用户对 ChatGPT 新闻的态度,KL 散度仅 0.113(与真实分布高度一致)。
- 经济调查:模拟中国家庭支出,在发达地区误差 NRMSE 达 0.025。
📊 四、关键技术优势
| 技术特点 | 实现方式 | 作用 |
|---|---|---|
| 多源数据整合 | X + Rednote 用户数据(1000万+) | 提供多样化和大规模数据基础 |
| LLM+人工协同标注 | GPT-4o/Claude 标注 → 人工校验 → 分类器 | 高效准确标注用户属性 |
| 双轨行为生成 | LLM(复杂行为) + ABM(简单行为) | 平衡真实性与效率 |
| 动态环境更新 | 实时事件注入(新闻、统计数据) | 保持模拟与现实同步 |
⚠️ 五、隐私与伦理考虑
- 数据合规性:仅使用公开数据,过滤敏感信息,符合最小必要原则。
- 偏差控制:LLM 可能引入保守性偏差(如模拟回答偏中性),需通过人工校验和算法优化缓解。
💎 总结
SocioVerse 通过真实用户数据(千万级社交媒体数据)和大语言模型(多 LLM 协同标注与行为生成)的结合,实现了对个体的高精度建模。其核心创新在于:
- 数据驱动的用户画像:从真实行为中提取多维特征。
- LLM 增强的行为模拟:通过提示工程和微调使虚拟个体生成人类化行为。
- 多维度对齐框架:确保模拟环境、用户群体、交互行为与现实高度一致。
这种方法为社会科学研究(如选举预测、舆情分析、经济调查)提供了可扩展、高保真的实验平台。

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)