基于鲲鹏BRBE(Branch Record Buffer Extension)特性的性能分析与优化
鲲鹏平台的BRBE是一项硬件级别的分支记录技术,旨在提供低开销、高效率的代码执行路径捕获能力。它类似于x86架构中的LBR(Last Branch Record),为开发者提供了强大的性能分析与优化能力,它们的基本原则是相同的:硬件记录每个分支的from、to地址以及一些额外数据(例如时延)。具体来说,func1() → func2() → func3()显然是占用时钟周期最长的调用路线,其主要耗
鲲鹏平台的BRBE是一项硬件级别的分支记录技术,旨在提供低开销、高效率的代码执行路径捕获能力。它类似于x86架构中的LBR(Last Branch Record),为开发者提供了强大的性能分析与优化能力,它们的基本原则是相同的:硬件记录每个分支的from、to地址以及一些额外数据(例如时延)。
ARM平台的BRBE(Branch Record Buffer Extension)
BRBE是一个硬件实现的环形缓冲区,保存最近执行的 N 条分支记录。每条记录内容主要有:分支的源地址、分支的目标地址、分支类型、分支预测结果等,如图所示:
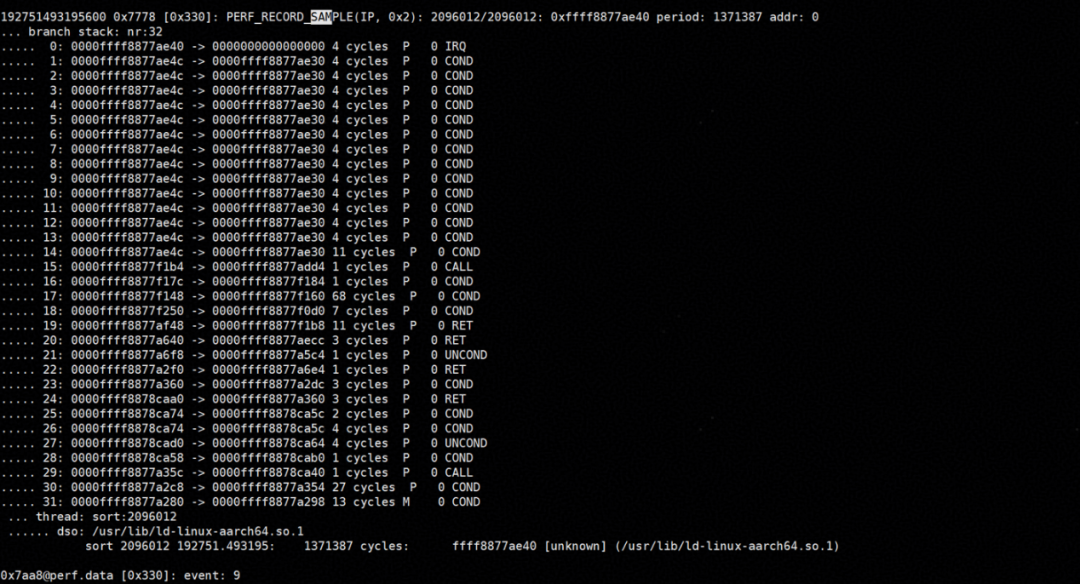
BRBE采集可以限制在一组特定的分支类型上,例如用户可以选择只记录函数调用和返回。用户还可以过滤条件跳转和无条件跳转、间接跳转和调用、系统调用、中断等。在perf中, -j 选项可以启用/禁用记录各种分支类型。如下图所示:
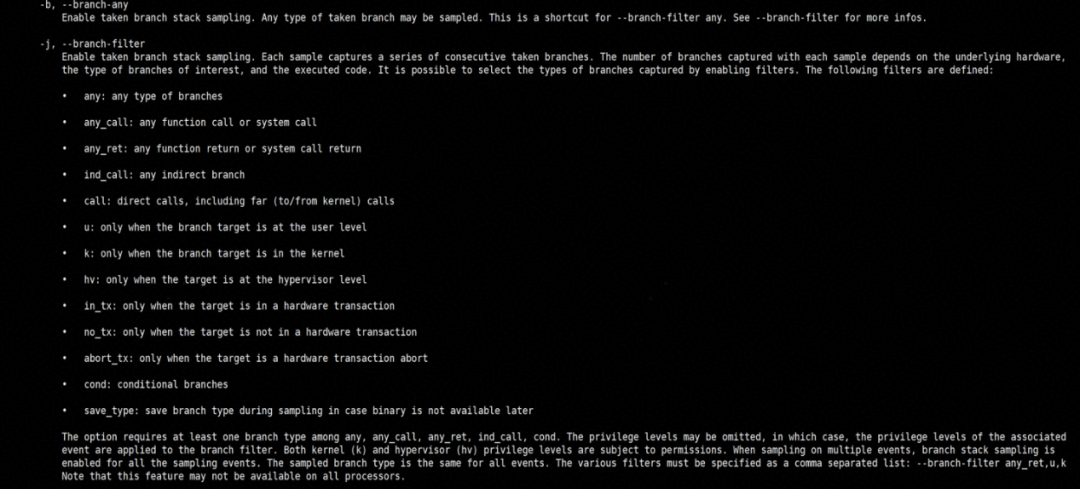
例如,一个典型的采样命令:
perf record -F 1000 -j u,any -e cycles -p 123456指定了采样频率、过滤器、采样事件、采样进程。
BRBE的应用
捕获调用栈
分支记录最广泛的应用之一是捕获调用堆栈。对于这样一个程序,可以通过BRBE采样获取调用栈信息:

通过如下几步:
g++ -g test.cpp -o testperf record --call-graph dwarf -- ./testperf report -n –stdio
可得到调用栈:
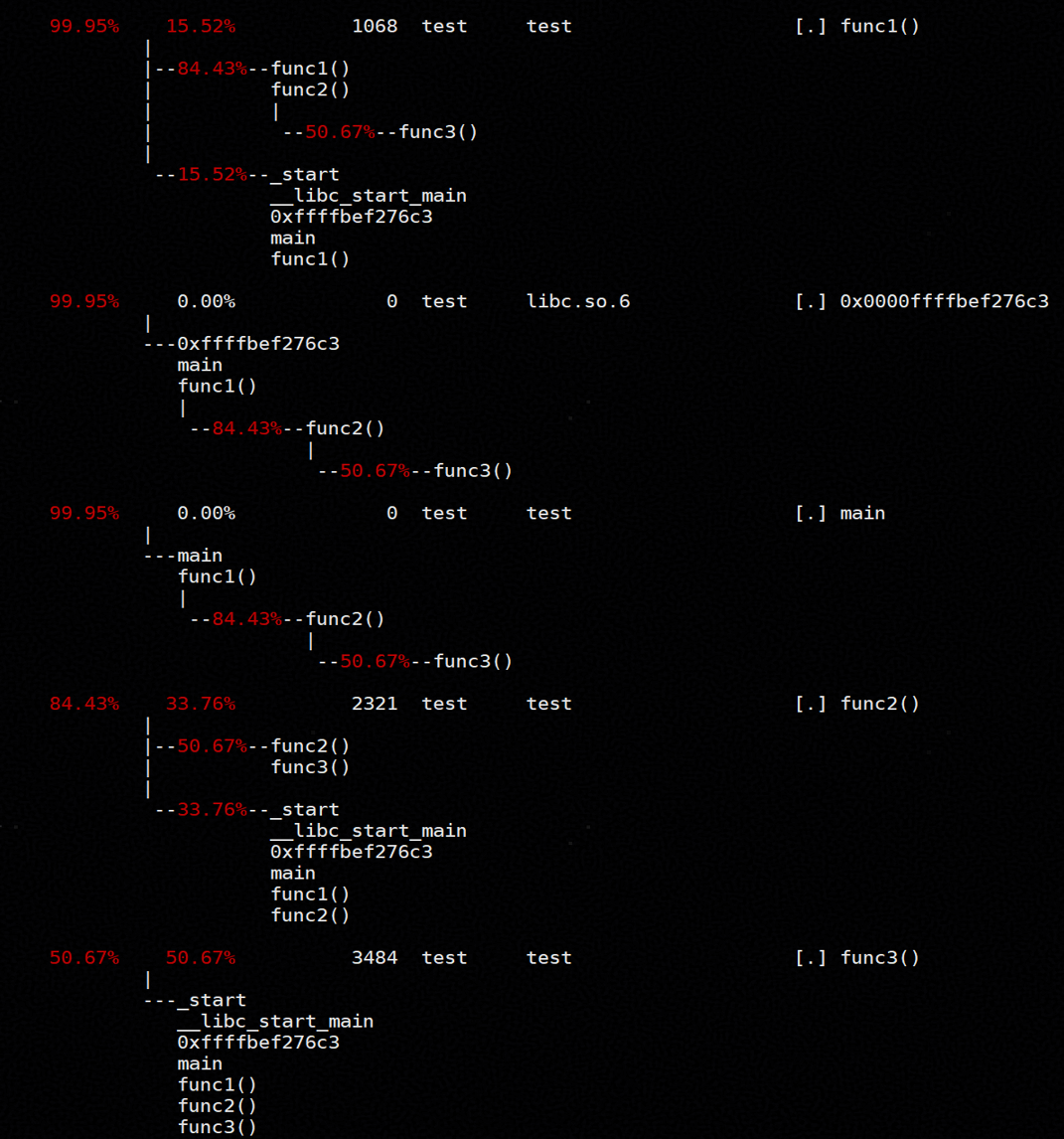
从上图可以看出各函数调用路线以及耗时占比。具体来说,func1() → func2() → func3()显然是占用时钟周期最长的调用路线,其主要耗时集中在 func3(),占比 50.67%,因此整条路线的性能瓶颈即为此处,符合程序本身的结构。对于更复杂的应用,也可以通过类似的方法进行分析。
识别热点分支
分支记录可以帮助识别哪些代码行占用CPU的比例更高。

g++ -g -O0 -o sort sort.cppperf record -e cycles -b --call-graph=dwarf -- ./sortperf report -n --sort overhead,srcline -F +dso,symbol –stdio
结果如图所示:
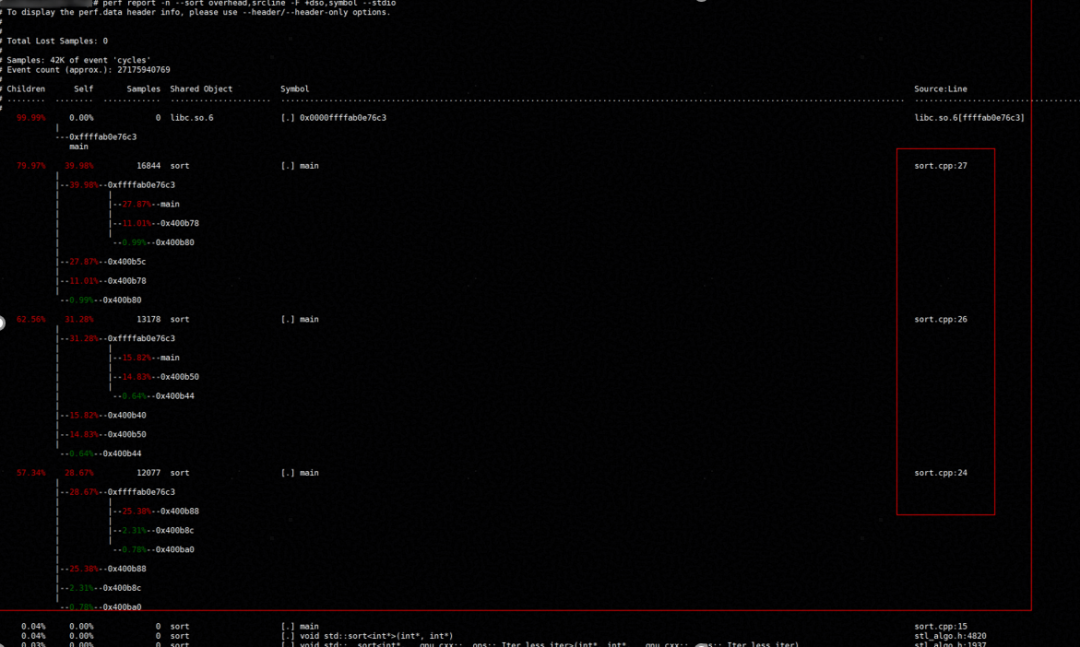
从上图可以看出性能消耗主要集中在24、26、27行,即程序的计算部分。
编译反馈优
BRBE数据经过处理后可用于反馈优化。例如,对于如下一个冒泡排序程序:

BRBE数据经过处理后可用于反馈优化:
(1) 安装autofdo:yum install autofdo.aarch64
(2) 编译原始代码: gcc -g -O3 sort.c -o sort
(3) 执行未优化的二进制文件10次,记录耗时
(4) 使用perf采集brbe,记录执行时的数据:perf record -e cycles -j any,save_type ./sort
(5) 生成gcov文件:create_gcov --binary=./sort
--profile=perf.data --gcov=sort.gcov gcov_version=2(6) 使用 AutoFDO 编译优化后的代码:gcc -O3 -fauto-profile=sort.gcov sort.c -o sort_autofdo
(7) 执行优化后的程序10次,对比优化前后程序耗时
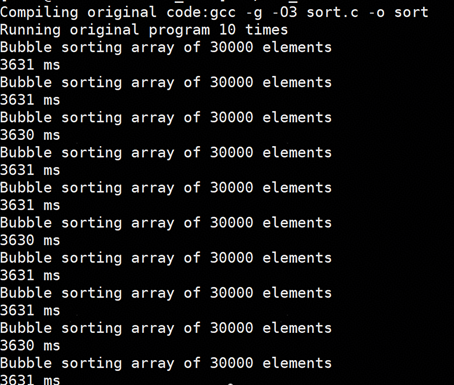
在本例中,sort.c的耗时显著降低。对于大型应用,也可以在编译时加入反馈优化选项,然后运行benchmark采集BRBE,再在二次编译时加入处理后的BRBE数据,以此优化应用的性能。
libkperf采集BRBE
libkperf是一个轻量级Linux性能采集库,它能够让开发者以API的方式执行性能采集,包括pmu采样和符号解析。libkperf把采集数据内存化,使开发者能够在内存中直接处理采集数据,避免了读写perf.data带来的开销。
libkperf的开源地址:
https://gitee.com/openeuler/libkperf
编译生成动态库和C的API:
git clone --recurse-submodules https://gitee.com/openeuler/libkperf.gitcd libkperfbash build.sh install_path=/path/to/install
libkperf提供了采集BRBE的能力,例如:

其中branchSampleFilter定义了过滤器,含义与perf record中的-j参数相同。
执行上述代码,输出的结果类似如下:
ffff88f6065c->ffff88f60b0c 35 Pffff88f60aa0->ffff88f60618 1 P40065c->ffff88f60b00 1 P400824->400650 1 P400838->400804 1 P
结果展示了分支跳转的起始地址、周期数、预测标志位。
总结:BRBE可以实现精准的性能profiling与热点发现
填补调用栈空缺:
在鲲鹏平台上,传统的基于帧指针(Frame Pointer)或DWARF调试信息的调用栈回溯方法,因依赖编译器选项(如 -fno-omit-frame-pointer)和调试信息,在一些高性能场景下可能不够精准或开销较大。BRBE直接从硬件层面记录分支历史,为重建调用链提供了坚实的数据基础,并能与eBPF等技术结合,实现更高效的性能数据收集。
硬件级低开销:
BRBE的设计目标之一就是“低计算和低内存开销”。这使得它非常适合在生产环境中持续进行性能监控,而不会对业务性能造成明显影响。
深度优化指导:
结合perf与libkperf等工具,BRBE收集到的精确分支信息可以帮助开发者:识别出程序中最频繁执行的热点代码路径;分析分支预测失败的原因;进行PGO优化,生成最优的机器代码。

加入「COC·上海城市开发者社区」,成就更好的自己!
更多推荐



 4
4 0
0- 0



 已为社区贡献1066条内容
已为社区贡献1066条内容

所有评论(0)