
为什么这段代码会阻塞?
作者 | 马健尧出品 | 腾讯云开发者腾讯内网上,一位提问者对一段代码为什么会阻塞发出了疑问,该问题讨论跨度约一周,探讨过程中,出现了许多由于不够理解 channel 而产生的问题,非常经典。本文结合内网上的讨论和 channel 的原理,来帮助大家加深对于 channel 的理解。故事开始的地方——这段代码为什么会阻塞?开始,题主提出了这样一个问题:func main() {...

作者 | 马健尧
出品 | 腾讯云开发者
腾讯内网上,一位提问者对一段代码为什么会阻塞发出了疑问,该问题讨论跨度约一周,探讨过程中,出现了许多由于不够理解 channel 而产生的问题,非常经典。本文结合内网上的讨论和 channel 的原理,来帮助大家加深对于 channel 的理解。

故事开始的地方——这段代码为什么会阻塞?
开始,题主提出了这样一个问题:

func main() {
testContinue()
}
func testContinue() {
in := make(chan *Content, 20)
audit := make(chan *Content, 20)
streamTextPreProcessStop := make(chan struct{})
// 向in协程无脑放2000个数据
go func() {
for i := 0; i < 2000; i++ {
in <- &Content{
i: i,
}
log.Infof("put in content = %s", strconv.Itoa(i))
}
}()
// 异步审核流程,在第三十条的时候触发审核失败
go func() {
for {
select {
case content, ok := <-audit:
if !ok {
log.Infof("audit get in not ok")
}
time.Sleep(30 * time.Millisecond)
if content.i == 30 {
log.Infof("audit streamTextPreProcessStop before")
streamTextPreProcessStop <- struct{}{}
log.Infof("audit streamTextPreProcessStop after")
}
}
}
}()
for {
select {
case <-streamTextPreProcessStop:
log.Infof("get streamTextPreProcessStop")
waitTimes := 0
for {
if waitTimes > 50 {
break
}
waitTimes++
time.Sleep(100 * time.Millisecond)
}
continue
case content, ok := <-in:
if !ok {
log.Infof("get in not ok")
}
log.Infof("get in content = %s", strconv.Itoa(content.i))
log.Infof("audit in before content = %s", strconv.Itoa(content.i))
audit <- content
log.Infof("audit in after content = %s", strconv.Itoa(content.i))
}
}
}让我们来拆解一下这段代码的大致逻辑:
1. 定义了三个通道,两个有缓冲,一个无缓冲
-
-
in:一个缓冲区大小为20的通道,用于存放待处理的数据。 -
audit:一个缓冲区大小为20的通道,用于存放待审核的数据。 -
streamTextPreProcessStop:一个无缓冲的通道,用于通知审核失败的情况。
-
in := make(chan *Content, 20)
audit := make(chan *Content, 20)
streamTextPreProcessStop := make(chan struct{})2. 这段代码开启了一个 goroutine,这个goroutine会向 in 通道中放入2000个 Content 对象,每个对象的 i 字段从0到1999。每放入一个对象都会记录日志。
go func() {
for i := 0; i < 2000; i++ {
in <- &Content{
i: i,
}
log.Infof("put in content = %s", strconv.Itoa(i))
}
}()3. 又开启了一个 goroutine,这个 goroutine 从 audit 通道中读取数据,并模拟审核过程。每次读取一个数据后会等待30毫秒。如果读取到的 Content 对象的 i 字段为30,则向 streamTextPreProcessStop 通道发送一个空结构体,表示审核失败。
go func() {
for {
select {
case content, ok := <-audit:
if !ok {
log.Infof("audit get in not ok")
}
time.Sleep(30 * time.Millisecond)
if content.i == 30 {
log.Infof("audit streamTextPreProcessStop before")
streamTextPreProcessStop <- struct{}{}
log.Infof("audit streamTextPreProcessStop after")
}
}
}
}()4. 主循环,其中 select 监听两个case:
-
-
如果从 streamTextPreProcessStop 通道中接收到数据,表示审核失败。此时会记录日志并等待5秒(50次,每次100毫秒),然后继续循环。
-
如果从 in 通道中接收到数据,则将数据放入 audit 通道,并记录相关日志。
-
for {
select {
case <-streamTextPreProcessStop:
log.Infof("get streamTextPreProcessStop")
waitTimes := 0
for {
if waitTimes > 50 {
break
}
waitTimes++
time.Sleep(100 * time.Millisecond)
}
continue
case content, ok := <-in:
if !ok {
log.Infof("get in not ok")
}
log.Infof("get in content = %s", strconv.Itoa(content.i))
log.Infof("audit in before content = %s", strconv.Itoa(content.i))
audit <- content
log.Infof("audit in after content = %s", strconv.Itoa(content.i))
}
}到这里可以看出来:这个程序模拟了一个数据流处理和审核的过程。
-
数据首先被放入
in通道,然后被主循环读取并放入audit通道。 -
审核 goroutine 从
audit通道中读取数据,并在i等于30的时候,向streamTextPreProcessStop通道发送信号,通知审核失败。 -
主循环在接收到审核失败信号后,会等待一段时间,然后继续处理后续数据。
你看出来这段代码为什么会阻塞了吗?
这个问题在内网引发了广泛的讨论,问题的根本原因在于,很多技术同学其实没有完全掌握以下三个东西:
-
无缓冲通道的特性;
-
channel 的阻塞什么时候会发生;
-
select 的特性。
解决完这三个问题之后,阻塞分析就迎刃而解了。

三个问题
2.1 无缓冲 channel
我们首先要明确一个概念,无缓冲 channel,意味着它没有任何存储空间,只做「传输」的作用,所以它也叫 同步 channel ,一个基于无缓存通道的发送操作将导致发送者 goroutine 阻塞, 直到 另一个 goroutine 在相同的通道上执行接收操作,当发送的值通过通道成功传输之后,两个 goroutine 可以继续执行后面的语句。反之,如果接收操作先发生,那么接收者 goroutine 也将阻塞, 直到 有另一个 goroutine 在相同的通道上执行发送操作。
英文论述中,有一个画面感很强的句子,是这样的:当通过一个无缓冲通道发送数据时,接收者收到数据发生在再次唤醒发送者 goroutine 之前 (happens before)
由此,我们可以证明,「streamTextPreProcessStop 应该可以不阻塞的往里放一个数据的」,这句话是错误的。无缓冲通道,要求发送者和接受者同时准备好,才能够传输,否则就会阻塞,因为它本身没有存储的空间。
2.2 channel 何时阻塞
更进一步的,我们可以了解下 channel 在什么时候才会阻塞,我认为可以用一句话概括:写不进,读不出 。
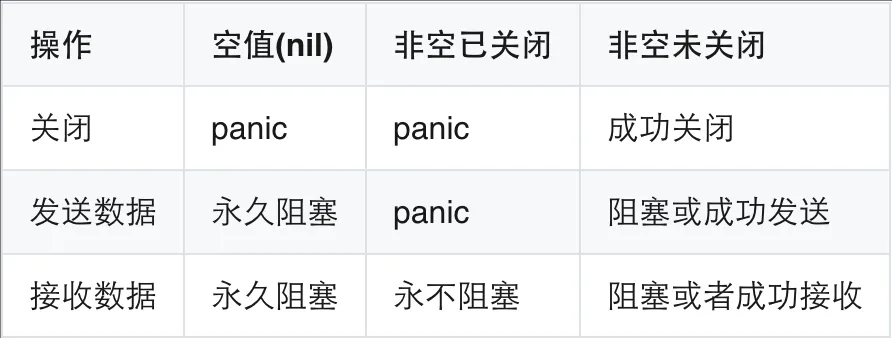
图中是 channel 的三种状态,以及这三种状态下对其的三种操作结果。我们目前只用关注「非空未关闭」的状态,可以看到,都是阻塞或成功接收/发送。管道是一个生产消费的队列,管道的阻塞,就相当于一端堵住了,导致队列无法往前推进。提问者有一句话比较有意思,我们可以展开讨论:「每个管道都有消费的逻辑,只是进出比出水快而已,出水慢慢的一定能出完」,这话对,也不对。
-
对于 channel 的概念,这话是对的,是的,不管是有缓冲通道还是无缓冲通道,只要一端在生产,一端在消费,不管哪一方快,都能够顺利的进行下去。
-
对于上文的代码实现,这话不对,因为 select 每次只会执行一个 case,并且在某个 case 阻塞时,是不会执行其它 case 的。
2.3 select 的特性
select也能够让 goroutine 同时等待多个channel可读或者可写,在channel状态改变之前,select 会一直阻塞当前线程或者 goroutine。select是与switch相似的控制结构,与switch不同的是,select中虽然也有多个case,但是这些case中的表达式必须都是channel的收发操作。当select中的两个case同时被触发时,会随机执行其中的一个。
从 select 的定义中,我们可以得知,当 select 阻塞在一个 case 时,要是 channel 的状态没有变化,则会一直阻塞。到这里,代码阻塞的原因已经全部提到了,我们来结合代码讲一讲:
1. 首先,开启的第一个 goroutine 会持续向 in channel 中生产数据
go func() {
for i := 0; i < 2000; i++ {
in <- &Content{
i: i,
}
}
}()2. 接着,主循环中的 select 会消费数据,并写入 audit 这个 Channel
for {
select {
case <-streamTextPreProcessStop:
...
...
case content, ok := <-in:
...
audit <- content
...
}
}3. 开启的第二个 goroutine 会消费 audit 中的数据
go func() {
for {
select {
case content, ok := <-audit:
if !ok {
log.Infof("audit get in not ok")
}
time.Sleep(30 * time.Millisecond)
if content.i == 30 {
streamTextPreProcessStop <- struct{}{}
}
}
}
}()有了前面的铺垫,是不是很容易就发现问题所在?那就是 streamTextPreProcessStop <- struct{}{} 往无缓冲通道生产数据的时候,消费者没有准备好。既然第一个 goroutine 会持续往 in channel 写入数据,主循环中的 select 一接收到 in 中的数据,便会往 audit 中写,那么开启的第二个 goroutine 中,time.Sleep(30 * time.Millisecond) 就成了一个很致命的问题——在等待的这段时间内,主循环依然在消费in channel 的数据,消费者没有准备好接收 streamTextPreProcessStop 这个 channel 的数据,那么第二个 goroutine 的 select 就会死锁,无法消费 audit 中的数据,进一步导致 audit 的死锁。
解决方法很简单,其实只需要更改一下 streamTextPreProcessStop,将其改为有缓冲通道即可:streamTextPreProcessStop := make(chan struct{}, 1)

channel
接下来,我们简要讲讲 channel 的核心特性和底层原理,作为 Golang 中的核心数据结构,掌握好会对我们的开发工作起到事半功倍的效果。
3.1 从 CSP 开始
-
CSP 经常被认为是 Go 在并发编程上成功的关键因素。CSP 全称是 “Communicating Sequential Processes”,这也是 Tony Hoare 在 1978 年发表在 ACM 的一篇论文。论文里指出一门编程语言应该重视 input 和 output 的原语,尤其是并发编程的代码。
-
在文章中,CSP 也是一门自定义的编程语言,作者定义了输入输出语句,用于 processes 间的通信(communication)。processes 被认为是需要输入驱动,并且产生输出,供其他 processes 消费,processes 可以是进程、线程、甚至是代码块。输入命令是:!,用来向 processes 写入;输出是:?,用来从 processes 读出。这篇文章要讲的 channel 正是借鉴了这一设计。
-
Hoare 还提出了一个 -> 命令,如果 -> 左边的语句返回 false,那它右边的语句就不会执行。通过这些输入输出命令,Hoare 证明了如果一门编程语言中把 processes 间的通信看得第一等重要,那么并发编程的问题就会变得简单。
Go 是第一个将 CSP 的这些思想引入,并且发扬光大的语言。尽管内存同步访问控制在某些情况下很有用处,Go 里也有相应的 sync 包支持,但是这在大型程序很容易出错。Go 一开始就把 CSP 的思想融入到语言的核心里,所以并发编程成为 Go 的一个独特的优势,而且很容易理解。多数的编程语言的并发编程模型是 基于线程和内存同步访问控制 ,Go 的并发编程的模型则用 goroutine 和 channel 来替代。goroutine 和线程类似,channel 和 mutex 类似。
goroutine 解放了程序员,让我们更能贴近业务去思考问题。而不用考虑各种像线程库、线程开销、线程调度等等这些繁琐的底层问题。channel 则天生就可以和其他 channel 组合。我们可以把收集各种子系统结果的 channel 输入到同一个 channel。channel 还可以和 select, cancel, timeout 结合起来。而 mutex 就没有这些功能。
Go 的并发原则非常优秀,目标就是简单:尽量使用 channel;把 goroutine 当作免费的资源,随便用。(不过也有人对这个看法表示质疑,甚至后来 Go 语言的官方团队也表示,他们在某些场景中过度使用 goroutine 了,我们需要审视到底有没有必要使用它)
3.2 channel 数据读写
-
通道没有缓冲区时,从通道读取数据会阻塞,直到有协程向通道写入数据。类似的,向通道写入数据也会阻塞,直到有协程从通道读取数据。
-
通道有缓冲区时,从通道读取数据,如果缓冲区没有数据也会阻塞,直到有协程写入数据。类似的,向通道写入数据时,如果缓冲区已满,也会阻塞,直到有协程从缓冲区中读出数据。
-
对于值为 nil 的通道,无论读写都会阻塞,而且是永久阻塞。
-
使用内置函数
close()可以关闭通道,尝试向关闭的通道中写入数据会触发 panic,但关闭的通道仍然可以读。
通道的读取表达式如下:
value := <-ch
value, ok := <-ch第一个变量表示独处的数据,第二个变量(bool类型)表示是否成功读取了数据,注意,第二个变量不用于指示 通道的关闭状态 。第二个变量经常被误解为通道的关闭状态,虽然说有关系,但是严谨的说,第二个变量和 通道中是否有数据 有关。一个已经关闭的通道有两种情况:
-
通道缓冲区已经没有数据了。
-
通道缓冲区还有数据。
对于第一种情况,通道已经关闭,而且缓冲区中没有数据,那么通道读取表达式返回的第一个变量为相应的零值,第二个变量为 false;对于第二种情况,通道已经关闭但是缓冲区还有数据,那么通道读取表达式返回的第一个变量为读取到的数据,第二个变量为 true。
所以,只有 通道已经关闭,且缓冲区中没有数据的时候 ,通道读取表达式返回的第二个变量才与通道关闭状态一致。
3.3 channel 底层原理
源码包 src/runtime/chan.go:hchan 定义了 channel 的数据结构:
type hchan struct {
qcount uint // 当前队列中剩余的元素个数
dataqsiz uint // 环形队列长度,即可以存放的元素个数
buf unsafe.Pointer // 环形队列指针
elemsize uint16 // 每个元素的大小
closed uint32 // 标识关闭状态
elemtype *_type // 元素类型
sendx uint // 队列下标,指示元素写入时存放到队列中的位置
recvx uint // 队列下标,指示下一个被读取元素在队列中的位置
recvq waitq // 等待读消息的协程队列
sendq waitq // 等待读消息的协程队列
lock mutex // 互斥锁,chan 不允许并发读写
}1. 环形队列:Channel 内部实现了一个环形队列作为其缓冲区,队列的长度是创建 chan 时指定的。
-
-
这是一个可以缓存6个元素的
Channel:-
dataqsiz 表示队列长度为6,也就是可以缓存6个元素。
-
buf 指向队列的内存。
-
qcount 表示队列中还有两个元素。
-
sendx 和 recvx 分别表示队尾和队首,sendx 表示数据写入位置,recvx 表示数据读取位置。
-
-
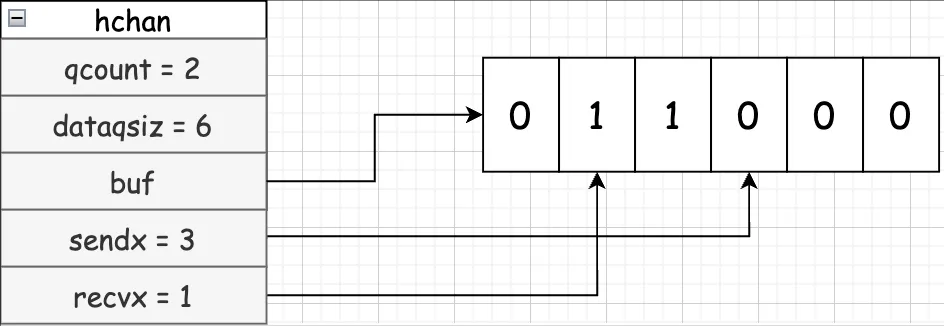
2. 等待队列
-
-
从
channel读取数据时,如果channel缓冲区为空或者没有缓冲区,则当前协程会被阻塞,并被加入 recvq 队列。向通道写数据时,如果通道缓冲区已满或者没有缓冲区,则当前协程会被阻塞,并被加入 sendq 队列。 -
这是一个没有缓冲区的通道,有几个协程阻塞等待读数据:
-
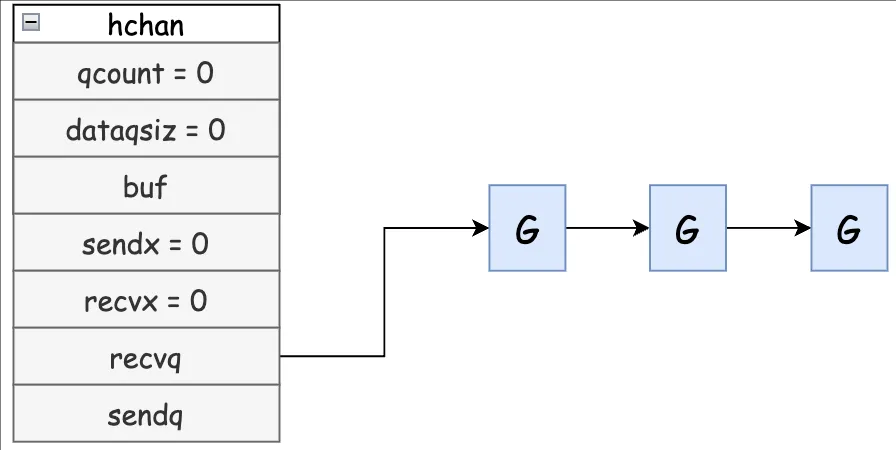
处于等待队列中的协程,会在其他协程操作通道时被唤醒:
-
-
因读阻塞的协程会被向通道写数据的协程唤醒。
-
因写阻塞的协程会被从通道读数据的协程唤醒。
-
注意:一般不会出现 recvq 和 snedq 中同时有协程排队的情况,只有一个例外,就是同一个协程中使用 select 语句向通道一边写数据,一边读数据,此时协程会分别位于两个等待队列中。
3. 类型信息
-
-
一个通道只能传递一种类型的值,类型信息存储在 hchan 数据结构中:
-
elemtype 代表类型,用于数据传递过程中赋值。
-
elemsize 代表类型大小,用于在 buf 中定位元素位置。
-
如果需要通道传递任意类型的数据,则可以使用
interface{}类型。
-
-
4. 互斥锁
-
-
一个通道同一时刻只允许被一个协程读写,所以我们会说 channel 是 并发安全 的。
-
3.4 channel 收发消息的本质
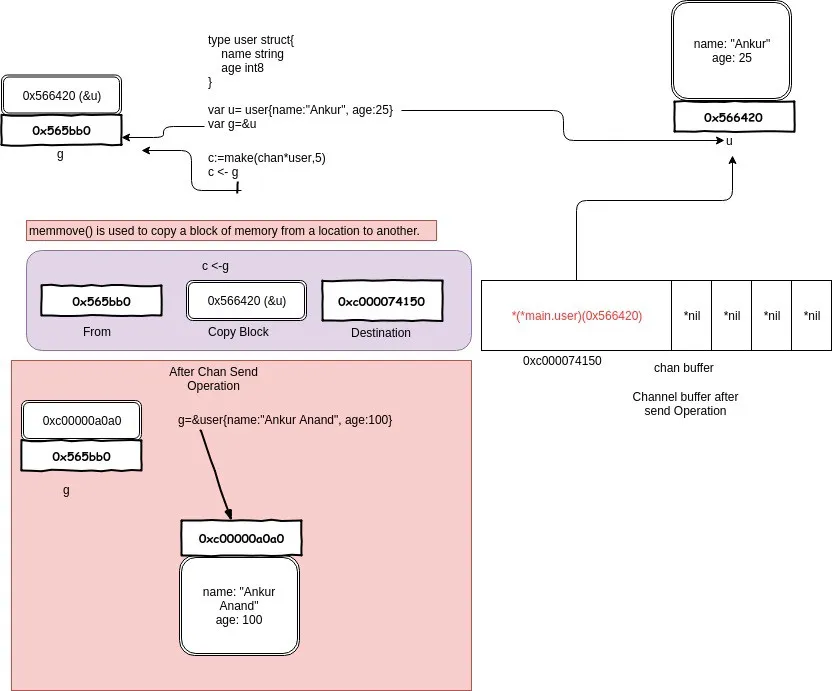
channel 的发送和接收操作本质上都是 “值的拷贝”,无论是从 sender goroutine 的栈到 chan buf,还是从 chan buf 到 receiver goroutine,或者是直接从 sender goroutine 到 receiver goroutine。
如图所示,一开始构造一个结构体 u,地址是 0x56420,然后把 &u 赋值给指针 g,g 的地址是 0x565bb0,它的内容就是一个地址,指向 u。main 程序里,先把 g 发送到 c,根据 copy value 的本质,进入到 chan buf 里的就是 0x56420,它是指针 g 的 值 ,而不是它指向的内容,所以打印从 channel 接收到的元素时,它就是 &{Ankur 25}。这就说明了 channel 传递数据并不是将指针 g “发送” 到了 channel 里,只是拷贝它的值而已。
3.5 channel 带来的资源泄漏
泄漏的原因是 goroutine 操作 channel 后,处于发送或接收阻塞状态,而 channel 处于满或空的状态,一直得不到改变。根据 GMP 的三色标记回收法,不会回收此类资源,进而导致 gouroutine 会一直处于等待队列中,这样一来就会导致 资源泄漏 。所更进一步的,我们可以理解为 channel 容易导致 goroutine 阻塞,进而带来资源泄漏。
3.6 channel 关闭时需要注意
don't close a channel from the receiver side and don't close a channel if the channel has multiple concurrent senders.
这是关闭 channel 的原则:不要从一个 receiver 侧关闭 channel,也不要在有多个 sender 时,关闭 channel。可以这么想:向 channel 发送元素的就是 sender,因此 sender 可以决定何时不发送数据,并且关闭 channel,而 receiver 不知道数据何时停止生产,所以不应该从一个 receiver 侧关闭。但是如果有多个 sender,某个 sender 同样没法确定其他 sender 的情况,这时也不能贸然关闭 channel。

加餐
4.1 无缓冲通道的使用
这是一段笔者最近写的生产和消费邮件数据的代码,注意到 errCh 是个无缓冲通道,合理的安排 wg.Wait() 和 close(errCh) 的时机,能够保证无缓冲通道的消费和关闭在我的预期之中进行。
func (d *DailyMailScheduler) ProcessMail(ctx context.Context, mp mailProcessor) error {
var wg sync.WaitGroup
singleInfoCh := make(chan any, 5)
errCh := make(chan error)
wg.Add(1)
go func() {
defer func() {
wg.Done()
close(singleInfoCh)
log.InfoContextf(ctx, "邮件数据收集完毕,协程退出")
}()
err := mp.collectMailData(ctx, singleInfoCh)
if err != nil {
log.ErrorContextf(ctx, "邮件数据收集错误: %v", err)
errCh <- err
}
}()
for singleInfo := range singleInfoCh {
wg.Add(1)
go func(singleInfo any) {
defer func() {
wg.Done()
}()
err := mp.buildAndSendMail(ctx, singleInfo)
if err != nil {
log.ErrorContextf(ctx, "构建和发送邮件失败: %v", err)
errCh <- err
}
}(singleInfo)
}
go func() {
wg.Wait()
close(errCh)
}()
var result error
for err := range errCh {
result = multierror.Append(result, err)
}
return result
}如果 wg.Wait() 不放在 goroutine 中执行,放在 for err := range errCh 之前,会因为消费被阻塞,导致无缓冲通道死锁。如果放在 for err := range errCh 之后,由于通道没有关闭,for循环会一直执行下去,同样导致死锁。而上面的逻辑,能够合理的控制无缓冲通道 errCh 的开启和关闭。同时,singleInfoCh 的关闭遵循了 channel 的实践,由生产者来决定 channel 的关闭。
PS: 上面的将 wg.Wait() 放在 goroutine 中执行,并利用 multierror 来合并返回错误,是我比较喜欢的并发编程错误处理方式。还有如 errgroup、errors 等处理方式,读者可以自行了解。更为深入的 channel 原理,读者可以也参考一些较为权威和官方的教程。
本文引用网上的帖子,因为讨论很热情,暴露出了许多人对于 channel 的理解误区,也正是因为大家的思维碰撞,才能给我们一个好的教材。
4.2 参考文章
-
https://codeburst.io/diving-deep-into-the-golang-channels-549fd4ed21a8
-
https://geektutu.com/post/hpg-exit-goroutine.html
-
《Go专家编程》
-
《深入理解Go并发编程》
本文经授权转载腾讯云开发者,如需转载,请联系👇


加入「COC·上海城市开发者社区」,成就更好的自己!
更多推荐



 13
13 0
0- 0



 已为社区贡献640条内容
已为社区贡献640条内容

所有评论(0)