使用甜甜圈理解无 OCR 文档
使用最近发布的 Transformers 模型生成文档数据的 JSON 表示

照片由 Romain Dancre 在Unsplash
视觉文档理解 (VDU) 是深度学习和数据科学中一个经过大量研究的新领域,特别是因为 PDF 或文档扫描中有大量非结构化数据。最近的模型,例如LayoutLM,利用变换器深度学习模型架构来标记单词或根据文档图像回答给定问题(例如,您可以通过注释来突出显示和标记帐号图像本身,或询问模型,“帐号是什么?”)。 HuggingFace 的zwz100022 transformers zwz100023 zwz100021等库可以更轻松地使用开源转换器模型。
VDU 问题的大多数传统答案都依赖于解析该图像的 OCR 输出以及视觉编码,但 OCR 的计算成本很高(因为它通常需要安装像 Tesseract 这样的 OCR 引擎)并且在其中包含另一个模型完整的管道会导致另一个必须训练和微调的模型——不准确的 OCR 模型将导致 VDU 模型中的错误传播。
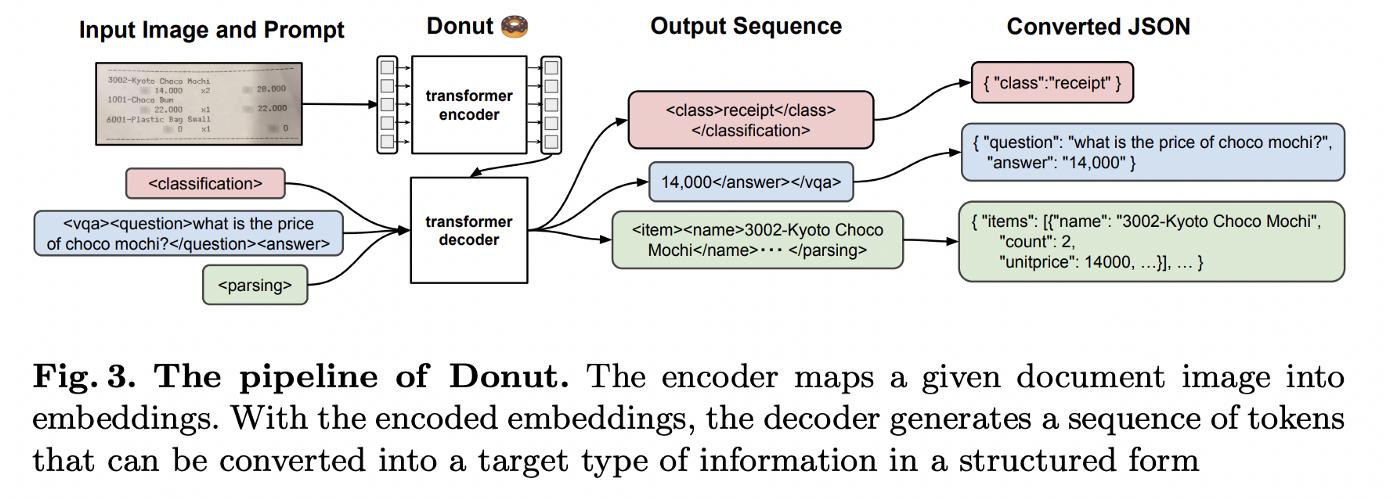
因此,来自Naver CLOVA的研究人员提出了一种端到端 VDU 解决方案[1],该解决方案使用编码器-解码器转换器模型架构,并且 最近使其可用于和(https://github.com/clovaai/donut).换句话说,它将图像(使用 Swin Transformer 分割成块)encodes 成标记向量,然后它可以_decode、_ 或翻译成数据结构形式的输出序列(然后可以进一步解析成 JSON)使用在多语言数据集上公开预训练的 BART 解码器模型。在推理时输入模型的任何提示也可以在相同的架构中进行解码。
图片由 Donut 的作者提供(MIT 许可)
您可以在CORD 收据数据集此处查看对甜甜圈进行微调的演示。他们提供了一个示例收据图像进行试用,但您也可以在许多其他文档图像上进行测试。当我在这张图片上测试它时:

图片由 Donut 的作者提供
我得到了结果:
{
nm:“演示文稿”
}
这表明它检测到“演示文稿”标题是菜单或收据上的项目名称。
作者还提供了培训和测试脚本,因此我们可以演示如何在实践中实际使用这些模型(我将使用SROIE 数据集[2],一个带标签的收据和发票的数据集,来演示对自定义数据集进行微调)。我建议在 GPU 上运行代码,因为推理和训练都需要在 CPU 上花费相当长的时间。 Google Colab 提供免费的 GPU 访问,应该足以进行微调(转到 Runtime > Change runtime type 以从 CPU 切换到 GPU)。
首先,让我们确保我们有 GPU 访问权限。
进口火炬
print("CUDA 可用:", torch.cuda.is_available())
!nvcc --版本
现在我们可以下载相关的文件和库了。以下代码行应该安装所有依赖项,包括甜甜圈库(尽管您可以使用pip install donut-python手动安装它,从 Github 克隆的代码库包括重要的培训和测试脚本)。
!git 克隆https://github.com/clovaai/donut.git
!cd 甜甜圈 && 点安装。
使用 CORD 微调模型进行推理
首先,我们将演示模型的基本用法。
从甜甜圈进口甜甜圈模型
从 PIL 导入图像
导入 torchmodel u003d DonutModel.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
如果 torch.cuda.is_available():
模型.half()
设备 u003d torch.device("cuda")
模型.to(设备)
别的:
model.encoder.to(torch.bfloat16)
model.eval() image u003d Image.open("./donut/misc/sample_image_cord_test_receipt_00004.png")
.convert("RGB")
输出 u003d model.inference(imageu003dimage, promptu003d"<s_cord-v2>")
输出
在DonutModel.from_pretrained()调用中,我只是简单地指定了来自 HuggingFace Hub 的预训练模型的名称(此时下载了必要的文件),但我也可以指定模型文件夹的本地路径,稍后我们将演示. Donut 代码库还包括一个示例图像(如下所示),这是我传递给模型的内容,但您可以使用任何您喜欢的图像来测试模型。

Donut作者提供的收据样本图片
你应该得到一个像
{'predictions': [{'menu': [{'cnt': '2', 'nm': 'ICE BLAOKCOFFE', 'price': '82,000'},
{'cnt': '1', 'nm': 'AVOCADO COFFEE', 'price': '61,000'},
{'ct': '1', 'mm': 'o d chinen katsuf', 'prise': '51, 000'}",
'sub_total': {'discount_price': '19,400', 'subtotal_price': '194,000'},
'total': {'cashprice': '200,000',
'changeprice': '25,400',
'total_price': '174,600'}}]}
(注意:如果你和我一样好奇,想知道预训练的donut-base主干会给你什么输出,我继续测试它。在崩溃之前需要很长时间才能产生输出,因为它占用了太多的 RAM。 )
在自定义数据集上微调甜甜圈
为了演示微调,我将使用 SROIE 数据集,这是一个收据和发票扫描数据集,以及 JSON 形式的基本信息以及单词级别的边界框和文本。它包含 626 张图像,但我只会训练 100 张来展示 Donut 的有效性。它是一个比 CORD(包含约 1000 张图像)更小的数据集,而且标签也少得多(只有公司、日期、地址和总数)。
下载和解析SROIE
要下载数据集,您只需从主存储库下载 data 文件夹。您可以通过克隆整个存储库或使用诸如下载目录之类的东西来仅下载单个文件夹来执行此操作。
但是现在我们需要将数据集解析为 HuggingFacedatasets库所需的格式,这是 Donut 在后台使用的将自定义数据集加载为图像字符串表的格式。 (如果您正在寻找文档,Donut 使用imagefolder加载脚本。)
这是所需的数据集格式:
数据集_名称
├── 测试
│ ├── metadata.jsonl
│ ├── {image_path0}
│ ├── {image_path1}
│ .
│ .
├── 火车
│ ├── metadata.jsonl
│ ├── {image_path0}
│ ├── {image_path1}
│ .
│ .
└── 验证
├── metadata.jsonl
├── {图像_path0}
├── {图像_path1}
.
.
其中 metadata.jsonl 是一个 JSON 行文档,看起来像
{"file\name": {image\path0}, "ground\truth": "{"gt_parse": {ground\truth_parse}, ... {other_metadata_not_used} 。 ..}"}
{"file\name": {image\path1}, "ground\truth": "{"gt_parse": {ground\truth_parse}, ... {other_metadata_not_used} 。 ..}"}
换句话说,我们希望将每个文档的注释(在 key 文件夹中找到)转换为类似于"{\"gt_parse\": {actual JSON content}"}"的地面实况 JSON 转储字符串。这是一个示例注释:
{
"公司": "BOOK TA .K (TAMAN DAYA) SDN BHD",
“日期”:“25/12/2018”,
"address": "NO.53 55,57 & 59, JALAN SAGU 18, TAMAN DAYA, 81100 JOHOR BAHRU, JOHOR.",
“总计”:“9.00”
}
这是我用来将数据转换为 JSON 行文件以及将图像复制到各自文件夹中的脚本:
进口我们
导入json
进口开玩笑
从 tqdm.notebook 导入 tqdmlines u003d []
图像 u003d []
对于 tqdm 中的 ann(os.listdir("./sroie/key")[:100]):
如果安!u003d“.ipynb_checkpoints”:
使用 open("./sroie/key/" + ann) 作为 f:
数据 u003d json.load(f)images.append(ann[:-4] + "jpg")
行 u003d {"gt_parse": 数据}
lines.append(line)with open("./sroie-donut/train/metadata.jsonl", 'w') as f:
对于 i, gt_parse in enumerate(lines):
line u003d {"file_name": images[i], "ground_truth": json.dumps(gt_parse)}
f.write(json.dumps(line) + "\n")shutil.copyfile("./sroie/img/" + images[i], "./sroie-donut/train/" + images[一世])
我只是简单地运行了这个脚本 3 次,每次都更改文件夹和列表切片 ([:100]) 的名称,因此我在 train 中有 100 个示例,在 validation 和 test 中有 20 个示例。
训练模型
Donut 的作者提供了一种非常简单的方法来训练模型。首先,我们需要在 donut/config 文件夹中创建一个新的配置文件。您可以将已经存在的示例 (train_cord.yaml) 复制到一个名为 train_sroie.yaml 的新文件中。这些是我更改的值:
数据集_name_or_paths: ["../sroie-donut"]
训练_batch_sizes:[1]
检查_val_every_n_epochs:10
max_steps: -1 # 无限,因为指定了 max_epochs
如果你在本地下载了donut-base模型,你也可以在pretrained_model_name_or_path中指定它的路径。否则,HuggingFace 将直接从 Hub 下载它。
当我在 Google Colab 上遇到 CUDA 内存不足错误时,我将批处理大小从 8 减少,并将check_val_every_n_epochs增加到 10 以节省时间。
这是您应该用来训练模型的行:
cd donut && python train.py --config config/train_sroie.yaml
我花了大约一个小时在 Google Colab 提供的 GPU 上完成训练。
使用微调模型进行推理
使用与上述 CORD 演示类似的脚本,我们可以使用
从甜甜圈进口甜甜圈模型
从 PIL 导入图像
导入 torchmodel u003d DonutModel.from_pretrained("./donut/result/train_sroie/20220804_214401")
如果 torch.cuda.is_available():
模型.half()
设备 u003d torch.device("cuda")
模型.to(设备)
别的:
model.encoder.to(torch.bfloat16)
model.eval()image u003d Image.open("./sroie-donut/test/099.jpg").convert("RGB")
输出 u003d model.inference(imageu003dimage, promptu003d"<s_sroie-donut>")
输出
请注意,我们已经更改了DonutModel.from_pretrained()调用中的模型路径,并且我们还将推理prompt更改为格式<s_{dataset_name}>。这是我使用的图像:

图片来自SROIE 数据集
这些是我的结果:
{'predictions': [{'address': 'NO 290, HOT WATER ROAD.图案。 53200, 吉隆坡。',
'公司': '金记商业公司',
“日期”:“2017 年 4 月 12 日”,
“总计”:“47.70”}]}
最后的想法
我注意到使用 Donut 的伪 OCR 的最终输出比传统的现成 OCR 方法准确得多。举个极端的例子,下面是演示 OCRed 中使用 Tesseract 的 OCR 引擎的相同 CORD 文档:
*‘他"我
— ' s ' —
W u003d
哦哦
好的
?ffi (€
rgm“f”; o;
李四
图像模糊,对比度低,即使是人类也难以阅读,因此任何人都不太可能期望模型能够识别字符。令人印象深刻的是,Donut 能够用自己的技术做到这一点。即使有高质量的文档,虽然其他商业 OCR 模型提供比 Tesseract 等开源 OCR 引擎更好的结果,但它们通常成本高昂,而且只是因为对商业数据集的密集训练和更多的计算能力才更好。
解析给定文档的 OCR 输出的模型的替代方法包括仅使用计算机视觉技术来突出显示各种文本块、解析表格或识别图像、图形和数学方程,但再次要求用户对边界框进行 OCR -如果可以导出有意义的数据,则输出。库包括LayoutParser和deepdoctection,它们都连接到Detectron2计算机视觉模型的模型动物园以提供结果。
此外,Donut 的作者还提供了一个测试脚本,您可以使用该脚本为您的微调模型开发评估指标,该脚本位于 Donut 代码库的 test.py 文件中。它提供了 F1 准确度分数,这些分数是根据对地面实况解析的准确通过或失败来衡量的,以及由树编辑距离算法给出的准确度分数,该算法确定最终 JSON 树与地面实况 JSON 的接近程度。
cd ./甜甜圈 &&
python test.py --dataset_name_or_path ../sroie-donut --pretrained_model_name_or_path ./result/train_sroie/20220804_214401 --save_path ./result/火车_sroie/output.json
使用我的 SROIE 微调模型,我所有 20 个测试图像的平均准确率为 94.4%。
Donut 还与 SynthDoG 打包在一起,SynthDoG 是一种模型,可用于生成额外的假文档,用于四种不同语言的数据增强。它接受了英文、中文、日文和韩文维基百科的培训,以便更好地解决传统 OCR/VDU 方法的问题,这些方法通常受到缺乏大量英语以外语言数据的限制。
[1] 金,Geewook 等人。 “无 OCR 文档理解转换器。” (2021 年)。麻省理工学院许可证。
[2]郑煌,等。 “ICDAR2019 扫描收据 OCR 和信息提取竞赛”。 2019 国际文档分析与识别会议(ICDAR)。 IEEE,2019。麻省理工学院许可证。
Neha Desaraju 是德克萨斯大学奥斯汀分校计算机科学专业的学生。你可以在estaudere.github.io**.**找到她

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 1
1 2
2- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)