我如何使用 Python、Scikit-Learn 和 Pandas 构建歌曲推荐系统
简介
您一定看过 Spotify 向您推荐歌曲。或 YouTube 和 TikTok 等其他平台会根据您之前的观看体验推荐视频。
在构建我的独立项目时,MeTime🎶(一个无广告的音乐流媒体平台......即将推出😉)我想向用户推荐新歌曲并帮助他们发现新的声音。从那时起,我决定建立一个推荐系统,接收他们喜欢的歌曲并给出相似的曲目或_suggests_新歌。
在这里,我将讨论如何使用 python 和一些 scikit-learn 和 pandas 的 ML 魔法来构建它,让我们开始吧!
数据集
好的,现在我们已经开始了探索,我们将找到一个数据集,其中包含一些 Spotify 曲目及其音频特征(如歌曲的可舞性、声学、能量、积极性......)。我相信kaggle是最好的狩猎数据的地方。一些关键字搜索,我们已经可以找到这么多充满 Spotify 曲目的数据集
通过搜索,我发现这个数据集是有用的
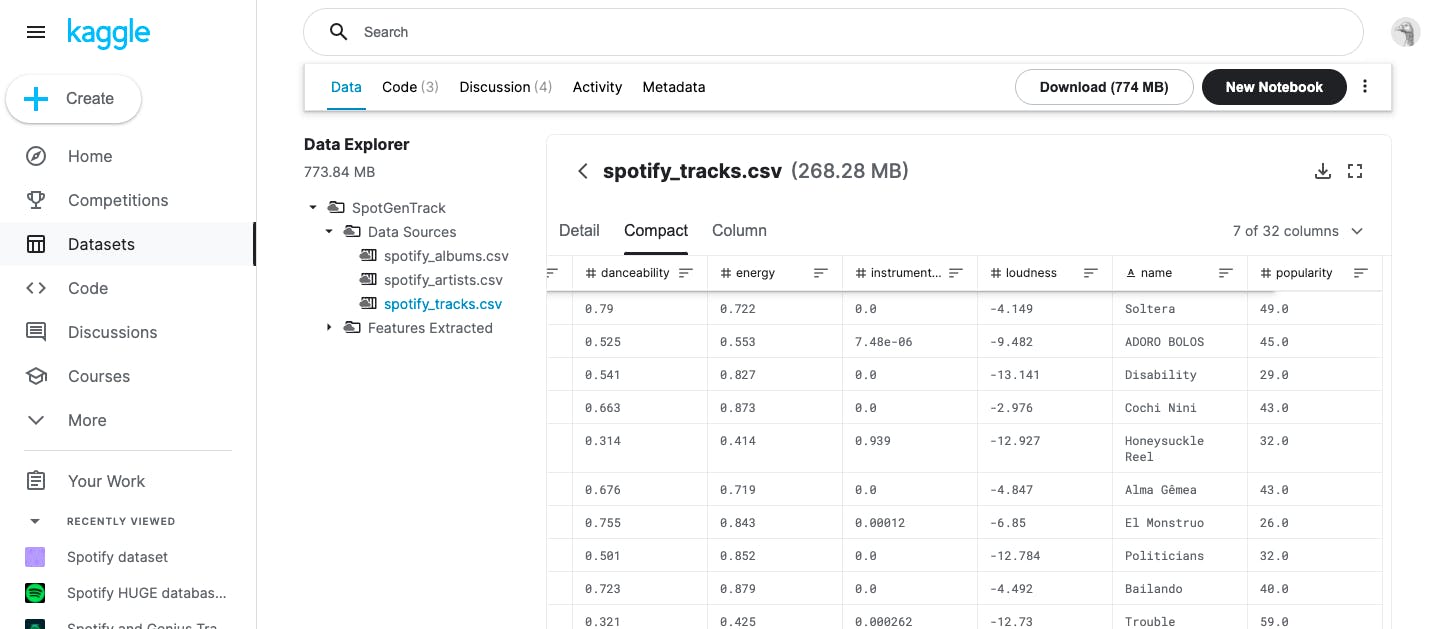
这个数据集最好的地方在于它包含了我们关心的每一个属性,受欢迎程度、能量、可跳舞性、效价(积极性)和工具性。 我们将使用这些功能将数据集聚类为几个部分,并确定大多数用户最喜欢的曲目位于哪个聚类中。
注意:您基本上可以选择任何大小的数据集只要它具有所有必要的音频特征(流行度、声学、能量、价、舞蹈能力和歌曲 ID),但您应该选择尽可能大的数据集因为更大的数据集通常意味着大量的数据点,这为我们推荐歌曲和训练我们的机器学习模型提供了一个很好的立场
现在让我们打开一个 jupyter notebook 并使用 pandas 导入下载的数据集

"刚刚发生了什么?"
在这里,我们使用了熊猫
Pandas 是一个 Python 库,用于读取、写入、操作、可视化和查询数据)从 csv 文件中读取数据集
...并将其加载到熊猫数据框中。
Pandas 中的数据框为我们提供了对给定数据执行适当操作的正确函数或方法
对数据集进行聚类
现在问题出现了**“我们如何根据音轨的音频特征对数据集进行聚类?”**,这里 scikit-learn 发挥作用,sklearn 有许多实用的导入和使用数学模型_处理数据和执行统计功能_时让事情变得更容易。但是在我们使用 sklearn 或 scikit-learn 之前,新手很自然地会问“这到底是什么?”
SciKit-Learn 是一个 Python 库,其中包含各种易于使用的模块,有助于分析、预测和可视化数据。
sklearn 有一个名为clusters的模块,其中包含KMeans模型,它可以帮助我们做我们需要的事情......将数据分成某些组。 (您可以在此处了解有关KMeans算法如何工作的更多信息)
一般来说,在对数据执行任何统计操作之前,最好先查看其特征之间的相关性并绘制它们之间的图表,以便我们可以了解并可视化其中发展的任何自然模式。为此,我们使用我们的朋友pandas在所有特征之间绘制一张图,将所有特征与它们中的每一个相关联。
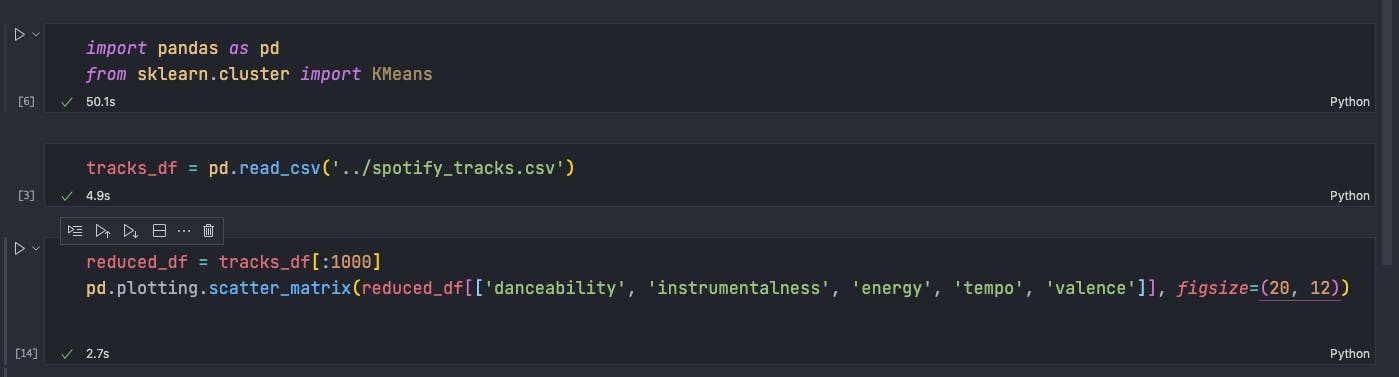
在笔记本的第三个代码块中,我所做的只是将这个大的 'ol 数据集减少到 1000 个数据点或“切片”它(类似于切片列表),只选择我想要绘制图形的列或特征(您可以使用此语法选择 pandas 数据框的特定列)并将其传递给函数:
pd.plotting.scatter_matrix(frame, figsize=( , ))
我减少的原因是,如果我要对整个数据集执行scatter_matrix操作,则需要 5-7 分钟来处理数据框中的所有成百上千条轨迹并以图形方式绘制它们的特征。此外,我使用figsize参数来缩放图形,在 Python 元组中提供宽度和高度(这样我就可以在 1 个屏幕截图中获得绘图😅)。

查看图表后,我们可以看到跳舞能力、效价和能量等特征之间的良好相关性。为了证实这一点,让我们绘制一个数值表来查看与pandas内置方法的数字相关性
!熊猫数据帧中的相关性方法
现在,来到我们想要在数据中创建组的具体案例,从视觉和数字上查看相关性,在这些数据中没有形成明显的自然组。因此,我们将测试和修改我们想要创建多少个集群,太低,我们最终会在一个集群中分类多个流派,太高,我们会丢失一个集群中相同流派的轨道。
让我们看看如何在 Python 语法中做到这一点......
在这里,我选择了严重影响歌曲类型的主要特征,从而影响它所属的集群并将新数据帧存储在tracks变量中。
然后,我初始化KMeans模型并将其存储在相应的变量中,然后,我使用.fit()方法在数据上“拟合”或“训练”模型,并传入我们希望模型“训练”的数据。
通过“训练”或“拟合”,我的意思是
KMeans模型将确定每个具有其特定音频特征的音轨应该位于哪个集群中并为其分配集群编号
拟合数据集后,它将簇编号(在本例中为范围从 0 到 4 的正整数列表)存储在名为labels_的变量中,该变量以与数据帧中的每个轨道相对应的方式排列。
给出建议
现在,进入我们任务的最后一幕,我们要做的是,编辑并将上面生成的labels_保存在每个音轨的列中,将数据集保存在单独的 csv 文件中并找出簇号在用户的播放列表中出现最多,从而找出用户最喜欢的歌曲类型并为他们提供具有相同簇号的曲目或者您可以说相同的“类型”
在 pandas 中,我们使用以下语法向数据框中添加一列:
dataframe[column_name] = an_array_with_same_number_of_rows

添加后,是时候使用我们方便的 pandas 数据框的.to_csv()方法将新更改的数据框保存在 csv 文件中了
tracks_df.to_csv('../result.csv')
现在让我们创建一个 Python 程序,它会接收用户最喜欢的曲目的 ID,并为他们推荐一些好听的歌曲!
# CONSTRUCT YOUR OWN LOGIC!
import pandas as pd
tracks = pd.read_csv('./result.csv')
ids = input('Enter comma-separated ids of your favorite songs\n> ').strip().split(',')
# sample input: 1xK1Gg9SxG8fy2Ya373oqb,1xQ6trAsedVPCdbtDAmk0c,7ytR5pFWmSjzHJIeQkgog4,079Ey5uxL04AKPQgVQwx5h,0lizgQ7Qw35od7CYaoMBZb,7r9ZhitdQBONTFOiJW5mr8,3ee8Jmje8o58CHK66QrVC2,3ZG8N7aWw2meb6UrI5ZmnZ,5cpJFiNwYyWwFLH0V6B3N8,26w9NTiE9NGjW1ZvIOd1So,7BIy3EGQhg98CsRdKYHnJC,2374M0fQpWi3dLnB54qaLX,2IVsRhKrx8hlQBOWy4qebo,40riOy7x9W7GXjyGp4pjAv,4evmHXcjt3bTUHD1cvny97,0MF5QHFzTUM2dYm6J7Vngt,0TrPqhAMoaKUFLR7iYDokf,07KXEDMj78x68D884wgVEm,6gxKUmycQX7uyMwJcweFjp
# search the specified ids in this dataset and get the tracks
favorites = tracks[tracks.id.isin(ids)]
# code to sort find out the maximum occuring cluster number according to user's favorite track types
cluster_numbers = list(favorites['type'])
clusters = {}
for num in cluster_numbers:
clusters[num] = cluster_numbers.count(num)
# sort the cluster numbers and find out the number which occurs the most
user_favorite_cluster = [(k, v) for k, v in sorted(clusters.items(), key=lambda item: item[1])][0][0]
print('\nFavorite cluster:', user_favorite_cluster, '\n')
# finally get the tracks of that cluster
suggestions = tracks[tracks.type == user_favorite_cluster]
# now print the first 5 rows of the data frame having that cluster number as their type
print(suggestions.head())
对于上面的代码,你会想做一些即兴创作,我故意留了一些空间,但上述机制存在一个大问题,它也会推荐 1950 年代或 1960 年代的非热门歌曲,我认为没有人愿意在像“Despacito”这样的流行歌曲中听到他们(仍然喜欢那首歌),所以在我们阅读数据集的那一刻,根据流行度 > 60 或 70 来过滤歌曲将是一个很好的举措。像这样的东西:
...
tracks = tracks[tracks.popularity > 70]
...
而且......就是这样!这是向用户推荐类似曲目的最低限度的代码。您现在可以托管一个成熟的烧瓶服务器,仅提供从用户喜欢的曲目 ID 中获取的建议,或者为开发人员制作一个 CLI 工具来发现来自 Spotify 的新歌曲。
集成 Spotify API 让你走开!
 改天见你另一个帖子;)
改天见你另一个帖子;)
我希望你喜欢这篇文章,非常感谢任何反馈!如果您喜欢我的帖子,请考虑以下 :)
推特->@BhardwajKuvam
Github ->@kuvamdazeus
领英 ->@kuvambhardwaj
投资组合 ->kuvambhardwaj.vercel.app


Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126440条内容
已为社区贡献126440条内容

所有评论(0)