面向 Python 程序员的 Ibis 简介
几周前,我正在建立一个关系数据库,以探索 DataSF 的Civic Art Collection.中的记录。每当我参加技术会议时,我都会尝试在这个城市花一两天时间来看看它的文化场景,所以这似乎是有用的信息!我决定使用 MySQL 作为我的数据库引擎。来自 Pandas 的背景让我对编写原始 SQL 查询的效率低下和限制感到惊讶。我还花费了大量时间来解决查询中的错误,这些查询使用一种 SQL,但使用 MySQL 失败。在整个过程中,我一直在想,如果有一种更 Pythonic 的方式就好了!!!几周后,我被介绍给宜必思。
Ibis提供了一种更加 Pythonic 的方式来与多个数据库引擎进行交互。在我自己的冒险中,我总是遇到栖息在大象身上的宜必思(鸟类版本)。如果你在现实生活中从未见过大象,我可以确认它们是巨大而复杂的生物。这是我站在一些比例旁边的照片;)

一只小鸟坐在一头大象上的形象隐喻了 ibis 如何为用户提供一种更简单、更高效的方式与多个大数据引擎进行交互。事实上,您的数据越大越复杂,使用 Ibis 的争论就越多。当您的查询非常复杂时,SQL 可能很难维护。使用 ibis,无论您是扩大还是缩小规模,都无需完全重写您的代码。如果需要,您可以切换后端并继续在相同的上下文中工作,但使用更强大的引擎。这意味着您的工作流程得到简化,更不容易出错,并且您的认知负担也减少了。
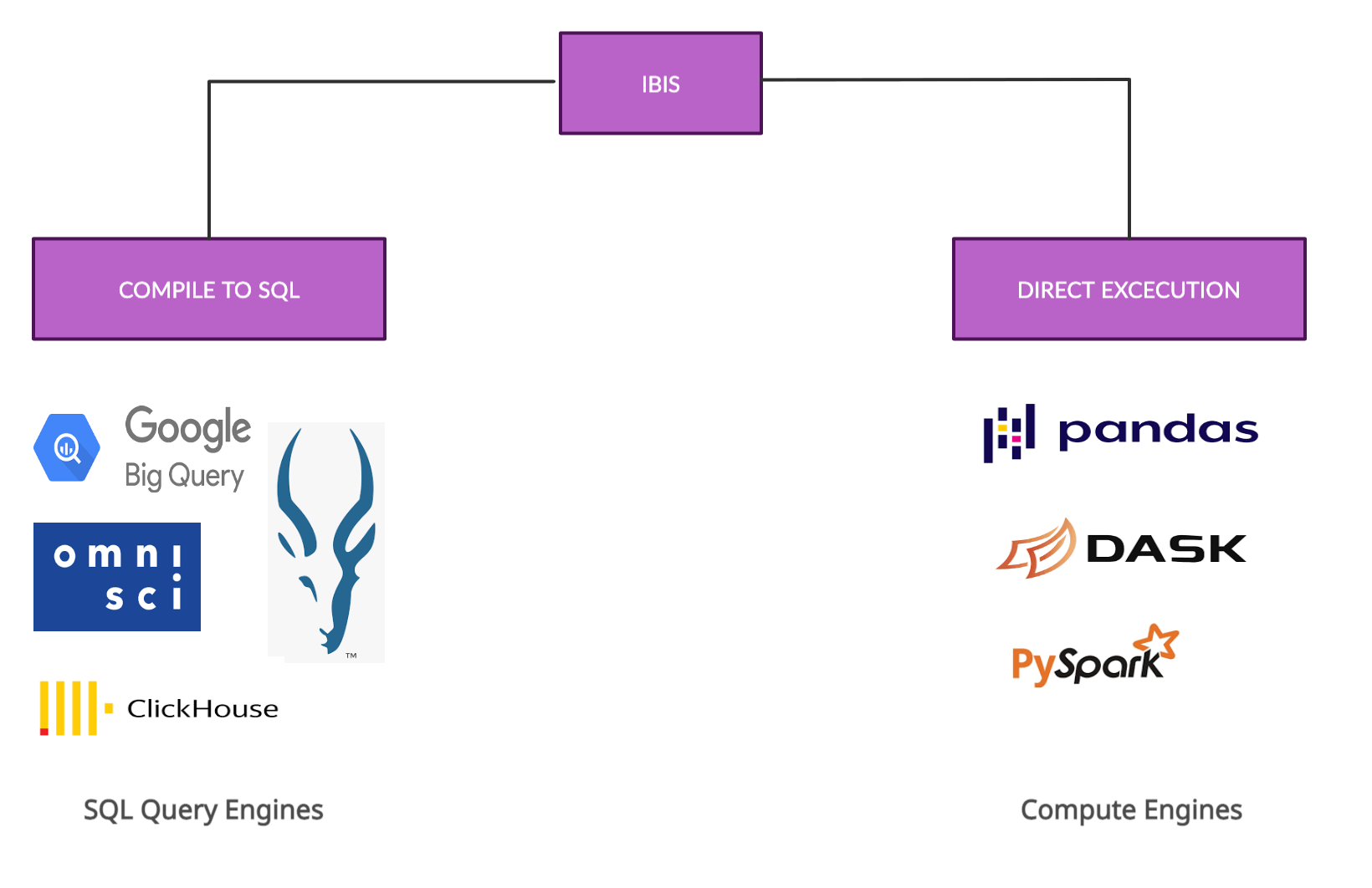
目前,Ibis支持相当多的后端,包括:
传统 DBMS:PostgreSQL、MySQL、SQLite 分析 DBMS:OmniSciDB、ClickHouse、Datafusion 分布式 DBMS:Impala、PySpark、BigQuery 内存分析:pandas、Dask
无论您是想要与 SQL 数据库交互还是想要使用分布式 DBMS,Ibis 都可以让您在 Python 中完成此操作。在这篇文章中,我将使用 SQLite 后端,但如果您想尝试其他任何一种,请查看 Ibis 后端页面以获取示例。 Ibis 目前支持超过 12 个后端,其中一些编译为 SQL,一些直接执行。
对于 Python 程序员,Ibis 提供了一种用 Python 编写 SQL 的方法,它允许对特定查询引擎(例如 BigQuery)进行单元测试、可组合性和抽象!您可以使用熟悉的类似 Pandas 的语法对数据执行连接、过滤和其他操作。总体而言,使用 Ibis 可以简化您的工作流程,提高您的工作效率,并使您的代码保持可读性。
让我们使用我之前提到的Civic Art Collection数据集,看看 Ibis 能做什么!
安装
您可以使用 Pip、Conda 或 Mamba 安装 Ibis。
为了安全起见,我建议设置一个虚拟环境。您可以将这些命令复制并粘贴到您的终端中,以使用 Pip 或 Conda 安装 ibis。
点数:
在本教程中,我们将使用 SQLite 作为我们的后端。如果您使用 pip 安装 Ibis,您需要运行pip install 'ibis-framework[sqlite]'而不是通常的pip install ibis-framework才能使 sqlite 工作。如果您希望使用其他后端,请查看 Ibis 文档中的特定命令。
Mac:
python3 -m venv ibisdev
source ibisdev/bin/activate
pip install 'ibis-framework[sqlite]'
pip install pysqlite
视窗:
python3 -m venv ibisdev
ibisdev\Scripts\activate.bat
pip install 'ibis-framework[sqlite]'
pip install pysqlite
康达
conda create -n ibisdev python=3.8
conda activate ibisdev
conda install -c conda-forge ibis-framework
conda install -c anaconda sqlite
使用 SQLite 创建数据库
如果您愿意跟我一起学习,接下来我们要做的就是创建一个数据库和一个表格,其中包含来自 DataSF 的旧金山周边艺术数据。数据是开源的,因此您可以直接从该站点下载 csv 文件。 Ibis 尚不支持将 csv 文件加载到 SQL 表中,因此我们将按照这些命令在 SQLite 命令行中执行此操作
创建一个名为 civic_art 的文件夹
mkdir civic_art
cd civic_art
为了使接下来的步骤更容易,我将 csv 文件从我的下载文件夹移动到我们刚刚创建的 civic_art 文件夹中。当我们在 civic_art 文件夹中时,我们使用以下命令创建一个新数据库。
创建一个名为 civicArt.db 的数据库
sqlite3 civicArt.db
此命令还应该在您的命令行中打开 SQLite。这是我的图片(我使用.databases仔细检查数据库是否已正确创建。)
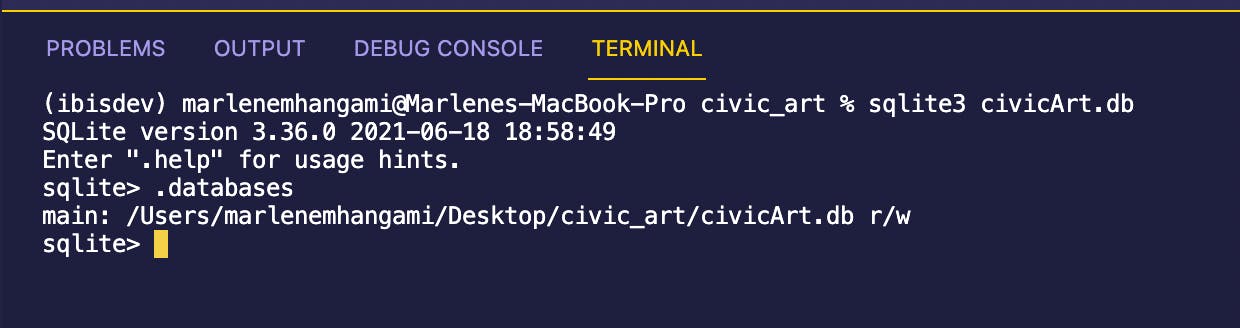
伟大的!数据库已成功创建! SQLite 已经在 civicArt 数据库中打开,所以接下来我们要做的是创建一个表并将 csv 文件中的数据加载到其中。
在 civicArt.db 数据库中创建一个名为 civicArtTable 的表
.mode csv civicArtTable (names the table)
.import Civic_Art_Collection.csv civicArtTable (import the data into the table)
检查表是否已按预期创建
.tables (this lets you check the table has been correctly created)
.schema civicArtTable (describes the table)
如果您的表已按预期创建,您现在可以通过输入.quit退出 SQLite。这应该带你回到你的命令行。我们现在已经准备好开始使用 ibis 探索我们的数据了!
连接数据库
ibis 的优势之一是它可以让您使用最熟悉的工具。我喜欢用 IPython 编写 Python 代码,但你可以使用 jupyter notebook 或任何你喜欢的 Python shell。无论您选择什么,我们都将使用相同的命令连接到我们之前创建的 civicArt 数据库。
连接到我们的数据库(我们将使用 Ibis 的交互模式进行惰性评估)
import ibis
ibis.options.interactive = True
db = ibis.sqlite.connect("civicArt.db")
这里需要注意的是,pandas (read_sql) 将数据加载到内存中并自行执行计算。 Ibis 不会加载数据或执行任何计算。相反,它将数据留在连接定义的数据库中,并要求后端在那里执行计算。这意味着您可以以后端的速度执行,而不是本地计算机。思考这个问题的一个好方法是回到我们的大象比喻。如果您需要完成一些繁重的工作,与宜必思相比,让大象来做可能是个好主意。我们优雅的 ibis 可以将繁重的工作传递给更大的数据库,并观察工作的完成速度比它自己完成的速度要快得多。

如果一切顺利,您应该连接到数据库。接下来我们来看看我们的数据!
查看表详情
让我们用Ibis来看看civicArt数据库中的表
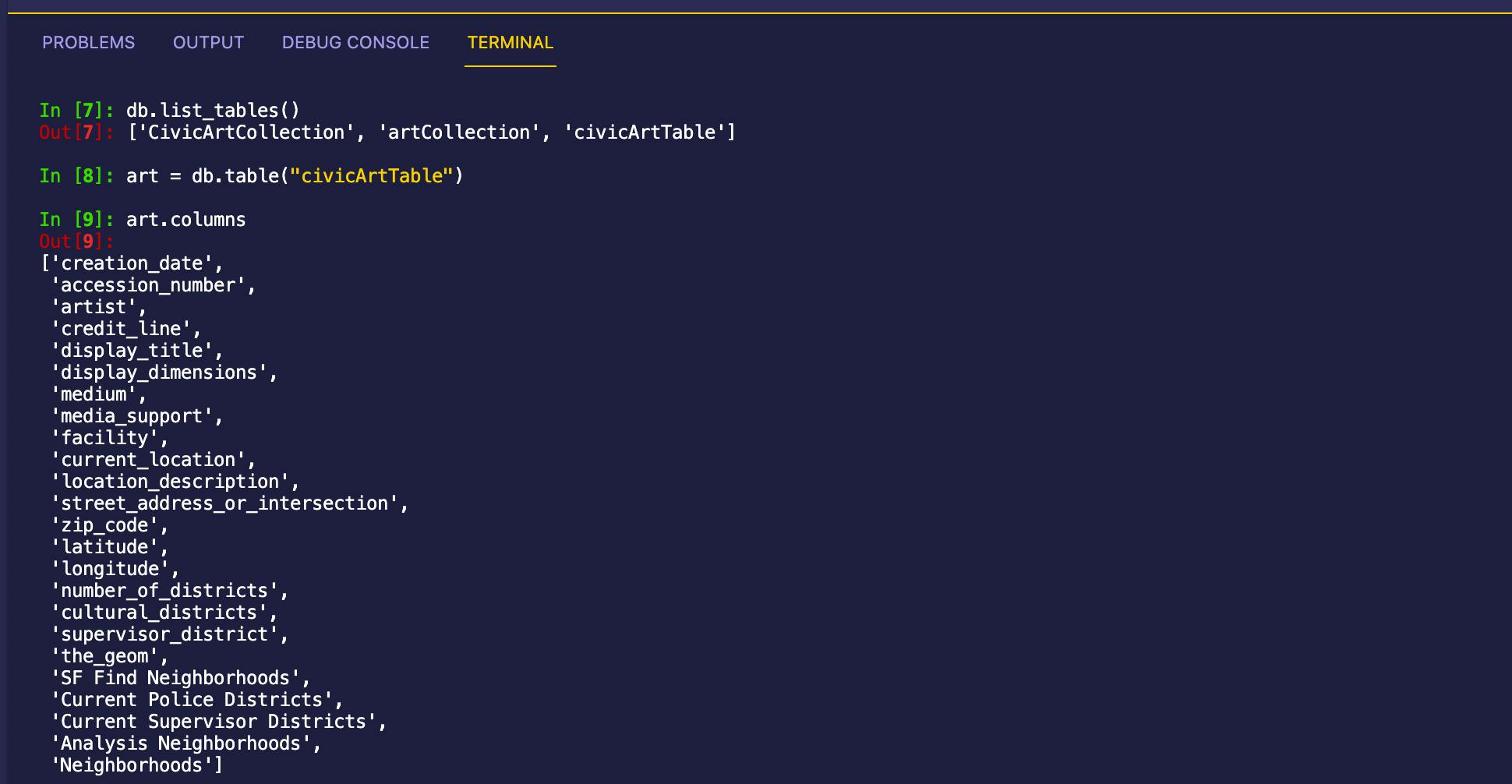
列出数据库中的所有表
db.list_tables()
为表格分配一个更易读的名称并列出其中的列
art = db.table("civicArtTable")
art.columns
这是我在调用这些命令后在 IPython 中看到的
与 Ibis 争吵数据
现在让我们使用 Ibis 对我们的数据集执行一些常见的 SQL 命令,并在此过程中找出有关旧金山艺术的一些有用信息。
查询中
您可以在 SELECT 语句中编写的任何内容都可以在 Ibis 中编写。让我们测试一下!我将使用以下代码来找出哪些艺术家目前在城市中展示了艺术作品,以及他们作品的标题是什么。
从表中选择列
art["artist", "display_title"]
伟大的!如果您在此之前使用过 Pandas,应该感觉类似于从 Pandas Dataframe 中获取列,但请记住数据库正在为我们完成所有工作,所以这样更有效率!

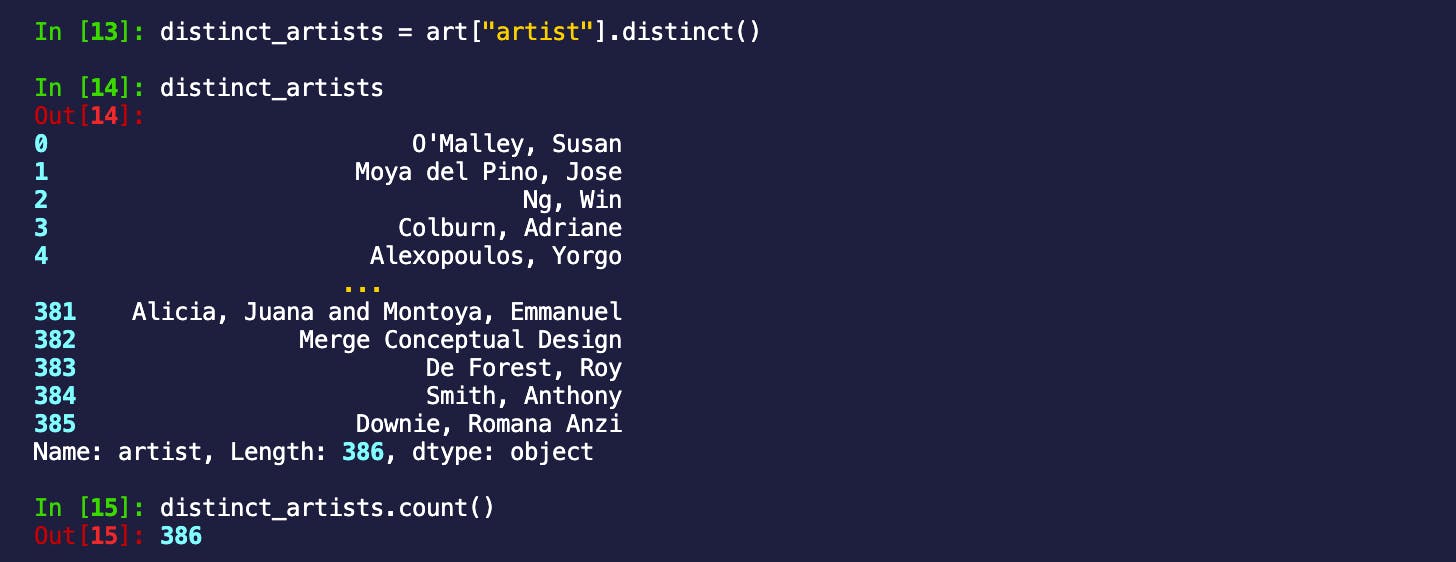
我也很好奇总共有多少艺术家展出了他们的作品,以防一位艺术家展出不止一件作品。为此,让我们找到不同的艺术家,然后计算他们
区分和计数
distinct_artists = art["artist"].distinct()
distinct_artists.count()
我们已经可以看到列表的长度,但只是为了向您展示计数方法,我们确认在旧金山展出一件或多件作品的艺术家数量为 386!
过滤数据
接下来让我们选择一位艺术家,并找出他们所有艺术作品的确切位置。 Adriane Colburns 的显示标题Geological Ghost引起了我的注意,所以让我们选择它们吧!
我使用以下命令来执行此操作
adrianes_art = art.filter(art["artist"] == 'Colburn, Adriane')
adrianes_art
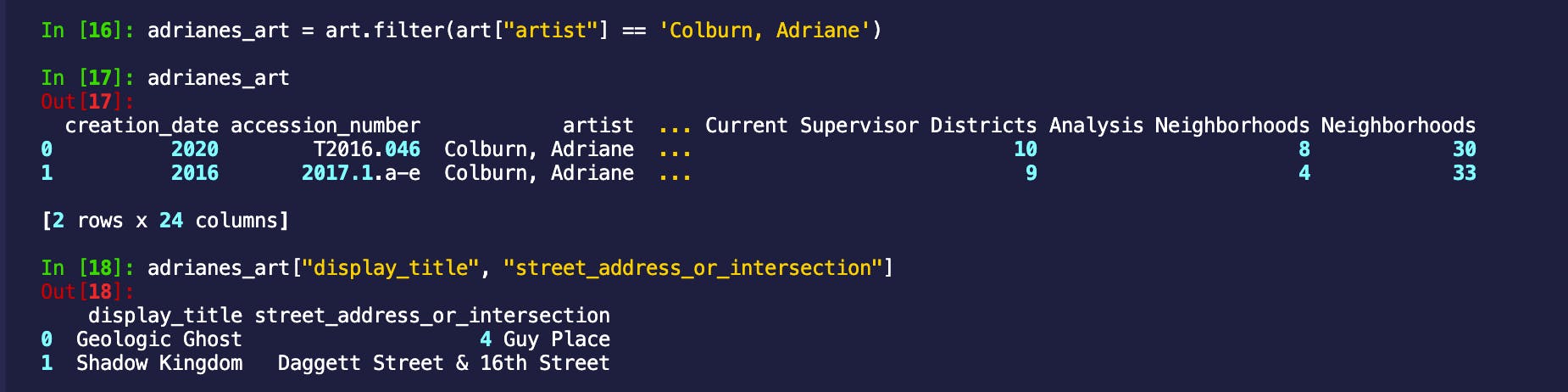
所以事实证明,Adriane 展出了两件作品,一件在4 Guy Place,另一件在Dagget Street & 16th Street。太好了,我们已经有一些地方可以添加到我们的旅游行程中!
Groupby
会议结束后,我通常不会在一个城市停留超过一两天,所以很高兴知道哪些地方展出的艺术品最多。为了弄清楚这一点,我们将使用以下groupby表达式来获取我们需要的信息。
使用groupy和sort_by获得旧金山艺术最多的地点!
art_loc = art.groupby("street_address_or_intersection").count('display_title')
most_art = art_loc.sort_by(ibis.desc(art_loc.display_title))
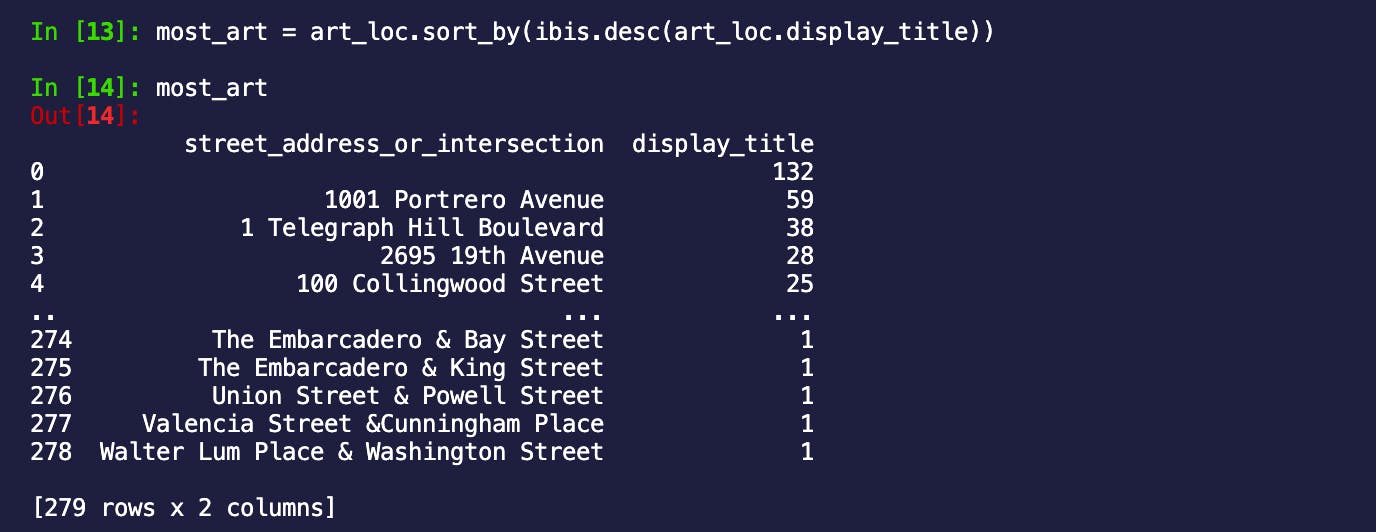
太好了,第一站是波特雷罗大街 1001 号,展出了 59 本书!!
出于好奇,我搜索了 1001 Potrero Avenue,以了解更多关于我所期望的艺术画廊的信息。令人惊讶的是,它竟然是扎克伯格旧金山总医院。他们显然在艺术上投入了大量资金,并且拥有令人难以置信的收藏。数据的关键在于它可以让你大吃一惊!下一个最佳选择是 Coit Tower,其地址位于 1 Telegraph Hill Blvd。它不是医院,看起来是个值得探索的好地方!

学分:珍妮丝·赫克特
加入
出色的。在这一点上,我们知道下次我们在旧金山参加技术会议时,我们有一些很棒的选择可以查看。我是在编写代码后才发现的,所以让我们假设 1001 Potrero Avenue 不是医院,并将其用作我们的首选!现在我们知道该去哪里了。下一步是什么?
嗯,通常艺术画廊里挤满了时髦人士,他们可能会问你展出的艺术家。好在我们可以提前做好准备!让我们使用内部连接来帮助我们找到哪些艺术家的艺术展示最多,这样我们就可以查找它们并通过良好的响应来感觉很酷;)
使用 inner\join 查找最受欢迎的艺术家
artist_location = art["street_address_or_intersection", "artist"]
artists_at_portrero = artist_location.filter(artist_location["street_address_or_intersection"] == "1001 Portrero Avenue").distinct()
*ibis 2.1.1 版有时会遇到一个问题,即视图注释被物化,然后物化不解析连接操作中的列名。以下代码片段仅适用于 2.1.1 版本,并使用 mutate() 函数(第一行)更改其中一个列标题和 materialize() 以确保可以显示创建的视图。这应该在版本 3.0.0 中修复。
artist_number_of_displays = art.mutate(c_artist=art['artist']).groupby("c_artist").count("display_title")
most_popular_artist = artists_at_portrero.inner_join(
artist_number_of_displays,
predicates=artists_at_portrero["artist"] == artist_number_of_displays["c_artist"]
).materialize()
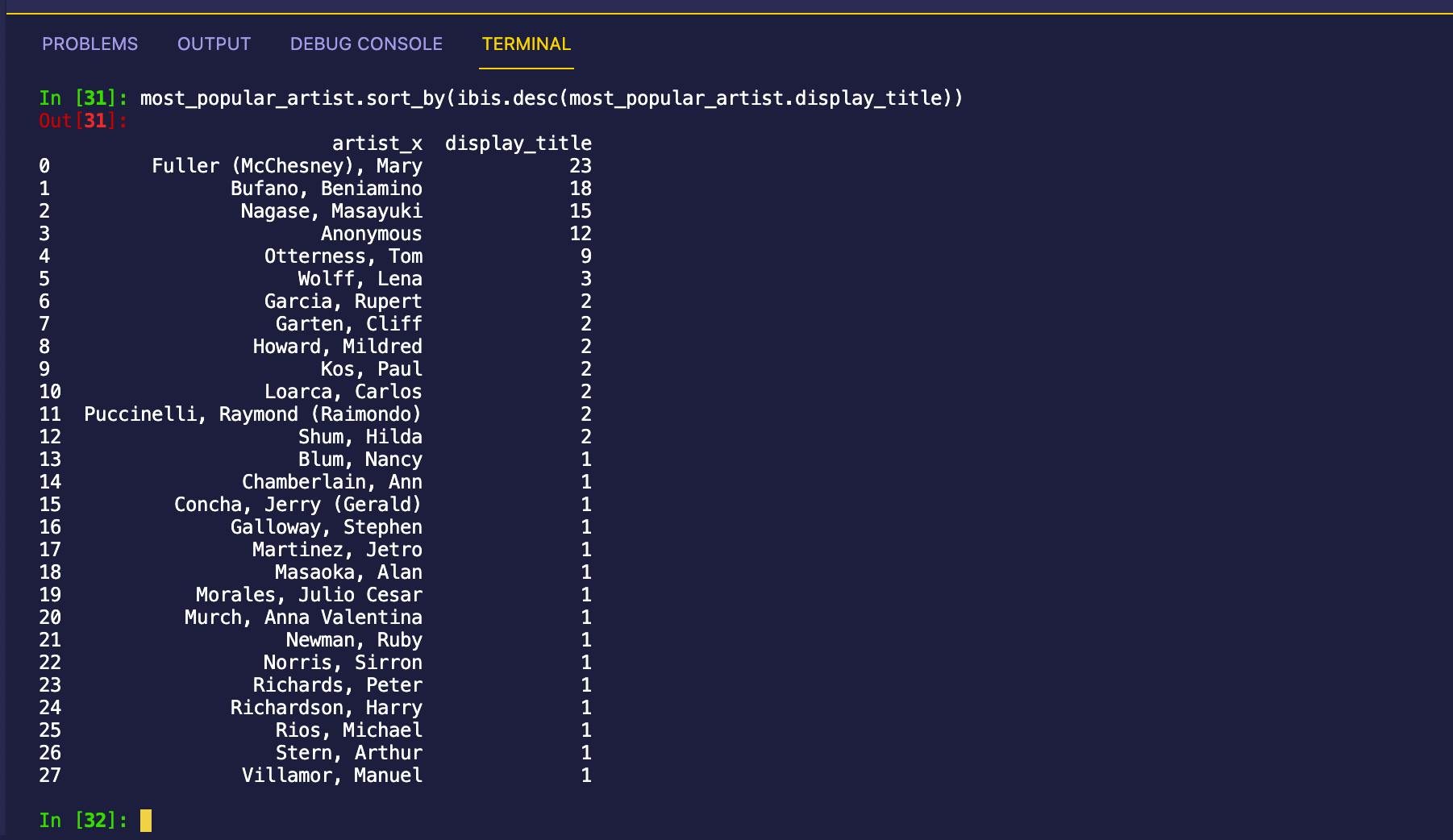
极好的!我们现在知道 Mary (McChesney) Fuller 在 1001 Potrero Avenue 展出的艺术品最多,可以在线搜索以了解更多信息!在我看来,我们已经准备好探索旧金山的艺术场景了!
我们在相对较短的时间内学到了很多信息。如果您习惯于编写 Python 代码,这可能感觉比编写原始 SQL 字符串更有效。这也意味着如果您在 IPython 或 Jupyter Notebook 中开始您的工作流程,您可以留在那里。这应该感觉更顺畅,并有望提高生产力。使用可以帮助您提高效率的工具意味着您有更多时间在工作中进行创造力和探索!我希望这个给你!感谢您的阅读,希望我能在世界各地的某个地方看到大象或在艺术画廊遇到您!
我们还制作了一个 jupyter notebook,其中包含这篇文章中的所有命令!你可以在这里找到它

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126440条内容
已为社区贡献126440条内容

所有评论(0)