用 Python 分析美国婴儿取名趋势
EDA简介
探索性数据分析(或 EDA)是一种分析数据集以总结或了解其主要特征的方法,通常通过分析趋势以及通过图形和其他数据可视化方法。
我们试图通过可视化数据的结构等来了解数据的整体外观和感觉。
我们的资料
我们使用的数据集是美国婴儿名字数据集,其中包含美国从 1880 年到 2020 年的婴儿名字计数。
让我们开始吧
安装依赖
pip install pandas
pip install matplotlib
pip install streamlit
我们将使用 pandas 和 matplotlib 进行核心分析和可视化,并使用 streamlit 为我们的项目创建 Web 应用程序。
开始编码
导入模块
import pandas as pd
import matplotlib.pyplot as plt
初始EDA
df = pd.read_csv("https://github.com/Rishav-12/baby_name_trends/raw/main/names_ranks_counts.csv")
print(df.head())
我们将 csv 导入数据框并查看前 5 行。显然,每一行都有一个婴儿的名字、性别、出生年份,以及该名字在该特定年份被赋予婴儿的次数。
为了分析给定名字的年度趋势,我们应该按名字和性别过滤数据框(因为有些名字有两种性别)。
为此,我们编写以下代码:
baby_name = "John"
gender = "M"
name_df = df[(df.name == baby_name) & (df.sex == gender)]
print(name_df)
在这里,我们看到每一行都有名称“John”和性别“M”。我们稍后将使用用户输入的名称和性别。
可视化/绘图
现在,如果我们想知道名字的频率多年来是如何变化的,我们可以将计数与年份作图
plt.plot(name_df["year"], name_df["count"])
plt.xlabel("Years")
plt.ylabel("No. of babies")
plt.show()
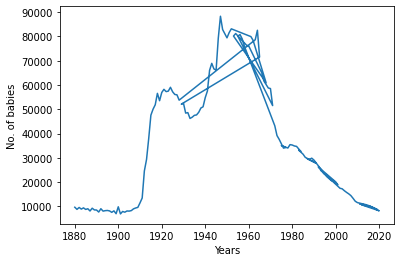
我们注意到该图与我们预期的有些不同。检查过滤后的数据框,我们注意到年份没有排序。我们可以很容易地克服这个问题
name_df = name_df.sort_values("year")
如果我们再次绘制,我们会得到一个正确的图表
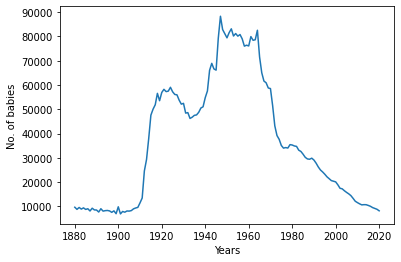
我们可以更改名称和性别以可视化所有不同的名称以及它们多年来的常见程度。
构建用户界面
最后,我们可以使用 streamlit,这是一个构建数据应用程序的平台,为我们的应用程序创建前端。
首先,我们将其导入文件顶部
import streamlit as st
现在,我们可以使用st.write()函数为我们的应用程序编写标题或其他一些信息。
接下来,我们使用两种不同的输入法
baby_name = st.text_input("Baby name", placeholder="Enter a baby name")
gender = st.radio("Gender of the baby", ("M", "F"))
输入我们用户选择的姓名和性别。
为了在网页中嵌入绘图,我们必须创建一个matplotlib图形对象fig,然后使用st.pyplot(fig)
结束语
我们的网络应用程序可以托管在流光云上。我将把它作为练习留给观众。今天,我们执行了 EDA 并可视化了一个大型数据集(超过 200 万行),希望我能启发您创建自己的 EDA 项目,也许使用不同的数据集。
您可以在GitHub上找到代码。
这里还有一个直播版本的网络应用程序
非常感谢您阅读这篇文章。暂时再见!

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126446条内容
已为社区贡献126446条内容

所有评论(0)