如何使用 FastAPI 和 SerpApi 训练可扩展分类器?
这是与人工智能实施相关的系列博客文章的一部分。如果您对故事的背景或故事情节感兴趣:
https://gist.github.com/kagermanov27/6b7cc7f5cd3fb7ee20541b4d0b99cc06
本周,我们将探索SerpApi强大的Google Images Results Scraper API在FastAPI的快速构建 Web 框架之上的组合能力。我们将从使用同步方法创建一个简单的图像数据库创建器开始,然后从那里构建。
Scalable Classifier是什么意思?
该术语是指扩展图像数据库以用于机器学习训练过程的可扩展性,以及以最小的努力大规模扩展或重新训练模型。简单来说,如果你有一个区分猫和狗的模型,你应该可以通过自动收集猴子图像,重新训练,或者扩展现有的分类器来轻松地扩展它。
最小 FastAPI 文件夹结构及说明
https://gist.github.com/kagermanov27/8ebd7be7b2659577b7471d18b3587f32
-
datasets :这个文件夹将用于存储我们将下载的图像,存储旧的下载历史,并将测试数据库拆分为训练数据库。
-
datasets -> test :这个文件夹将包含不同的文件夹,其中包含查询的名称。每个带有查询名称的文件夹都将包含我们将使用的图像。
-
datasets -> train : 不在本周范围内。但就结构而言,它将是测试文件夹的副本。但是,出于培训目的,每个文件夹中的图像数量将少于测试文件夹。
-
datasets -> previous_images.json :此文件将包含已下载的先前链接,以避免重新下载相同的图像。
-
add.py:该文件将负责从 SerpApi 的 Google Images Results Scraper API 中收集唯一链接,然后将图像下载到相应的位置。
-
main.py:用于运行服务器和定义路由的主文件。
-
requirements.txt:我们在运行 Serpapi 时使用的库。您需要通过 pip 下载它们。
要求
https://gist.github.com/kagermanov27/fefd1b18a5646d06e8e2fcd6b3bd2da3
这是我们需要添加到 requirements.txt 文件中的所需库。
应用配置
https://gist.github.com/kagermanov27/a17fd41037cdeab2abfc8d7b4e0f358a
顾名思义,FastApi 允许以最小的努力进行快速的开发过程。我们现在将在main.py中添加两条路由,一条向用户致意,另一条从端点接受 Query 对象:
查询类将包含 pydantic 基本模型对象,其中包含用于从 SerpApi 的 Google Images Scraper API 获取不同结果的参数。下载课程将监督整个过程。
至于添加端点的后台进程,我们在add.py中导入必要的库:
https://gist.github.com/kagermanov27/d2f3c271bcd60f2d79dd15aaecc73089
from multiprocessing.dummy import Array :它是一个自动添加的库,用于多处理目的 from serpapi import GoogleSearch :它是 SerpApi 的库,用于使用 SerpApi 支持的各种引擎。您可以在其Github Repo上找到更多信息。只需通过 pip install google-search-results 命令安装它。 from pydantic import BaseModel : Pydantic 允许我们轻松地创建对象模型。 import mimetypes :Mimetypes 可用于在将下载元素写入图像之前猜测其扩展名。它允许我们猜测 .jpg、.png 等文件的扩展名。 import requests :Python 的 HTTP 请求库,带有为库制作的最酷的徽标。 import json :用于读取和写入 JSON 文件。这对于存储我们已经下载的图像的旧链接很有用。 import os :用于在服务器的本地存储中写入图像,或为不同的查询创建文件夹。
让我们看看如何包含我们对添加端点所做的查询:
https://gist.github.com/kagermanov27/d329b2f61f92134dd87c06c64fd4c2de
在这个 Pydantic 模型中,必须给出 q 和 api_key 参数。但是,正如我在评论中所说,您可以使用给定的方法对您的 api_key 进行硬编码,这样您就不必在每次尝试时都输入它。有问题的 api_key 是指 SerpApi API 密钥。您可以通过我们的注册链接在这里注册免费或付费帐户。您的唯一 API 密钥可以在管理 API 密钥页面中找到。
SerpApi 免费提供缓存结果。这意味着如果对 Apple 的搜索被缓存,您将免费获得它。但是,如果您查询 Monkey,并且它不在我们的缓存中,或者您创建的缓存中,它将消耗您帐户中的一个信用。
google_domain :将抓取 Google 图片的哪个域。 num :给定查询的结果数。它默认为 100,这是最大值。 ijn :指页码。默认为 0 结果将从 ijn x num 开始并以 (ijn x num) + num 结束(这些公式适用于理想情况。Google 可能没有为某些查询提供那么多数据。)起始结果索引将为 0默认,因为默认 ijn 为 0。 q :指您要扩展图像数据库的查询。 api_key:指 SerpApi API Key。
下载图片
让我们声明我们将下载图像的类:
https://gist.github.com/kagermanov27/f3d13976fe50698fc37b4ba6fa5d21ac
self.query :我们将查询存储在类对象中 self.results :我们存储在 Google 图片搜索中找到的所有图片链接。 self.previous_results :以前下载或跳过(将在下面解释)图像链接以避免重新下载。 self.unique_results :我们从查询中收集的唯一链接,我们必须下载以扩展图像数据库。 self.new_results:将先前结果和唯一结果的组合写入 JSON 文件。
让我们定义负责对 SerpApi 进行查询的函数:
https://gist.github.com/kagermanov27/68f49a1bac23ef622032d58c0b9b8f78
如您所见,一些参数,例如引擎和 tbm 是预定义的。这些参数负责抓取 SerpApi 的 Google Images Scraper API。当您对 SerpApi 进行以下查询时,它将返回包含 SERP 结果的不同部分的 JSON:https://serpapi.com/search?engineu003dgoogle&google_domainu003dgoogle.com&ijnu003d0&numu003d100&qu003dApple这基本上是 SerpApi Python 库所做的。结果将如下所示:
https://gist.github.com/kagermanov27/5573378a02c7510e46158005c20986d9
以下是 SerpApi 可以理解并将其作为 JSON 提供的原始 HTML 文件:
您还可以前往 SerpApi Playground 以获得更多视觉体验和调整能力。只需更改搜索?在游乐场的链接中?:https://serpapi.com/search?engineu003dgoogle&google_domainu003dgoogle.com&ijnu003d0&numu003d100&qu003dApple
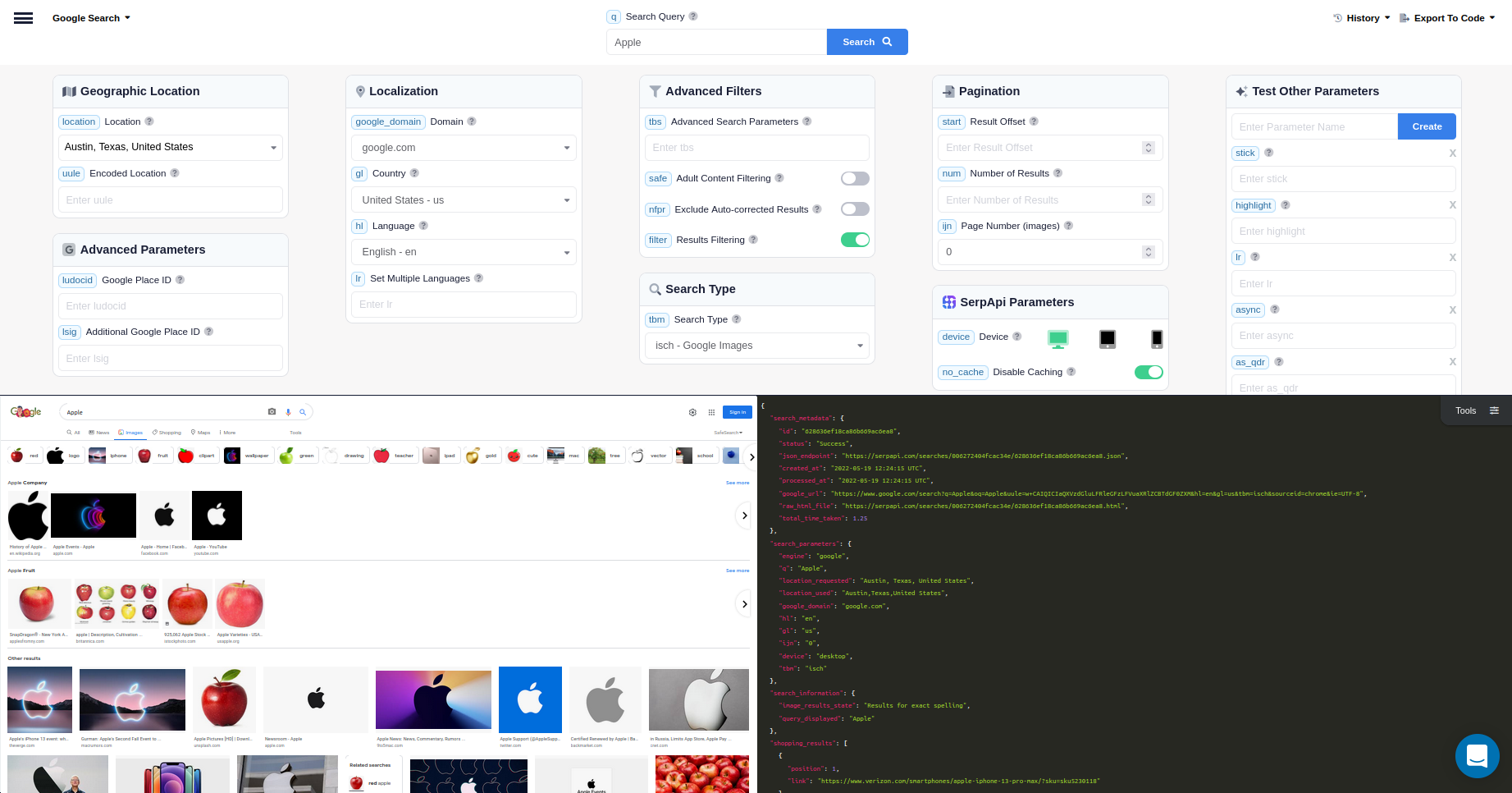
我们对 images_results 的原始键感兴趣,因为它们是下载原始大小图像的直接链接。有关引擎的更多信息,您可以访问 SerpApi 的 Google Images Scraper API](https://serpapi.com/images-results)的[文档,并探索更多选项。
让我们探索如何检查较旧的下载链接,并分离独特的结果:
https://gist.github.com/kagermanov27/21e2118941b9ea52ccf1cacbdd1b52e9
我们读取了 previous_images.json 文件并在其中查找先前的密钥。然后,最后一行确定唯一结果。
https://gist.github.com/kagermanov27/f5c1d3d052651dcbc7e0436ffb7542e4
让我们分几个步骤分解这个函数。首先,我们要定义一个下载路径:
https://gist.github.com/kagermanov27/4930dbeab6de25facef4543b9c473967
但是我们还需要检查这样的路径是否存在。例如,如果我们的查询是 Apple,我们需要一个像 datasets/test/apple 这样的文件夹才能存在。如果它不存在,我们创建一个。
让我们看看下载图像的名称选择:
https://gist.github.com/kagermanov27/6c024ced610ce1c605279c76c0ef9e8a
我们将给图像编号以保持名称的唯一性。如果还没有下载任何文件,则名称为 0。如果有,则名称将最大数加 1。
让我们看一下猜测扩展,并将图像下载到正确的路径:
https://gist.github.com/kagermanov27/9e162f06884a881f7b24926625ac1396
我们使用链接以字节形式获取图像,然后猜测图像扩展名。 Mimetype 将.webp图像猜测为html。所以我们针对这种情况做一个保障,使用我们之前生成的路径和扩展名来写镜像。
现在让我们看看如何更新我们存储的 JSON 文件,以便将来进行唯一下载:
https://gist.github.com/kagermanov27/6b4b4689135d6d71cb9f2033b1e66c05
由于每个函数都准备好了,让我们看看包含我们从添加端点调用的整个过程的函数。
https://gist.github.com/kagermanov27/c5cdb620e72bfe6f1462f27f5cc49a82
我们在此处进行了一些尝试和 except 阻止,以确保请求过程中没有意外错误。
使用 Uvicorn 运行 App
可以使用应用程序路径中的命令将 FastApi 部署在本地计算机上:
uvicorn main:app --host 0.0.0.0 --port 8000
您将看到以下提示:u200c
信息:已启动服务器进程 [14880] 信息:等待应用程序启动。信息:应用程序启动完成。信息:Uvicorn 在 http://0.0.0.0:8000 上运行(按 CTRL+C 退出)
这意味着您的服务器正在正常运行。如果你在本地机器上访问 localhost:8000,你会看到这样的结构:
{“你好世界”}
这是应用程序的主页。这将在即将发布的博客文章中形成。让我们前往 localhost:8000/docs:
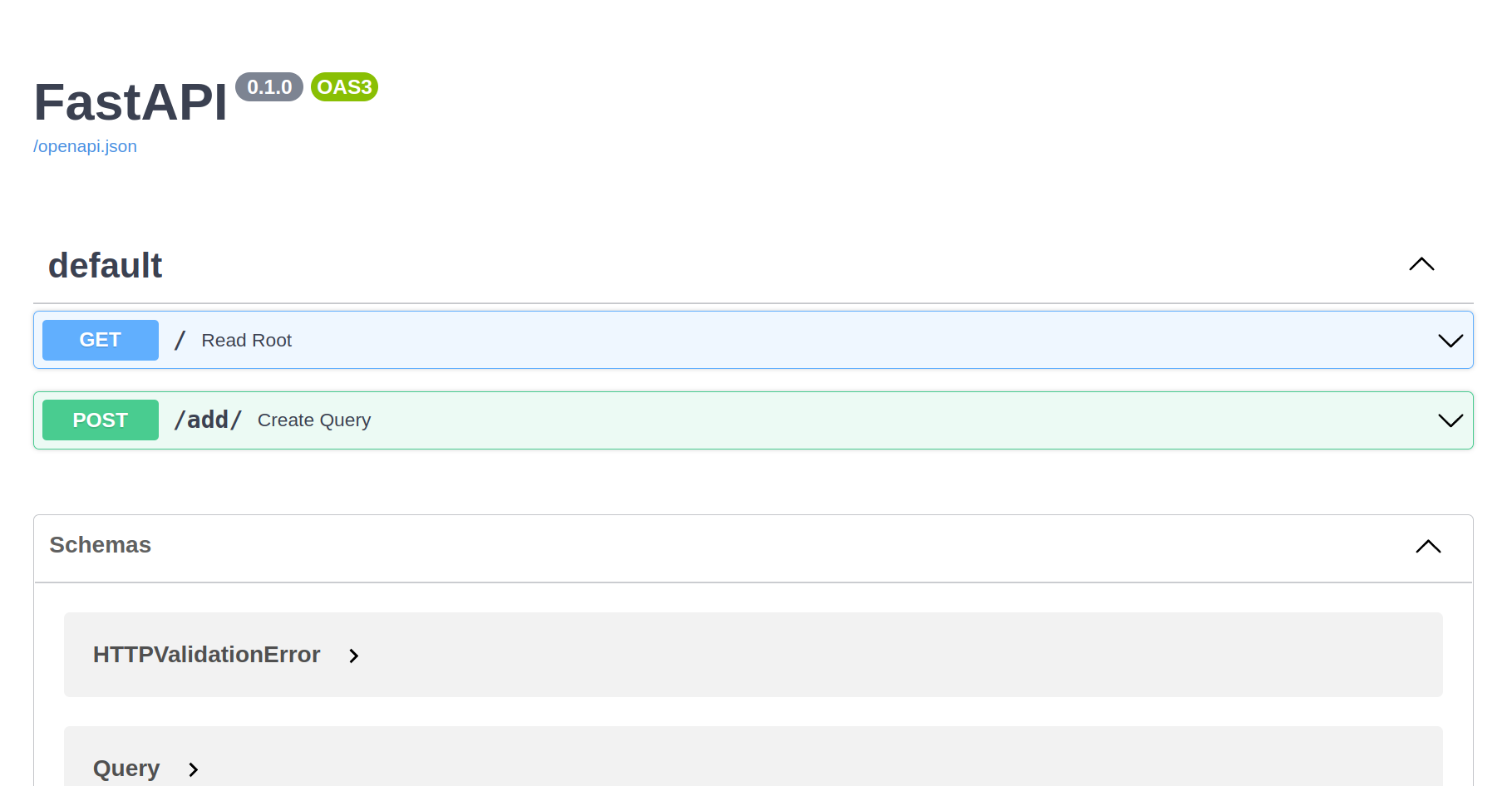
FastApi 允许应用程序的自动文档和游乐场。这对我们手动测试端点很有用。这对我们手动创建到添加端点的发布请求很有用。只需单击带有创建查询的按钮:
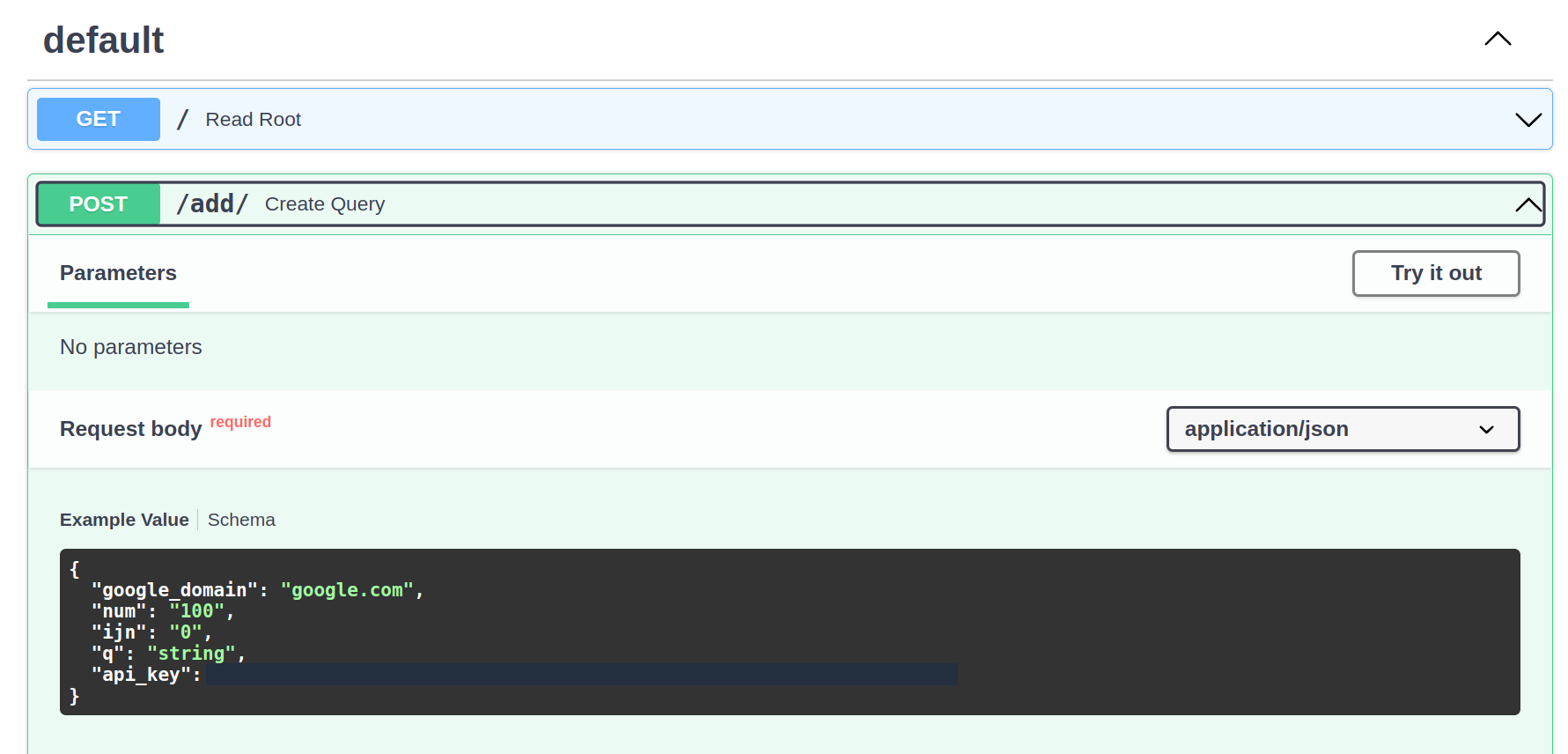
接下来,单击试用按钮:
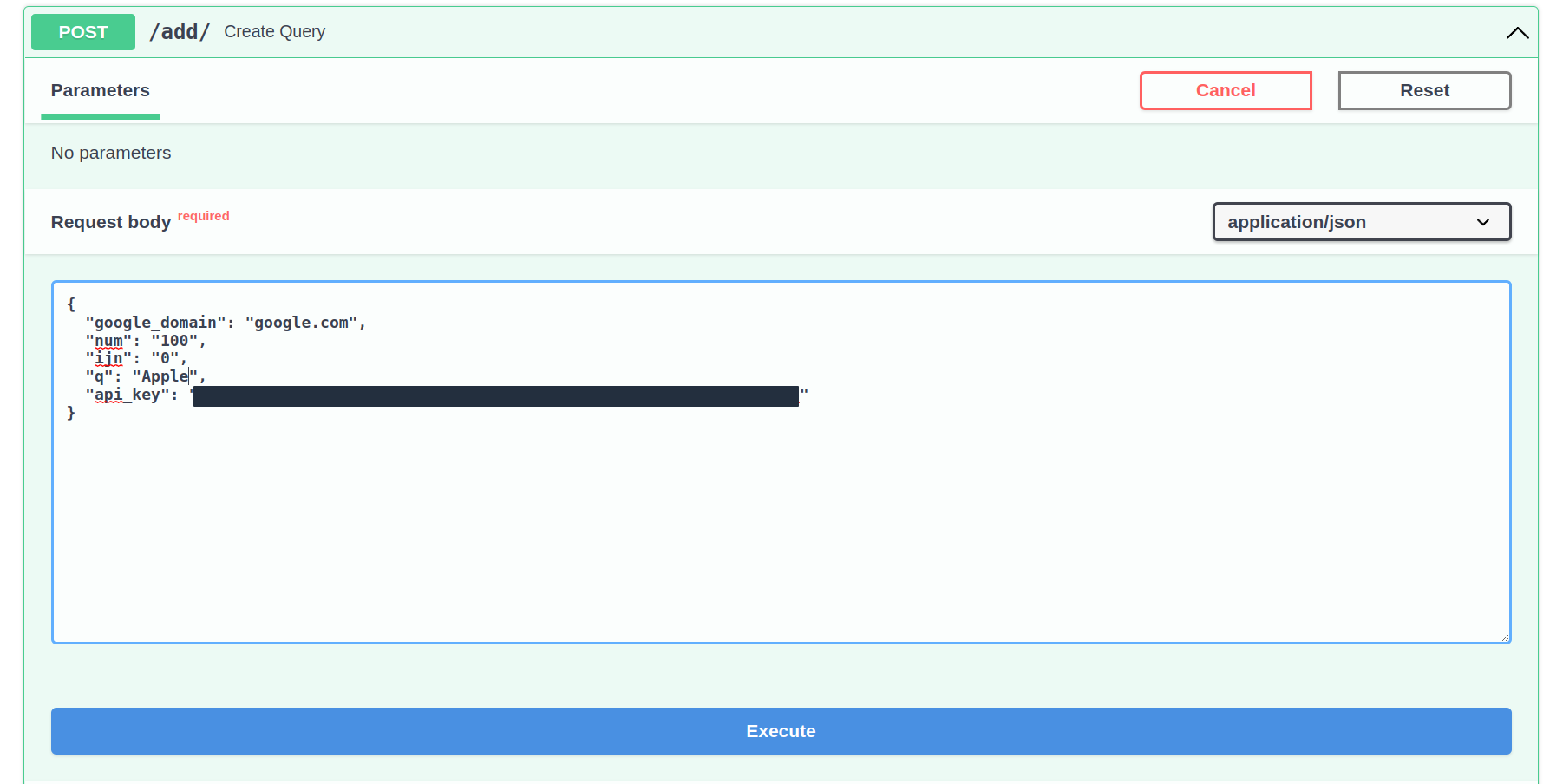
将 api_key 参数更改为您的 API 密钥,并将 q 更改为您希望用来扩展数据库的查询。
在我们按下执行之前,让我们看一下文件夹结构:
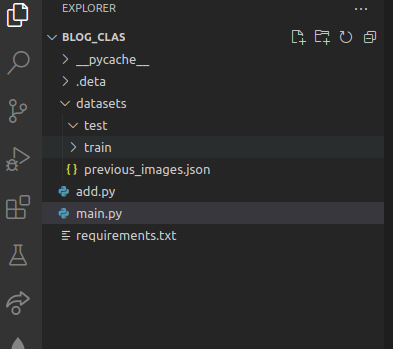
如您所见,datasets -> test 文件夹是空的,执行时它将被图像填充。
让我们在浏览器中按下 Execute 按钮,看看变化:
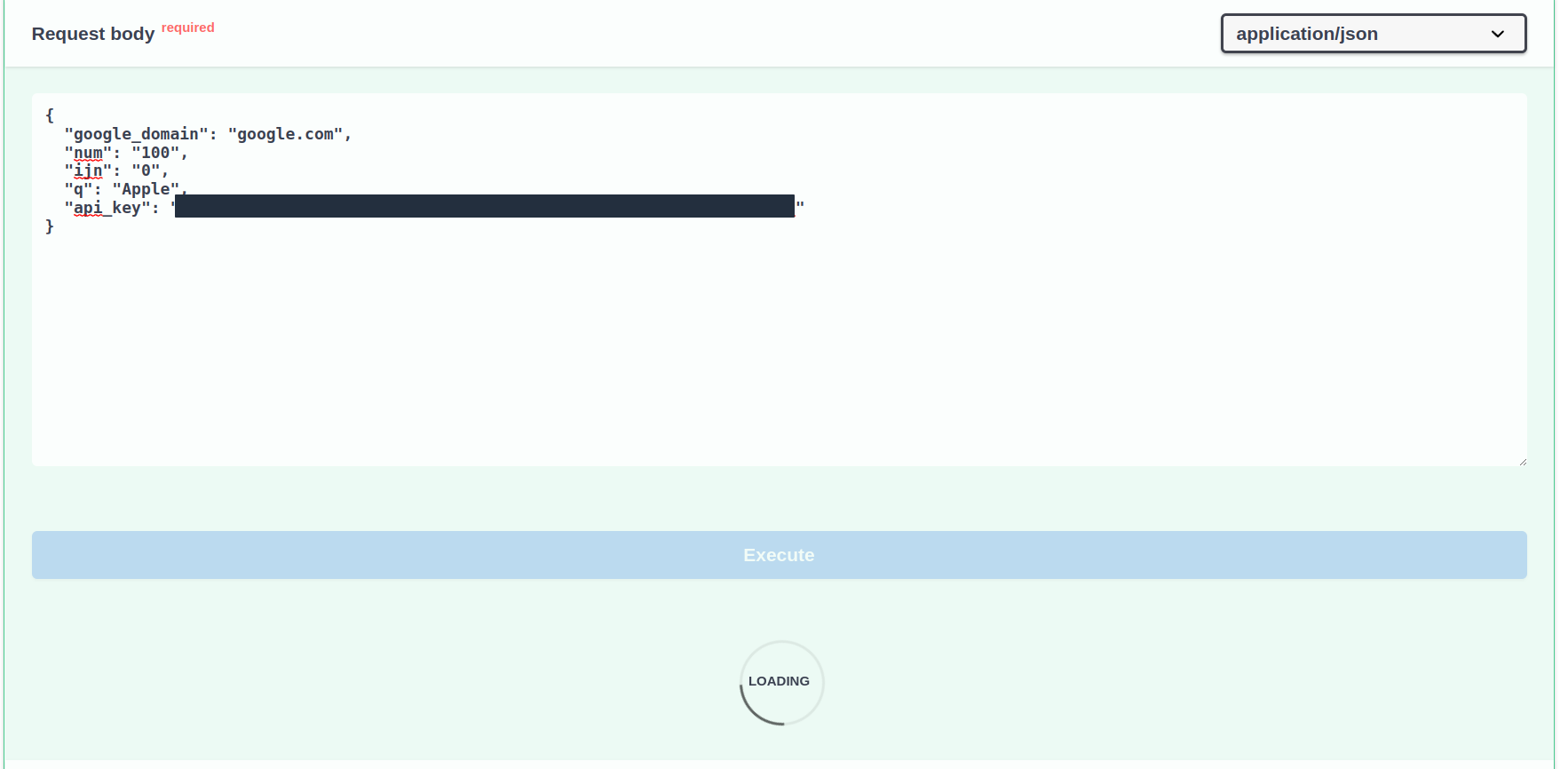
! swz 100129 swz 100130 swz 100128
您将自动在浏览器和终端中看到更改。
完成后,您可以在浏览器中观察响应:
! zwz 100132 zwz 100133 zwz 100131
您还可以前往您的文件夹以查看图像是否已更新:
! zwz 100135 zwz 100136 zwz 100134
完整代码
main.py
https://gist.github.com/kagermanov27/e5bc0e373fa6b8dbd9883870c4159db7
add.py
https://gist.github.com/kagermanov27/b3b8efcdc522cf6e193dd4c7bd15f50f
要求.txt
https://gist.github.com/kagermanov27/fefd1b18a5646d06e8e2fcd6b3bd2da3
数据集/上一个_images.json
https://gist.github.com/kagermanov27/4d390e65cb90ea800826a47e0bf4dd02
结论
对于迟到一天的读者,我深表歉意,并感谢他们的关注。本周我们介绍了如何使用 SerpApi 和 FastApi 创建可扩展的图像数据库制造商,并在 Uvicorn 上运行该应用程序。两周后,我们将探索如何添加异步进程,实现 Pytorch。我很感谢 SerpApi 的杰出人士给我这个机会。
原文发表于2022年5月19日https://serpapi.com。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)