在 Nlp 中使用 Gensim 开始主题建模
简介
由于 NLP 主题建模的一个应用被用于许多业务领域,以轻松扫描一系列文档,找到其中的单词组(主题),并自动 cluster 单词分组,这节省了时间并降低成本。
在本文中,您将学习如何使用 Gensim 实现主题建模,希望您会喜欢它,让我们开始吧。
你有没有想过要处理 100000 个文档,每个文档包含 1000 个单词有多难? ,这意味着需要 100000 1000 u003d100000000 个线程来处理所有文档。如果手动完成,这可能会很困难、时间和内存消耗,这就是 *Topic modeling 发挥作用的地方,因为它允许以编程方式实现所有这些,这就是您将在本文中学习的内容
什么是主题建模?
主题建模可以很容易地定义为统计和无监督的分类方法,它涉及不同的技术,例如潜在狄利克雷分配 (LDA) 主题模型,以轻松发现主题并识别文档中存在的这些主题中的单词。这节省了时间,并提供了一种根据主题轻松理解文档的有效方法。
主题建模有许多应用,从情感分析到推荐系统。考虑下图的其他应用程序。
主题建模的应用 -源码
现在您已经清楚地了解了主题建模的含义,让我们看看如何使用 Gensim 来实现它,但是等那里有人问Gensim 是什么?
什么是 GENSIM?
嗯,Gensim 是 generalsimilarity 的缩写形式,即来自 generating 的 Gen 和来自 similarity 的 sim,它是由 Radim Rehurek 编写的开源完全专业化的 Python 库 尽可能高效地(计算机方面)和无痛地(人类方面)表示文档向量。
Genism 旨在用于主题建模任务以从文档中提取语义主题,Genism 是您想要处理大量文本数据的工具,它使用诸如_Word2Vec_、FastText、Latent Semantic Indexing(LSI、LSA)等算法, LsiModel), Latent Dirichlet Allocation (LDA, LdaModel) 内部。

Gensim 历史 - 来源Radim Rehurek
为什么选择 GENSIM?
-
对上面提到的各种向量空间算法有高效的实现。
-
它还提供语义表示中文档的相似性查询。
-
它围绕几种流行的数据格式提供 I/O 包装器和转换器。
-
Gensim 之所以这么快,是因为它的数据访问设计和数值处理的实现。
如何在 NLP 中使用 GENSIM 进行主题建模。
我们已经到了文章的重点,所以在打开 Jupyter Notebook 的情况下,从您的计算机上喝杯咖啡,享受有趣的播放列表,准备动手操作。开始吧。
在本节中,我们将看到使用 Latent Dirichlet Allocation (LDA) 主题模型进行主题建模的 Gensim 的实际实现,
安装
这里我们必须在jupyter notebook中安装和gensim库才能在我们的项目中使用它,考虑下面的代码;
! pip install --upgrade gensim
加载数据集和导入重要库
我们将使用一个开源数据集,其中包含来自著名的澳大利亚新闻来源 ABC(澳大利亚广播公司)代理网站(ABC)的数百万个头条新闻。
数据集包含两列,即发布_日期和标题_文本列,其中包含数百万个标题。
考虑以下用于导入所需库的代码。
#importing library
import pandas as pd #loading dataframe
import numpy as np #for mathematical calculations
import matplotlib.pyplot as plt #visualization
import seaborn as sns #visualization
import zipfile #for extracting the zip file datasets
import gensim #library for topic modelling
from gensim.models import LdaMulticore
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
import nltk #natural language toolkit for preprocessing the text data
from nltk.stem import WordNetLemmatizer #used to Lemmatize using WordNet's #built-in morphy function.Returns the input word unchanged if it cannot #be found in WordNet.
from nltk.stem import SnowballStemmer #used for stemming in NLP
from nltk.stem.porter import * #porter stemming
from wordcloud import WordCloud #visualization techniques for #frequently repeated texts
nltk.download('wordnet') #database of words in more than 200 #languages

现在,我们已经成功安装了 Gensim 并将支持库导入到我们的工作环境中,如果您的 jupyter notebook 中尚未安装其他库,请考虑以下代码来安装其他库,
! pip install nltk #installing nltk library
! pip install wordcloud #installing wordcloud library
成功导入上述库后,现在让我们将 zip 数据集提取到名为 data_for_Topic_modelling 的文件夹中,如下面的代码所示;
#Extracting the Datasets
with zipfile.ZipFile("./abcnews-date-text.csv.zip") as file_zip:
file_zip.extractall("./data_for_Topic_modelling")
很好,我们已经成功解压了上面导入的 zip 文件库中的数据,还记得吗? , 现在让我们将数据加载到一个名为 data 的变量中,因为本教程的数据集有超过数百万条新闻,我们将使用 500000 行使用 Python 语言中的 ABC 头条新闻的切片技术。
考虑下面的代码来做到这一点;
#loading the data
#Here we have taken 500,000 rows of out dataset for implementation
data=pd.read_csv("./data_for_Topic_modelling/abcnews-date-text.csv")
data=data[:500000] #500000 rows taken
EDA 和处理数据
很好,在我们的变量名为 data 的数据从代码中显示出来后,我们必须检查它的样子,因此 EDA 意味着探索性数据分析,因此我们将对数据进行一些处理以确保我们为算法准备好数据集被训练,
在下面的代码中,我们使用了 .head() 函数从数据集中打印前五行,这有助于我们了解数据的结构,从而确认它是文本的。
#Checking the first columns
data.head()

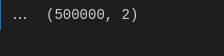
在这里,我们尝试检查数据集的 dimension 的形状,从而确认我们拥有在开始加载数据时选择的行,因此,准备就绪。
#checking the shape
#as you see there are 500000 the headline news as the rows we selected above.
data.shape
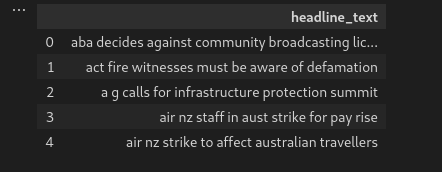
现在,我们必须使用关键字 del 从数据集中删除 publish_date 列,如下代码所示,why? 因为我们不想要它,我们的主要重点是建模根据标题新闻很多的文档的主题,我们考虑标题_text列。
#Deleting the publish data column since we want only headline_text #columns.
del data['publish_date']
#confirm deleteion
data.head()
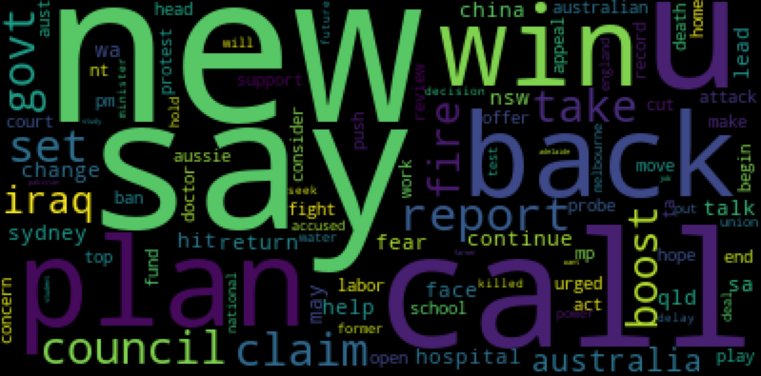
现在我们保留了我们的重要列,即如上所示的标题_文本,在这里我们现在使用 wordcloud 来查看数据集中在标题_文本列中出现频率最高的单词,这增加了更多的理解关于数据集,请考虑下面的代码
#word cloud visualization for the headline_text
wc = WordCloud(
background_color='black',
max_words = 100,
random_state = 42,
max_font_size=110
)
wc.generate(' '.join(data['headline_text']))
plt.figure(figsize=(50,7))
plt.imshow(wc)
plt.show()
在可视化数据之后,我们从 stemming 开始处理数据,这只是将一个单词简化为它的单词 stem 的过程,即词缀到后缀和前缀或词根称为**引理。示例关心关心。这里我们使用从nltk**导入的_snowballStemmer_算法,记得对吗?
考虑以下代码功能代码;
#function to perform the pre processing steps on the dataset
#stemming
stemmer = SnowballStemmer("english")
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))
然后继续 tokenize 和 lemmatize, 这里我们将标题文本中的大文本拆分成一个我们称之为标记化的小词列表,最后附加来自 lemmatize_stemming 的词形还原词 函数上面的代码到结果列表如下图;
# Tokenize and lemmatize
def preprocess(text):
result=[]
for token in gensim.utils.simple_preprocess(text) :
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
#Apply lemmatize_stemming on the token, then add to the results list
result.append(lemmatize_stemming(token))
return result
然后经过以上步骤,这里我们只调用**preprocess()**函数
#calling the preprocess function above
processed_docs = data['headline_text'].map(preprocess)
processed_docs[:10]

从 gensim.corpora 中的 'processed_docs' 创建一个字典,其中包含一个单词在训练集中出现的次数,并将其命名为字典,考虑下面的代码
dictionary = gensim.corpora.Dictionary(processed_docs)
然后,在从上面的代码中得到字典之后,我们必须实现 bags of words model (BoW),BoW 只不过是文本的表示,它显示了其中单词的出现指定的文档,这仅保留字数并丢弃文档的顺序或结构等其他内容,因此我们将创建一个名为 document_num 的示例文档并分配一个值 4310。
注意:您可以创建自己的任何示例文档,
#Create the Bag-of-words(BoW) model for each document
document_num = 4310
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
检查我们的示例文档的词袋语料库,即 (token_id, token_count)
bow_corpus[document_num]

使用来自上述词袋的 LDA(潜在狄利克雷分配)建模
我们已经到了使用 LDA 的最后一部分,它是 LdaMulticore,用于快速处理和性能来自 Gensim 的模型,以创建我们的第一个主题模型并保存它
#Modelling part
lda_model = gensim.models.LdaMulticore(bow_corpus,
num_topics=10,
id2word = dictionary,
passes = 2,
workers=2)
对于每个主题,我们将探讨该主题中出现的单词及其相对权重
#Here it should give you a ten topics as example shown below image
for idx, topic in lda_model.print_topics(-1):
print("Topic: {} \nWords: {}".format(idx, topic))
print("\n")

让我们完成性能评估,通过检查我们之前创建的测试文档属于哪些主题,使用 LDA 词袋模型,考虑下面的代码
# Our test document is document number 4310
for index, score in sorted(lda_model[bow_corpus[document_num]], key=lambda tup: -1*tup[1]):
print("\nScore: {}\t \nTopic: {}".format(score, lda_model.print_topic(index, 10)))
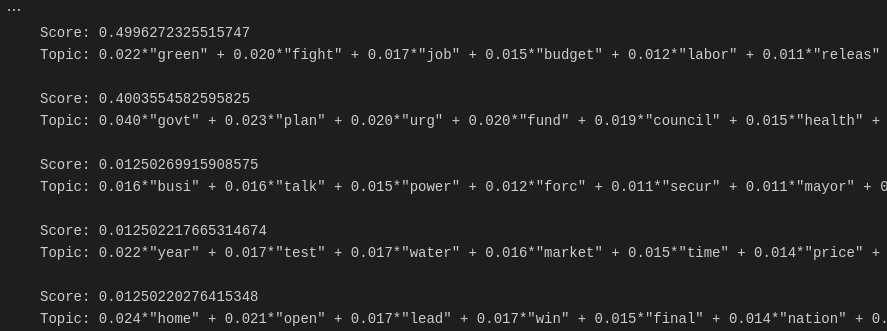
恭喜!如果您已经到达本文的结尾,正如您在上面看到的,我们已经使用 Gensim 库中的 LDA 实现了一个成功的模型,使用词袋轻松地对包含 500,000 个标题新闻的文档中的主题进行建模。使用的完整代码和数据集可以在这里找到 这里
神经技术与自然语言处理(NLP)之间的关系
当您解决业务挑战时,自然语言处理是一个强大的工具,与公司和初创公司的数字化转型相关。Sarufi和Neurotech提供有关会话 AI(聊天机器人)的高标准解决方案。使用来自经验丰富的技术专长的 NLP解决方案改善您的业务体验。
希望你觉得这篇文章有用,分享是关怀。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)