芹菜简介
几周前,我开始学习一个名为 Apache 气流 的工具。它是几家公司用来安排和监控工作流程的工具。如果您对教程感兴趣,那么您可以查看我发布的关于主题此处和此处的系列文章。在本教程中,我构建了一个从 API 获取数据并将数据保存在 SQL Server 数据库中的小项目。
使用 Celery 的气流架构
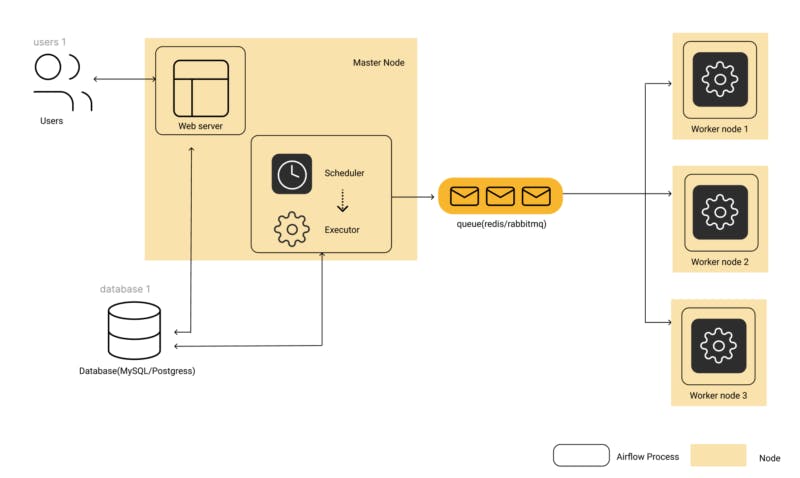
图 1:基于 Celery Executor 的配置的气流架构图
来源:https://www.qubole.com/tech-blog/understand-apache-airflows-modular-architecture/
Apache气流架构的组件之一是执行器。该组件负责执行 DAG 上指定的任务。有几种类型,例如SequentialExecutor、LocalExecutor、CeleryExecutor、KubernetesExecutor 等。在前面提到的气流教程中,我使用 celery 执行器来执行我的数据管道中的任务,因此在本文中我将讨论 celery 是什么,并提供一个基本的用例工具。本教程不是对 celery 功能的全面回顾。我建议导航到参考部分提供的 celery 文档,以全面了解该工具。在下一节中,我将简要讨论任务队列和 celery 之间的关系。
任务队列
任务队列是跨线程或机器传播工作单元的媒介。任务队列的输入是一个称为任务的工作单元。工作人员不断监视任务队列中的新任务。
Celery - 任务队列的一个示例,使用消息代理(消息队列)在客户端(工作的生产者)和工作人员(消费者)之间充当调解者,如下图 2 所示。
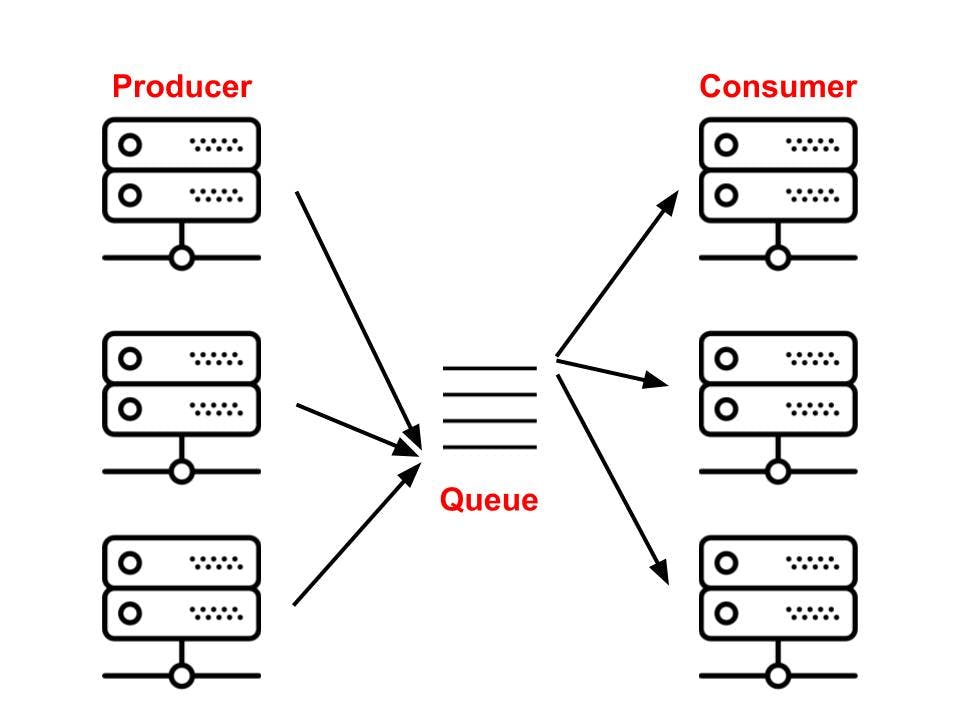
图 2:Celery 架构概述
来源:https://vinta-cms.s3.amazonaws.com/media/filer_public/e4/73/e473005f-2190-40bd-86a5-cb0b9f60a810/producer__consumer.jpg
IBM将消息代理定义为一些能够在应用程序、系统和服务之间交换信息的软件。有几种代理,包括 RabbitMQ 和 Redis。如果没有这些代理,Celery 将无法向/从 worker 发送和接收消息。在生产中,一个 celery 系统可以由几个工人和经纪人组成,这允许高可用性和水平扩展。
使用芹菜
在本节中,我将介绍如何开始使用 pythoncelery。
要求
-
Python 3.7+
-
消息代理,例如。兔MQ
-
结果后端(例如 MySQL、Redis)
-
码头工人
我们将使用在 Python 3.7 或更高版本上运行的 celery 5.2 版本。您可以使用pip安装 celery
pip install celery
消息代理可以作为服务启动,也可以使用 docker 运行。在本教程中,我使用 docker 运行 rabbitmq。您可以使用以下命令使用 docker 启动 rabbit-mq 服务。
docker run -d --hostname localhost --name some-rabbit -e RABBITMQ_DEFAULT_USER=user -e RABBITMQ_DEFAULT_PASS=password -p 15672:15672 rabbitmq:3-management
如果你使用 MacOSX 系统,你可以参考这个gist让 MySQL 与homebrew一起运行,否则,开放互联网上有一些资源可以帮助你让 MySQL 在其他平台上运行。
Celery 使用 results 后端 来保存发送到代理的任务状态。有很多后端可供选择,包括MongoDB和Redis但是在本教程中,我将使用 MySQL。
教程
满足所有先决条件后,我们可以继续我们的教程。
概述
在这个非常简单的教程中,我将设置一个 celery 应用程序实例,创建一个简单的任务并将这个任务分派给一个工作人员。本教程的灵感来自 Celery 的教程,可以在此处找到
项目布局
run_some_io_task.py
proj/__init__.py
/celery.py
/tasks.py
proj/celery.py
from celery import Celery
# app instance
app = Celery('proj', backend='db+mysql://rashid:password@localhost:3306/airflowdb', broker='amqp://user:password@127.0.0.1:5672//', include=['proj.tasks'])
if __name__ == '__main__':
app.start()
backend参数
如果您使用的是MySql,则backend参数的格式如下:
db+mysql://{user}:{password}@{server:port}/{database}
所以我们可以创建一个用户和一个密码来相应地替换参数。我使用下面的代码片段创建了一个名为“rashid”的用户,密码为“password”。
CREATE USER 'rashid'@'localhost' IDENTIFIED BY 'password'
接下来,我为我的用户授予了我之前创建的airflowdb数据库的所有权限。
GRANT ALL PRIVILEGES ON *.* TO 'airflowdb'@'localhost';
FLUSH PRIVILEGES
broker参数
broker参数的格式如下
amqp://{user}:{password}@{server}:{port}//
我之前使用名为“user”的默认用户和名为“password”的密码设置了一个 rabbit-mq 实例,因此我们需要做的就是用正确的凭据替换参数。
在celery.py模块中,我们创建了一个 Celery 实例,它有时被称为 app。我们可以通过导入这个实例在我们的应用程序中使用 celery,我们很快就会看到。
proj/tasks.py
# importing the celery instance
from .celery import app
import time
@app.task
def some_io_task(x, y):
time.sleep(10)
print("Done sleeping. Executing the add command")
return x + y
在这个模块中,我创建了一个运行大约需要 10 秒的任务。此任务模拟一些 IO 任务,例如向客户端发送付款收据,或将存储过程的结果保存在某个位置。
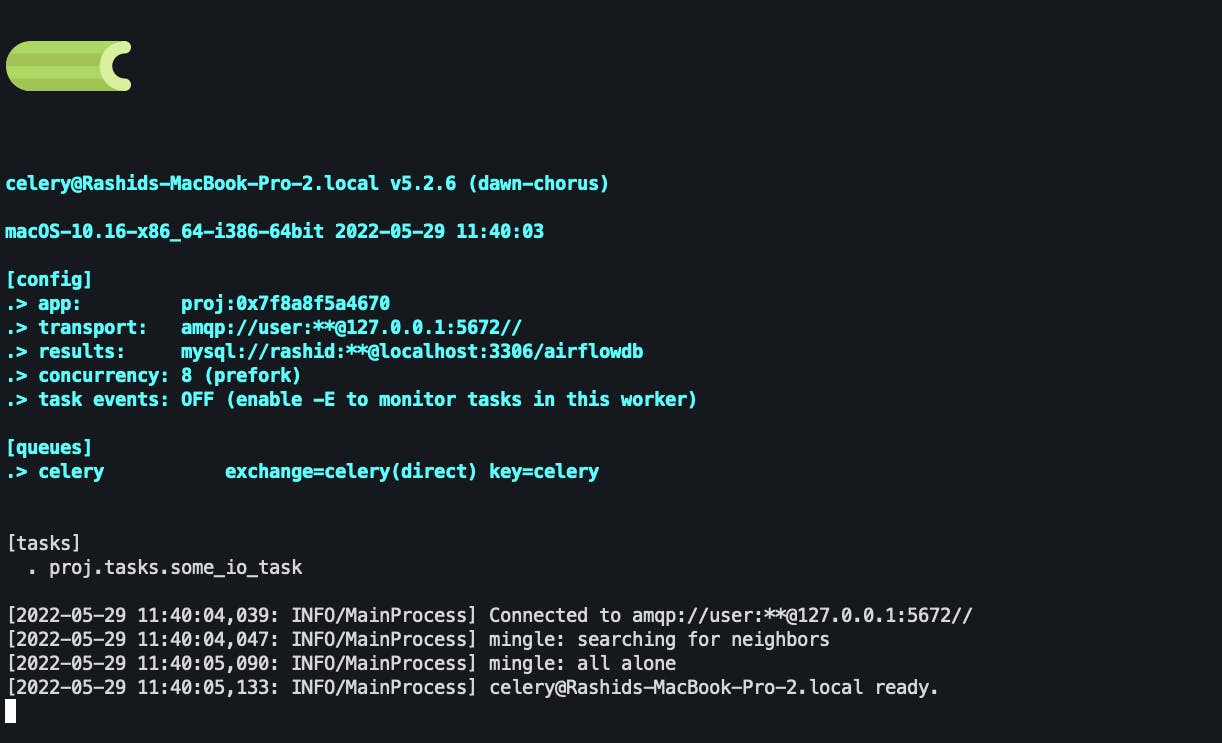
启动worker
创建 celery 应用程序实例和任务并运行代理后,我们现在可以启动一个工作程序,该工作程序将侦听任务并使用以下代码执行它们。确保在proj/目录上方的目录中执行此代码。
celery -A proj worker -l INFO
当工作人员成功启动时,您应该会看到一些消息
调用任务
您可以通过在任务上调用delay()方法来运行任务。
>>> from proj.tasks import some_io_task
>>> some_io_task.delay(2,2)
此方法是另一个名为apply_async的方法的星形参数快捷方式
some_io_task.apply_async((2,2))
apply_async允许您指定执行选项,例如运行时间或任务应发送到哪个队列等。
some_io_task.apply_async((2,2), queue='rashid_queue', countdown=10)
这会将任务some_io_task发送到名为rashid_queue的队列,并且该任务最早会在消息发送后 10 秒后执行。
任务状态
您可以通过查看任务的状态来确定任务是否成功。
>>> res = some_io_task.apply_async((2,2))
>>> res.state
'PENDING'
一个任务一次只能处于一种状态,但是它的状态可以通过多个状态进行。典型的任务将具有以下阶段
PENDING -> STARTED -> SUCCESS
您可以在此处阅读有关状态的更多信息
run_some_io_task.py
from proj.tasks import some_io_task
import time
def show_status(some_string: str) -> None:
print(f"Status: {some_string}")
if __name__ == '__main__':
# some asynchronous task
result = some_io_task.delay(2,2)
while result.state != 'SUCCESS':
time.sleep(1.5)
show_status(result.state)
在这个模块中,我们运行some_io_task任务并每隔 1.5 秒通知用户任务的状态。单次运行的输出显示在图像的右侧,而工作人员的日志显示在左侧。
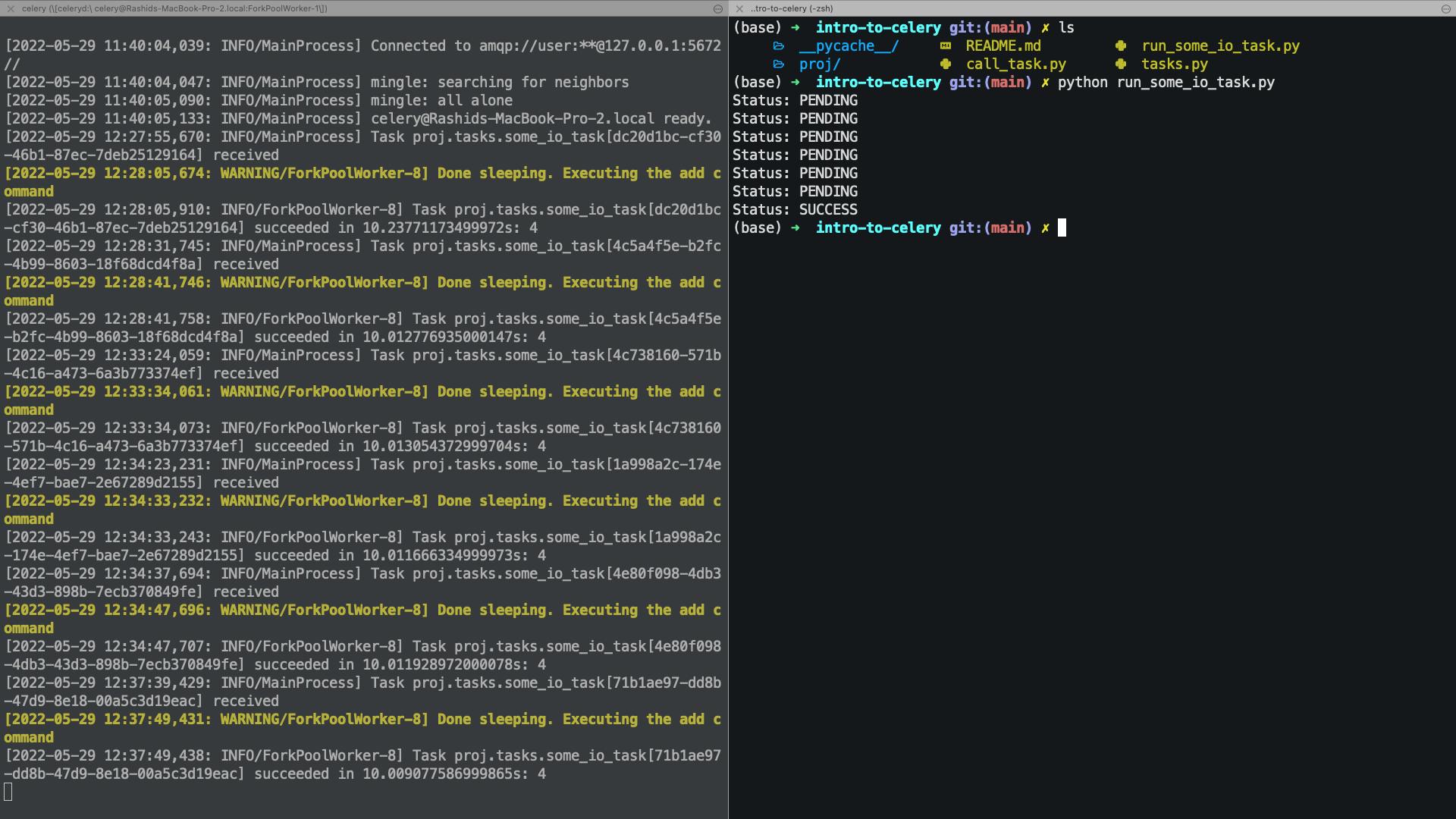
结论
在这个简短的教程中,我演示了如何启动和运行 celery。我还演示了如何将昂贵的 IO 任务发送给工作人员。最后,我演示了如何观察任务的状态并将其发送到标准输出。
参考文献
了解 Apache Airflow 的模块化架构
qubole.com/tech-blog/understand-apache-airf..
芹菜文档
docs.celeryq.dev/en/stable/getting-started/..

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)