#02 |在 Python 中将数据从 API 加载到 Pandas DataFrame
©耶稣洛佩兹 2022
问他对 Twitter 或 LinkedIn 有任何疑问
简介
下图很容易理解 API 的工作原理:
-
API 是服务员
-
接受客户的请求
-
带他们去厨房
-
稍后将“熟”响应返回给客户

统一资源定位器(URL)
URL 是我们用来在 Internet 上查找文件的地址:
-
文档:pdf、ppt、docx、...
-
多媒体:mp4、mp3、mov、png、jpeg、...
-
数据文件:csv、json、db、...
查看下面的 gif,我们在其中检查我们在定位economic.com时下载的资源。

API
应用程序接口 (API) 是客户端和服务器之间通过 URL 执行信息的通信工具。
API 定义了 URL 的工作规则。与 Python 一样,API 包含:
-
功能
-
参数
-
接受值
我们需要考虑的唯一额外知识是 tokens 的使用。
令牌是您在请求中用于验证您的身份的代码,因为大多数平台会收取费用以使用其 API。
从AlphaVantage中获取一个令牌并将其存储到 Python 变量中。
token = 'PASTE_YOUR_TOKEN_HERE'
查找 API 调用示例
在网站文档。
'https://www.alphavantage.co/query?function=TIME_SERIES_INTRADAY&symbol=IBM&interval=5min&apikey=demo'
API的响应
每次您调用 API 请求某些信息时,您稍后都会收到响应。
检查这个 JSON,一种存储 API 返回的结构化数据的文件。
如果您想了解更多关于 JSON 文件的信息,请参阅文章。
图案:
-
基础 API:
https://www.alphavantage.co/query? -
参数:
*function=TIME_SERIES_INTRADAY
*symbol=IBM
*interval=5min
*apikey=demo
API 对 Python 的数据响应
你能从 Python 请求文件吗?
import requests
api_call = 'https://www.alphavantage.co/query?function=TIME_SERIES_INTRADAY&symbol=IBM&interval=5min&apikey=demo'
requests.get(url=api_call)
>>> <Response [200]>
res = requests.get(url=api_call)
该函数返回一个对象,其中包含与API 请求和响应相关的所有信息。
res.apparent_encoding
>>> 'ascii'
res.headers
>>> {'Date': 'Mon, 18 Jul 2022 18:01:19 GMT', 'Content-Type': 'application/json', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Vary': 'Cookie', 'X-Frame-Options': 'SAMEORIGIN', 'Allow': 'GET, HEAD, OPTIONS', 'Via': '1.1 vegur', 'CF-Cache-Status': 'DYNAMIC', 'Expect-CT': 'max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"', 'Server': 'cloudflare', 'CF-RAY': '72cd1f3959323851-MAD', 'Content-Encoding': 'gzip'}
res.history
>>> []
要将响应对象放入 Python 可解释对象中,我们需要使用函数.json()来获取包含数据的字典。
res.json()
>>> {'Meta Data': {'1. Information': 'Intraday (5min) open, high, low, close prices and volume',
'2. Symbol': 'IBM',
'3. Last Refreshed': '2022-06-29 19:25:00',
'4. Interval': '5min',
'5. Output Size': 'Compact',
'6. Time Zone': 'US/Eastern'},
'Time Series (5min)': {'2022-06-29 19:25:00': {'1. open': '140.7100',
'2. high': '140.7100',
'3. low': '140.7100',
'4. close': '140.7100',
'5. volume': '531'},
...
'2022-06-28 17:25:00': {'1. open': '142.1500',
'2. high': '142.1500',
'3. low': '142.1500',
'4. close': '142.1500',
'5. volume': '100'}}}
data = res.json()
URL API 调用与数据有什么关系?
字典中的数据以 TIME_SERIES_INTRADAY 为间隔以 5 分钟 表示符号 IBM。
检查上面的字典以确认。
res.request.path_url
>>> '/query?function=TIME_SERIES_INTRADAY&symbol=IBM&interval=5min&apikey=demo'
我们可以改变什么来获取苹果股票(AAPL)的信息?
我们需要在调用 API 的 URL 中更改参数symbol的值:
stock = 'AAPL'
api_call = f'https://www.alphavantage.co/query?function=TIME_SERIES_INTRADAY&symbol={stock}&interval=5min&apikey=demo'
res = requests.get(url=api_call)
res.json()
>>> {'Information': 'The **demo** API key is for demo purposes only. Please claim your free API key at (https://www.alphavantage.co/support/#api-key) to explore our full API offerings. It takes fewer than 20 seconds.'}
为什么不显示苹果股票的信息?你怎么能解决这个问题?
API 返回一个 JSON,其中隐含地表示我们之前使用了 *demo API 密钥* 从符号 IBM 检索数据。然而,使用相同的演示 API 密钥来检索 AAPL 股票数据是不可能的。
我们应该在 API 调用中包含我们的令牌:
token
>>> 'YOUR_PASTED_TOKEN_ABOVE'
api_call = f'https://www.alphavantage.co/query?function=TIME_SERIES_INTRADAY&symbol={stock}&interval=5min&apikey={token}'
res = requests.get(url=api_call)
data = res.json()
data
>>> {'Meta Data': {'1. Information': 'Intraday (5min) open, high, low, close prices and volume',
'2. Symbol': 'AAPL',
'3. Last Refreshed': '2022-07-15 20:00:00',
'4. Interval': '5min',
'5. Output Size': 'Compact',
'6. Time Zone': 'US/Eastern'},
'Time Series (5min)': {'2022-06-29 19:25:00': {'1. open': '140.7100',
'2. high': '140.7100',
'3. low': '140.7100',
'4. close': '140.7100',
'5. volume': '531'},
...
'2022-06-28 17:25:00': {'1. open': '142.1500',
'2. high': '142.1500',
'3. low': '142.1500',
'4. close': '142.1500',
'5. volume': '100'}}}
我们可以用对象data进行绘图和数学运算吗?为什么?
data包含一个字典,它是一个非常简单的 Python 对象。
data.sum()
>>>
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Input In [46], in <cell line: 1>()
----> 1 data.sum()
AttributeError: 'dict' object has no attribute 'sum'
API 对 DataFrame 的数据响应
我们需要从这个字典中创建一个DataFrame来拥有一个强大的对象,我们可以使用它来应用许多功能。
import dataframe_image as dfi
import pandas as pd
pd.DataFrame(data=data)
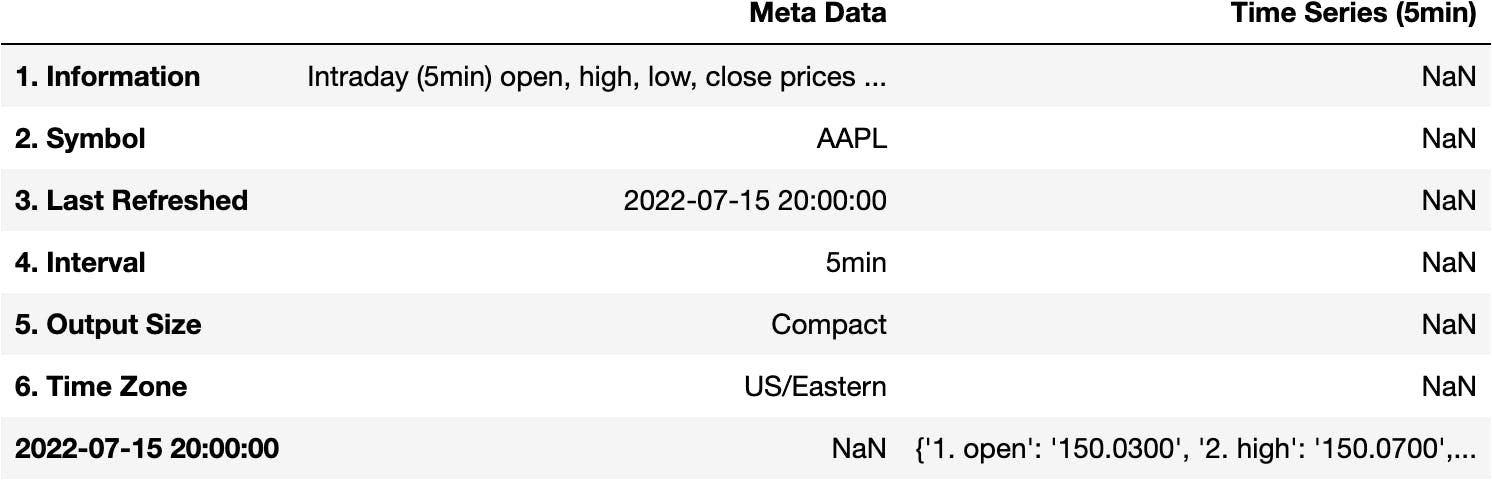
过滤响应中的信息
我们希望将 open、high、close、... 变量作为列。不是Meta Data和Time Series (5min)。为什么会这样?
-
Meta Data和Time Series (5min)是字典data的keys。 -
key
Time Series (5min)key的值就是DataFrame中我们想要的信息。
data['Time Series (5min)']
>>> {'2022-07-15 20:00:00': {'1. open': '150.0300',
'2. high': '150.0700',
'3. low': '150.0300',
'4. close': '150.0300',
'5. volume': '4752'},
...
'2022-06-28 17:25:00': {'1. open': '142.1500',
'2. high': '142.1500',
'3. low': '142.1500',
'4. close': '142.1500',
'5. volume': '100'}
pd.DataFrame(data['Time Series (5min)'])

df_apple = pd.DataFrame(data['Time Series (5min)'])
预处理DataFrame
DataFrame没有按照我们的意愿表示,因为日期在列中,变量在索引中。那么我们可以使用哪个函数来转置DataFrame呢?
df_apple.transpose()
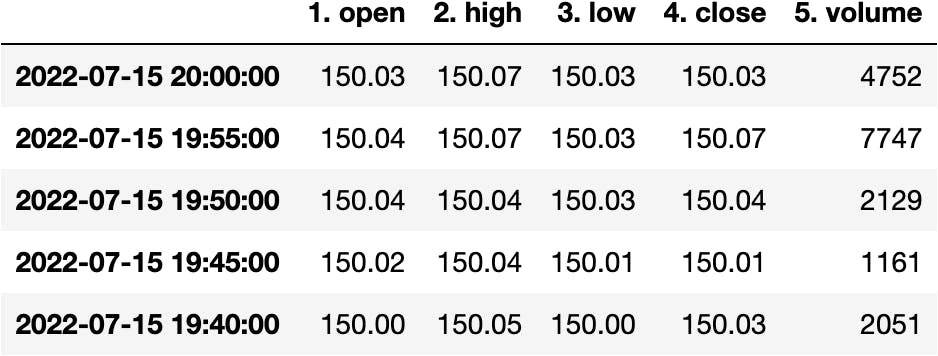
df_apple = df_apple.transpose()
让我们从收盘价中获取平均值:
df_apple['4. close']
>>> 2022-07-15 20:00:00 150.0300
2022-07-15 19:55:00 150.0700
...
2022-07-15 11:45:00 149.1500
2022-07-15 11:40:00 149.1100
Name: 4. close, Length: 100, dtype: object
df_apple['4. close'].mean()
>>>
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/nanops.py:1622, in _ensure_numeric(x)
1621 try:
-> 1622 x = float(x)
1623 except (TypeError, ValueError):
1624 # e.g. "1+1j" or "foo"
ValueError: could not convert string to float: '150.0300150.0700150.0400150.0100150.0300150.0500149.9900149.9900149.9800149.9900150.0000149.9900150.0000149.9900150.0000149.9800150.0000150.0100150.0500150.0100150.0100150.0000150.0200150.0100150.0100150.0098150.0100150.0000150.0200150.0000150.0007150.0100150.0100150.0200150.0325150.0200150.0300150.0200150.0000150.0300150.0001150.0000150.0000150.0100150.0560150.0500150.0900150.1700149.8900149.4410149.5300149.2700149.2160149.2094149.2000149.3450149.3778149.5450149.3600149.3500149.4700149.5400149.3993149.2150149.3015149.4100149.2916149.2650149.1200149.0400148.9800149.1350148.8800149.1850149.3924149.4600149.3496149.3250149.0874149.0600149.0000149.0101148.9350148.9100148.8620149.0050148.8100148.6340148.5500148.7600148.6950148.6800148.5488148.3500148.7351148.7910148.9305149.2000149.1500149.1100'
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/nanops.py:1626, in _ensure_numeric(x)
1625 try:
-> 1626 x = complex(x)
1627 except ValueError as err:
1628 # e.g. "foo"
ValueError: complex() arg is a malformed string
The above exception was the direct cause of the following exception:
TypeError Traceback (most recent call last)
Input In [38], in <cell line: 1>()
----> 1 df_apple['4. close'].mean()
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/generic.py:11117, in NDFrame._add_numeric_operations.<locals>.mean(self, axis, skipna, level, numeric_only, **kwargs)
11099 @doc(
11100 _num_doc,
11101 desc="Return the mean of the values over the requested axis.",
(...)
11115 **kwargs,
11116 ):
> 11117 return NDFrame.mean(self, axis, skipna, level, numeric_only, **kwargs)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/generic.py:10687, in NDFrame.mean(self, axis, skipna, level, numeric_only, **kwargs)
10679 def mean(
10680 self,
10681 axis: Axis | None | lib.NoDefault = lib.no_default,
(...)
10685 **kwargs,
10686 ) -> Series | float:
> 10687 return self._stat_function(
10688 "mean", nanops.nanmean, axis, skipna, level, numeric_only, **kwargs
10689 )
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/generic.py:10639, in NDFrame._stat_function(self, name, func, axis, skipna, level, numeric_only, **kwargs)
10629 warnings.warn(
10630 "Using the level keyword in DataFrame and Series aggregations is "
10631 "deprecated and will be removed in a future version. Use groupby "
(...)
10634 stacklevel=find_stack_level(),
10635 )
10636 return self._agg_by_level(
10637 name, axis=axis, level=level, skipna=skipna, numeric_only=numeric_only
10638 )
> 10639 return self._reduce(
10640 func, name=name, axis=axis, skipna=skipna, numeric_only=numeric_only
10641 )
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/series.py:4471, in Series._reduce(self, op, name, axis, skipna, numeric_only, filter_type, **kwds)
4467 raise NotImplementedError(
4468 f"Series.{name} does not implement {kwd_name}."
4469 )
4470 with np.errstate(all="ignore"):
-> 4471 return op(delegate, skipna=skipna, **kwds)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/nanops.py:93, in disallow.__call__.<locals>._f(*args, **kwargs)
91 try:
92 with np.errstate(invalid="ignore"):
---> 93 return f(*args, **kwargs)
94 except ValueError as e:
95 # we want to transform an object array
96 # ValueError message to the more typical TypeError
97 # e.g. this is normally a disallowed function on
98 # object arrays that contain strings
99 if is_object_dtype(args[0]):
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/nanops.py:155, in bottleneck_switch.__call__.<locals>.f(values, axis, skipna, **kwds)
153 result = alt(values, axis=axis, skipna=skipna, **kwds)
154 else:
--> 155 result = alt(values, axis=axis, skipna=skipna, **kwds)
157 return result
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/nanops.py:410, in _datetimelike_compat.<locals>.new_func(values, axis, skipna, mask, **kwargs)
407 if datetimelike and mask is None:
408 mask = isna(values)
--> 410 result = func(values, axis=axis, skipna=skipna, mask=mask, **kwargs)
412 if datetimelike:
413 result = _wrap_results(result, orig_values.dtype, fill_value=iNaT)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/nanops.py:698, in nanmean(values, axis, skipna, mask)
695 dtype_count = dtype
697 count = _get_counts(values.shape, mask, axis, dtype=dtype_count)
--> 698 the_sum = _ensure_numeric(values.sum(axis, dtype=dtype_sum))
700 if axis is not None and getattr(the_sum, "ndim", False):
701 count = cast(np.ndarray, count)
File ~/miniforge3/lib/python3.9/site-packages/pandas/core/nanops.py:1629, in _ensure_numeric(x)
1626 x = complex(x)
1627 except ValueError as err:
1628 # e.g. "foo"
-> 1629 raise TypeError(f"Could not convert {x} to numeric") from err
1630 return x
TypeError: Could not convert 150.0300150.0700150.0400150.0100150.0300150.0500149.9900149.9900149.9800149.9900150.0000149.9900150.0000149.9900150.0000149.9800150.0000150.0100150.0500150.0100150.0100150.0000150.0200150.0100150.0100150.0098150.0100150.0000150.0200150.0000150.0007150.0100150.0100150.0200150.0325150.0200150.0300150.0200150.0000150.0300150.0001150.0000150.0000150.0100150.0560150.0500150.0900150.1700149.8900149.4410149.5300149.2700149.2160149.2094149.2000149.3450149.3778149.5450149.3600149.3500149.4700149.5400149.3993149.2150149.3015149.4100149.2916149.2650149.1200149.0400148.9800149.1350148.8800149.1850149.3924149.4600149.3496149.3250149.0874149.0600149.0000149.0101148.9350148.9100148.8620149.0050148.8100148.6340148.5500148.7600148.6950148.6800148.5488148.3500148.7351148.7910148.9305149.2000149.1500149.1100 to numeric
为什么我们会遇到这个丑陋的错误?
Series的值不是数字对象。
df_apple.dtypes
>>> 1. open object
2. high object
3. low object
4. close object
5. volume object
dtype: object
您可以将值的类型更改为数字对象吗?
df_apple = df_apple.apply(pd.to_numeric)
现在我们将Series值作为数字对象:
df_apple.dtypes
>>> 1. open float64
2. high float64
3. low float64
4. close float64
5. volume int64
dtype: object
我们应该能够得到平均收盘价:
df_apple['4. close'].mean()
>>> 149.551566
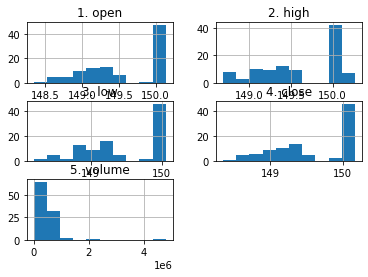
我们还能做什么?
df_apple.hist();
df_apple.hist(layout=(2,3), figsize=(15,8));
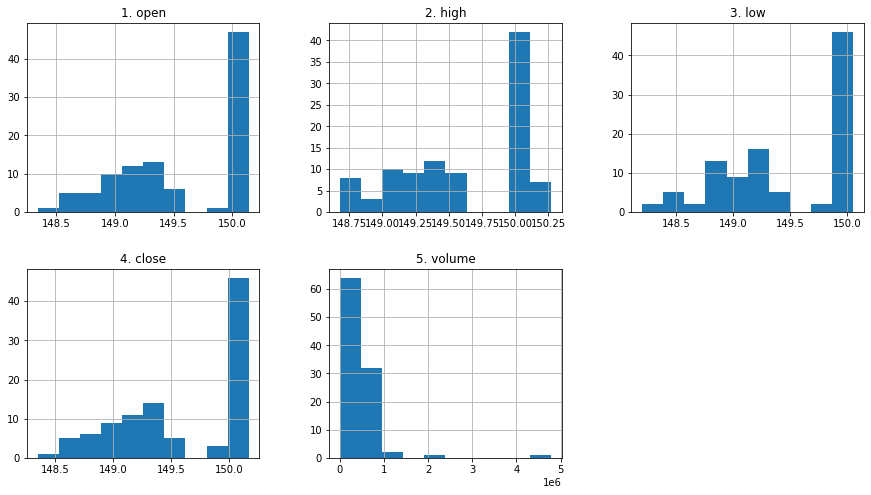
回顾
token = 'PASTE_YOUR_TOKEN_HERE'
stock = 'AAPL'
api_call = f'https://www.alphavantage.co/query?function=TIME_SERIES_INTRADAY&symbol={stock}&interval=5min&apikey={token}'
res = requests.get(url=api_call)
data = res.json()
df_apple = pd.DataFrame(data=data['Time Series (5min)'])
df_apple = df_apple.transpose()
df_apple = df_apple.apply(pd.to_numeric)
df_apple.hist(layout=(2,3), figsize=(15,8));
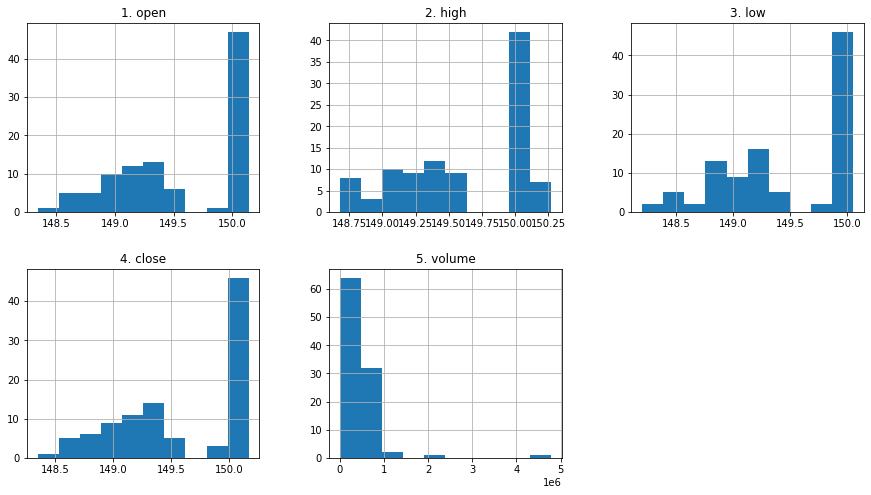
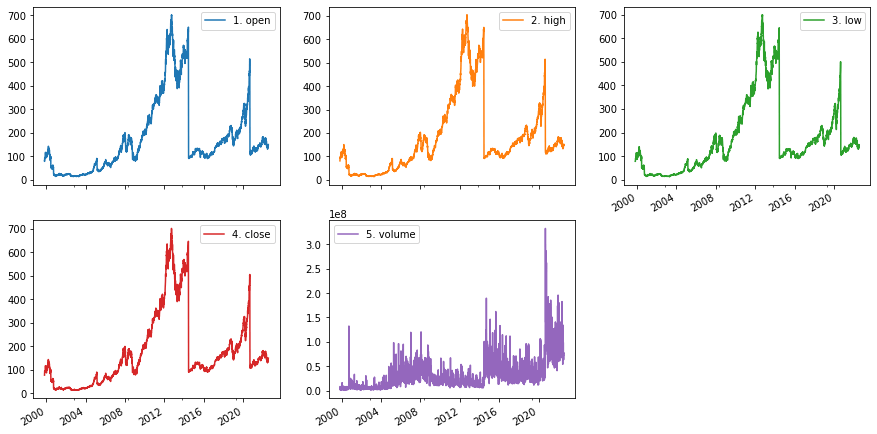
其他示例
size='full'
info_type = 'TIME_SERIES_DAILY'
api_call = f'https://www.alphavantage.co/query?function={info_type}&symbol={stock}&outputsize={size}&apikey={token}'
res = requests.get(url=api_call)
data = res.json()
df_apple_daily = pd.DataFrame(data['Time Series (Daily)'])
df_apple_daily = df_apple_daily.transpose()
df_apple_daily = df_apple_daily.apply(pd.to_numeric)
df_apple_daily.index = pd.to_datetime(df_apple_daily.index)
df_apple_daily.plot.line(layout=(2,3), figsize=(15,8), subplots=True);

本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可许可。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)