如何在 PostgreSQL 9.4+ 中将简单的 json(b) int 数组转换为 integer[]
问题:如何在 PostgreSQL 9.4+ 中将简单的 json(b) int 数组转换为 integer[]
我有一个来自 json 对象的数组:[1, 9, 12]
由于它使用方括号表示法,因为它是直接从 json 对象中获取的,所以我无法将其转换为::integer[],当我尝试使用array_agg(jsonb_array_elements(simpleintarray))时,我收到一条错误消息,提示我需要按 id 分组,但由于数组不是对象(键/value) 对,但只是简单的整数,我看不出如何以相当有效的方式实现这一点。
从 json 返回上述简单 int 数组的查询是:
SELECT node.*, elem->'permissions' AS group_node_permissions
FROM node
LEFT OUTER JOIN
jsonb_array_elements(my_user_group.node_permissions) elem
ON elem->>'id' = node.id::text
ORDER BY node.id
理想情况下,elem->'permissions'应该以{}格式的 Postgres 数组返回,这样我以后可以在其上使用ANY(intarray)函数。
我想避免做多余的低效解决方法,例如将elem->'permissions'转换为字符串,其中->>用大括号替换方括号,然后转换为整数数组,尽管这可能会起作用。
在伪代码中,我真正需要的是能够得到同样的结果:
SELECT node.*, elem->'permissions'**::integer[]** AS group_node_permissions,
...但当然由于从 json 数组到 PostgreSQL 数组格式的[]与{}的差异,这将导致错误。
这是我目前的(非常丑陋的解决方案):
SELECT node.*, replace(replace(elem->>'permissions', '[', '{'),']','}')::integer[] AS group_node_permissions
它将原来的[1, 9, 12](jsonb) 变成了{1,9,12}(integer[]) 的形式
有没有更好的解决方案?
附注
是否值得从 json(b) 转换为 int 数组 ([]),您可以在其中使用jsonarray @> '12'将数组元素获取到 Postgresinteger[]数组,您可以在其中使用12 = ANY(intarray)。有没有人知道哪个性能更高并且应该更好地扩展?现在我们可以将数组放在jsonb数据类型的列中,这是否被认为是比例如更好的方式。integer[]数据类型?
扩展信息(根据 Erwin 的要求):
SELECT DISTINCT ON (my_node.id) my_node.*
FROM user_group AS my_user_group,
LATERAL
(
SELECT node.*, elem->'permissions' AS user_group_node_permissions
FROM node
LEFT OUTER JOIN
jsonb_array_elements(my_user_group.node_permissions) elem
ON elem->>'id' = node.id::text
ORDER BY node.id
)my_node
WHERE (my_user_group.id = ANY('{2,3}')) --try also with just: ANY('{3}')) to see node 3 is excluded
AND (user_group_node_permissions @> '12' OR (user_group_node_permissions IS NULL AND 12 = ANY(my_user_group.default_node_permissions)));
DDL:
CREATE TABLE node
(
id bigserial NOT NULL,
path ltree,
name character varying(255),
node_type smallint NOT NULL,
created_by bigint NOT NULL,
created_date timestamp without time zone NOT NULL DEFAULT now(),
parent_id bigint,
CONSTRAINT node_pkey PRIMARY KEY (id)
)
WITH (
OIDS=FALSE
);
CREATE TABLE user_group
(
id serial NOT NULL,
name character varying,
alias character varying,
node_permissions jsonb,
section_ids jsonb,
default_node_permissions jsonb
)
WITH (
OIDS=FALSE
);
DML:
节点:
INSERT INTO node VALUES (1, '1', 'root', 5, 1, '2014-10-22 16:51:00.215', NULL);
INSERT INTO node VALUES (2, '1.2', 'Home', 1, 1, '2014-10-22 16:51:00.215', 1);
INSERT INTO node VALUES (3, '1.2.3', 'Sample Page', 1, 1, '2014-10-22 16:51:00.215', 2);
INSERT INTO node VALUES (4, '1.2.3.4', 'Child Page Level 1', 1, 1, '2014-10-26 23:19:44.735', 3);
INSERT INTO node VALUES (5, '1.2.3.4.5', 'Child Page Level 2', 1, 1, '2014-10-26 23:19:44.735', 4);
INSERT INTO node VALUES (6, '1.2.6', 'Test Page', 1, 1, '2014-12-01 11:45:16.186', 2);
INSERT INTO node VALUES (7, '1.2.7', 'Login', 1, 1, '2014-12-01 11:54:10.208', 2);
INSERT INTO node VALUES (8, '1.2.7.8', 'MySubPage', 1, 1, '2014-12-01 12:02:54.252', 7);
INSERT INTO node VALUES (9, '1.2.9', 'Yet another test page', 1, 1, '2014-12-01 12:07:29.999', 2);
INSERT INTO node VALUES (10, '1.2.10', 'Testpage 2', 1, 1, '2014-12-02 01:43:33.233', 2);
INSERT INTO node VALUES (11, '1.2.10.11', 'Test page 2 child', 1, 1, '2014-12-02 01:45:49.78', 10);
团体:
INSERT INTO user_group VALUES (2, 'Editor', 'editor', NULL, NULL, '{1,2,3,4,5,7,9,10,12}');
INSERT INTO user_group VALUES (1, 'Administrator', 'administrator', NULL, NULL, '{1,2,3,4,5,6,7,8,9,10,11,12}');
INSERT INTO user_group VALUES (3, 'Writer', 'writer', '[{"id": 3, "permissions": [1, 9]}, {"id": 4, "permissions": [1, 9, 12]}]', NULL, '{1,3,9,12}');
简短的介绍:
基本上我在这里做的是:
-
一个用户可以有多个组(作为整数[] 数据类型或 jsonb 数组 [] - 尚未决定,但考虑到 Erwin 的回答,整数可能是最好的,因为它不应该包含一个大数组.
-
可以为每个组分配对特定节点的特定访问权限*(参见下图,它解释了外部左连接),从而推翻了组默认的全局权限(权限“12”是浏览节点并因此获得它的能力)在查询中返回)
-
由于“writer”组确实有“12”(浏览)权限,但是id为3的节点的节点权限没有“12”权限,只有组“writer”的用户不会得到id为的节点3 在选择查询返回的结果中。但是,如果用户还有另一个组,并且不排除该节点 - 当然会返回该节点,因为更“强大”的组取代了“较弱”的组。
性能慢 - 可以优化吗?
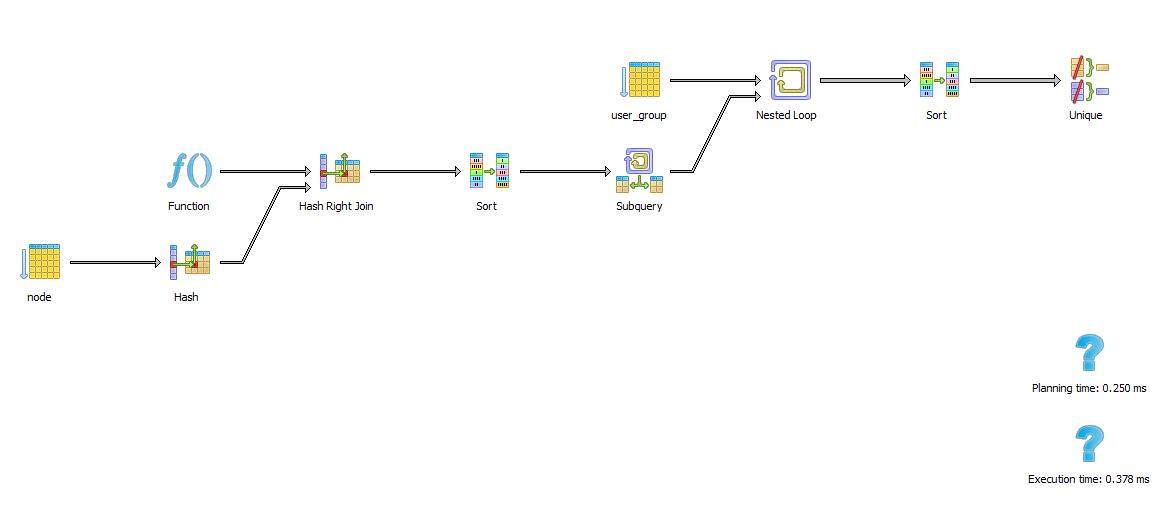
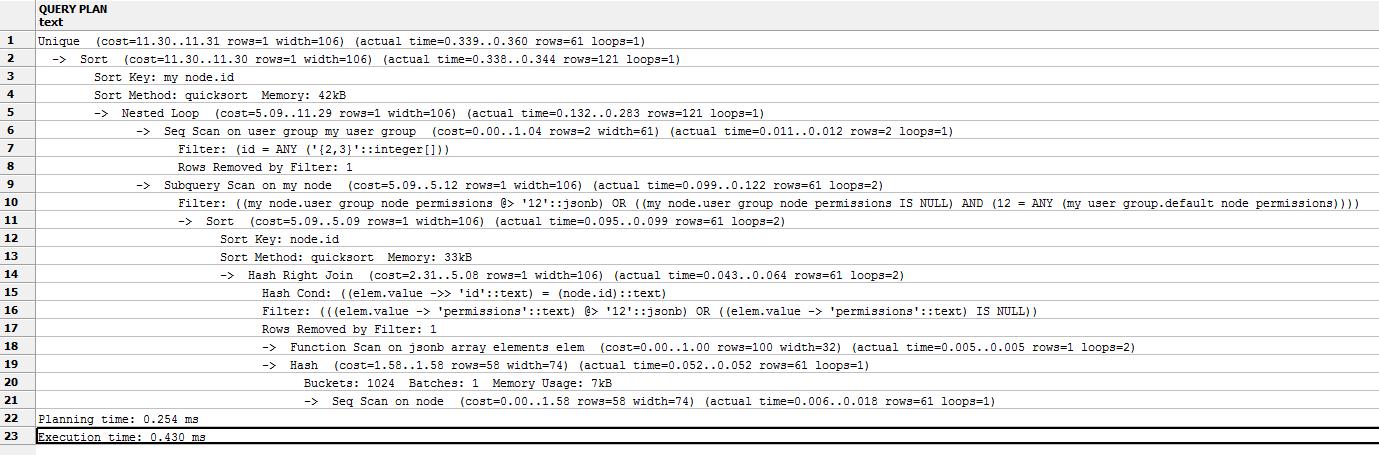
(您可以在浏览器中放大图片)
与上述相比,一个简单的 SELECT * FROM 节点执行时间为 0.046ms(再次用 EXPLAIN ANALYZE 测量)
如果您仍然可以使用更多信息,请随时询问。
解答
显然,您有一个嵌套在外部 JSON 数组中的 JSON 数组:
SELECT n.*, array_agg(p)::int[] AS group_node_permissions
FROM my_user_group u
, jsonb_array_elements(u.node_permissions) elem
JOIN node n ON n.id = (elem->>'id')::int
, jsonb_array_elements_text(elem->'permissions') p
GROUP BY n.id; -- id being the PK
- 这是假设在
permissions中没有空的 Arras。否则你需要LEFT JOIN LATERAL ... ON TRUE:
*多次调用带有数组参数的集合返回函数
- 这应该保留JSON数组的原始顺序,但不能保证。如果需要确定,请使用
WITH ORDINALITY。
*PostgreSQL unnest() 元素编号为
LEFT [OUTER] JOIN将毫无意义,因为左表列上的后面谓词无论如何都会强制[INNER] JOIN行为。
dba.SE 上的相关答案以及更多详细信息和解释:
- 如何将json数组转成Postgres数组?
根据用例的详细信息,使用 GIN 索引支持查询可能是个好主意:
- 用于在 JSON 数组中查找元素的索引
至于您的P.S.,这取决于完整的图片。除了 Postgres 数组之外的所有其他考虑因素,它通常比保存 JSON 数组的jsonb更小更快。使用 GIN 索引可以非常快速地测试元素是否存在:
jsonarray @> '12'
intarray @> '{12}'
请特别注意,变体12 = ANY(intarray)不 GIN 索引支持。手册中有详细说明。

PostgreSQL社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献19904条内容
已为社区贡献19904条内容

所有评论(0)