How to properly insert pandas NaT datetime values to my postgresql table
·
Answer a question
I am tying to bulk insert a dataframe to my postgres dB. Some columns in my dataframe are date types with NaT as a null value. Which is not supported by PostgreSQL, I've tried to replace NaT (using pandas) with other NULL type identifies but that did not work during my inserts.
I used df = df.where(pd.notnull(df), 'None') to replace all the NaTs, Example of errors that keep coming up due to datatype issues.
Error: invalid input syntax for type date: "None"
LINE 1: ...0,1.68757,'2022-11-30T00:29:59.679000'::timestamp,'None','20...
My driver and insert statement to postgresql dB:
def execute_values(conn, df, table):
"""
Using psycopg2.extras.execute_values() to insert the dataframe
"""
# Create a list of tupples from the dataframe values
tuples = [tuple(x) for x in df.to_numpy()]
# Comma-separated dataframe columns
cols = ','.join(list(df.columns))
# SQL quert to execute
query = "INSERT INTO %s(%s) VALUES %%s" % (table, cols)
cursor = conn.cursor()
try:
extras.execute_values(cursor, query, tuples)
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
print("Error: %s" % error)
conn.rollback()
cursor.close()
return 1
print("execute_values() done")
cursor.close()
Info about my dataframe: for this case the culprits are the datetime columns only.
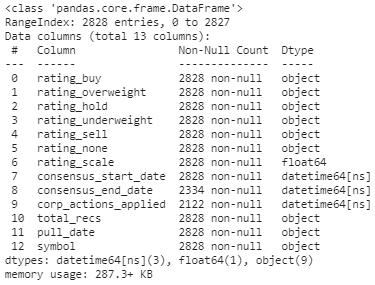
how is this commonly solved?
Answers
You're re-inventing the wheel. Just use pandas' to_sql method and it will
- match up the column names, and
- take care of the
NaTvalues.
Use method="multi" to give you the same effect as psycopg2's execute_values.
from pprint import pprint
import pandas as pd
import sqlalchemy as sa
table_name = "so64435497"
engine = sa.create_engine("postgresql://scott:tiger@192.168.0.199/test")
with engine.begin() as conn:
# set up test environment
conn.exec_driver_sql(f"DROP TABLE IF EXISTS {table_name}")
conn.exec_driver_sql(
f"CREATE TABLE {table_name} ("
"id integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY, "
"txt varchar(50), "
"txt2 varchar(50), "
"dt timestamp)"
)
df = pd.read_csv(r"C:\Users\Gord\Desktop\so64435497.csv")
df["dt"] = pd.to_datetime(df["dt"])
print(df)
"""console output:
dt txt2 txt
0 2020-01-01 00:00:00 foo2 foo
1 NaT bar2 bar
2 2020-01-02 03:04:05 baz2 baz
"""
# run test
df.to_sql(
table_name, conn, index=False, if_exists="append", method="multi"
)
pprint(
conn.exec_driver_sql(
f"SELECT id, txt, txt2, dt FROM {table_name}"
).all()
)
"""console output:
[(1, 'foo', 'foo2', datetime.datetime(2020, 1, 1, 0, 0)),
(2, 'baz', 'baz2', None),
(3, 'bar', 'bar2', datetime.datetime(2020, 1, 2, 3, 4, 5))]
"""

PostgreSQL社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献19904条内容
已为社区贡献19904条内容

所有评论(0)