pg_hint_plan 和单表基数修正
这是一篇关于 pg_hint_plan 为 PostgreSQL 查询计划器设置基数估计的小帖子。当提供正确的统计数据时,postgres 优化器可以进行很好的估计,并且这种基于成本的优化是最好的方法,因为它可以适应数据的变化。但是,对于稳定的 OLTP 应用程序,您希望保持其稳定。在查询中提供基数可能是实现这一目标的一种方式。请注意,您不需要提供确切的行数,而是提供数据访问顺序和路径的相关模型。
$ psql postgres://franck:switzerland@yb1.pachot.net:5433/yb_demo_northwind
psql (14beta1, server 11.2-YB-2.7.1.1-b0)
Type "help" for help.
yb_demo_northwind=>
进入全屏模式 退出全屏模式
这是一个我们没有统计数据的例子。我在这里使用YugabyteDB,它将分布式文档存储 (DocDB) 插入 PostgreSQL,通过外部数据包装器进行查询。我在这里过度简化了事情以保持对主题的关注。
关键是,在当前版本(YB-2.7)中,我们没有表统计信息,查询计划器使用默认的 1000 行:
yb_demo_northwind=> explain (analyze, summary false) select * from orders;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Seq Scan on orders (cost=0.00..100.00 rows=1000 width=472) (actual time=128.102..129.019 rows=830 loops=1)
(1 row)
yb_demo_northwind=> explain (analyze, summary false) select * from orders where ship_country='Switzerland';
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Seq Scan on orders (cost=0.00..102.50 rows=1000 width=472) (actual time=90.315..91.300 rows=18 loops=1)
Filter: ((ship_country)::text = 'Switzerland'::text)
Rows Removed by Filter: 812
(3 rows)
进入全屏模式 退出全屏模式
我在这里使用 EXPLAIN 与以下内容:
-
ANALYZE TRUE 运行语句并收集执行统计信息以及规划器估计
-
VERBOSE FALSE 和 Summary FALSE 以获得更小的输出来编写这个并且只关注有趣的事情
-
COST TRUE, TIMING TRUE 和 FORMAT TEXT 是默认值
-
WAL 和 BUFFERS 在这里不相关,因为 YugybyteDB 中的表和索引存储由DocDB层管理。
因此,当读取行集时,除非查询规划器由于唯一约束而知道只有一行,否则估计为:rowsu003d1000。这可能看起来太简单了,但是:
-
YugabyteDB 是新的,分布式引擎的分析和统计优化仍在积极开发中。
-
生产中的当前用户使用 OTLP 工作负载,这已经足够了(在 Oracle 工作的 20 年中,我看到几乎所有 ERP 都在 RULE 优化器模式下运行,或者使用小型优化器_index_cost_adj 来做同样的事情)
-
开发人员更喜欢控制访问路径,以避免意外,而 pg_hint_plan 允许解决可能出现问题的情况,这就是这篇博文的原因
pg_hint_plan
在 PostgreSQL 中,您必须安装 pg_hint_plan 扩展,并启用它。 PostgreSQL 社区担心它被错误地使用,并且人们不会向维护查询计划器的社区报告优化器估计错误所遇到的问题。风险在于人们只是通过提示解决问题而没有解决根本原因。即便也是开源的,Yugabyte也处于不同的位置。用户知道这个数据库是新的,处于非常活跃的开发中,并通过Slack或GitHub与我们互动。然后,可以使用提示测试不同的计划,报告问题,将提示留作短期解决方法,直到问题得到解决。除此之外,由于 YugabyteDB 是一个分布式数据库,支持轻松滚动升级,因此固定版本将易于部署而无需停机。
在 YugabyteDB 中,pg_hint_plan 默认安装并启用:
yb_demo_northwind=> show pg_hint_plan.enable_hint;
pg_hint_plan.enable_hint
--------------------------
on
(1 row)
yb_demo_northwind=> show pg_hint_plan.message_level;
pg_hint_plan.message_level
----------------------------
log
(1 row)
进入全屏模式 退出全屏模式
pg_hint_plan 扩展可以添加提示来控制计划操作(扫描或索引访问、连接顺序和方法,但也可以使用“行”提示更正基数估计。您可以将其视为 OPT_ESTIMATE Oracle 中的 () 提示。但是,在当前版本中,pg_hint_plan Rows() 提示仅对连接结果进行操作:
yb_demo_northwind=> explain (analyze, summary false) select /*+ Rows(o #42) */ * from orders o where ship_country='Switzerland';
INFO: pg_hint_plan: hint syntax error at or near " "
DETAIL: Rows hint requires at least two relations.
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Seq Scan on orders o (cost=0.00..102.50 rows=1000 width=472) (actual time=26.114..27.103 rows=18 loops=1)
Filter: ((ship_country)::text = 'Switzerland'::text)
Rows Removed by Filter: 812
(3 rows)
进入全屏模式 退出全屏模式
这显示语法错误并忽略提示。使用提示时始终查看消息并验证结果。这里我仍然有默认的 rowsu003d1000。
单表基数
我在这里写了一个快速的解决方法,它根本不令人满意。我提到它是为了短期解决方案,看看是否有人有更好的方法,或者可能会有助于 pg_hint_plan 添加这个单表基数校正。而且,无论如何,当您了解后果时,可以暂时使用丑陋的解决方法。
yb_demo_northwind=> explain (analyze, summary false)
/*+ Leading(dummy o) Rows(dummy o #42) */
select * from (select 1 limit 1) dummy, orders o where ship_country='Switzerland';
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.00..112.52 rows=42 width=476) (actual time=24.733..25.807 rows=18 loops=1)
-> Limit (cost=0.00..0.01 rows=1 width=4) (actual time=0.671..0.673 rows=1 loops=1)
-> Result (cost=0.00..0.01 rows=1 width=4) (actual time=0.001..0.001 rows=1 loops=1)
-> Seq Scan on orders o (cost=0.00..102.50 rows=1000 width=472) (actual time=23.997..25.066 rows=18 loops=1)
Filter: ((ship_country)::text = 'Switzerland'::text)
Rows Removed by Filter: 812
(6 rows)
yb_demo_northwind=> explain (analyze, summary false)
/*+ Leading(dummy o) Rows(dummy o #42) */
with dummy as (values (1))
select o.* from dummy, orders o where ship_country='Switzerland';
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.01..112.53 rows=42 width=472) (actual time=24.089..25.115 rows=18 loops=1)
CTE dummy
-> Result (cost=0.00..0.01 rows=1 width=4) (actual time=0.001..0.002 rows=1 loops=1)
-> CTE Scan on dummy (cost=0.00..0.02 rows=1 width=0) (actual time=0.004..0.005 rows=1 loops=1)
-> Seq Scan on orders o (cost=0.00..102.50 rows=1000 width=472) (actual time=24.070..25.091 rows=18 loops=1)
Filter: ((ship_country)::text = 'Switzerland'::text)
Rows Removed by Filter: 812
(7 rows)
进入全屏模式 退出全屏模式
您可以看到带有子选择和 WITH 子句 (CTE) 的两种变体。这两个都添加了一个嵌套循环,即使实际成本可以忽略不计,它也会在估计成本上增加 10。
请注意,Rows() 可以进行校正而不是绝对值。如果您将其与已具有统计信息的表一起使用,则最好调整估计成本,使其跟随表增长但保持更正。见pg_hint_plan 文档
一张表的校正可能不是很有用。但是当有进一步的加入时,它会产生巨大的变化。
这是一个例子:
yb_demo_northwind=> explain (analyze, summary false)
select o.* from orders o join order_details d using (order_id) where ship_country='Switzerland';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.00..218.88 rows=1000 width=472) (actual time=190.386..3890.738 rows=52 loops=1)
-> Seq Scan on order_details d (cost=0.00..100.00 rows=1000 width=2) (actual time=11.991..14.555 rows=2155 loops=1)
-> Index Scan using orders_pkey on orders o (cost=0.00..0.12 rows=1 width=472) (actual time=1.656..1.656 rows=0 loops=2155)
Index Cond: (order_id = d.order_id)
Filter: ((ship_country)::text = 'Switzerland'::text)
Rows Removed by Filter: 1
(6 rows)
进入全屏模式 退出全屏模式
在这里,因为没有统计信息,查询规划器估计所有行u003d1000 的表,并决定从“order_details”表开始。但是,这并不高效:读取所有订单详细信息,然后加入“订单”,然后才过滤“ship_country”。
2000 个循环需要时间,尤其是在行可能来自不同节点的分布式数据库中。我在 OCI 免费层中的一台非常小的机器上运行,我保持打开状态,因此您可以复制粘贴所有内容,包括连接字符串,然后自己测试。当然,你也可以轻松安装 YugabyteDB:https://docs.yugabyte.com/latest/quick-start
我可以添加类似 Rows(dummy o *0.2) 的提示,告诉查询规划器我对“ship_country”的过滤具有很高的选择性:
yb_demo_northwind=> explain (analyze, summary false)
/*+ Rows(dummy o *0.2) Rows(dummy d *1) */
with dummy as (values (1))
select o.* from dummy, orders o join order_details d using (order_id) where ship_country='Switzerland';
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=115.03..220.78 rows=200 width=472) (actual time=32.111..33.552 rows=52 loops=1)
Hash Cond: (d.order_id = o.order_id)
CTE dummy
-> Result (cost=0.00..0.01 rows=1 width=4) (actual time=0.001..0.002 rows=1 loops=1)
-> Seq Scan on order_details d (cost=0.00..100.00 rows=1000 width=2) (actual time=6.930..8.147 rows=2155 loops=1)
-> Hash (cost=112.52..112.52 rows=200 width=472) (actual time=25.141..25.141 rows=18 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 11kB
-> Nested Loop (cost=0.00..112.52 rows=200 width=472) (actual time=24.171..25.123 rows=18 loops=1)
-> CTE Scan on dummy (cost=0.00..0.02 rows=1 width=0) (actual time=0.003..0.004 rows=1 loops=1)
-> Seq Scan on orders o (cost=0.00..102.50 rows=1000 width=472) (actual time=24.139..25.086 rows=18 loops=1)
Filter: ((ship_country)::text = 'Switzerland'::text)
Rows Removed by Filter: 812
进入全屏模式 退出全屏模式
这里的执行速度要快得多,避免了“order_details”中的嵌套循环。您可能会惊讶地看到整个“订单_详细信息”被扫描和散列,但请记住,这是一个分布式数据库,其中该表被分片到许多平板电脑。像 Rows(dummy o #5) 这样的选择性更低,它优化了来自“订单”的 5 行,你可以从那里看到一个嵌套循环。这是由Dalibo 计划可视化器显示的,为这篇文章添加了一些颜色:
[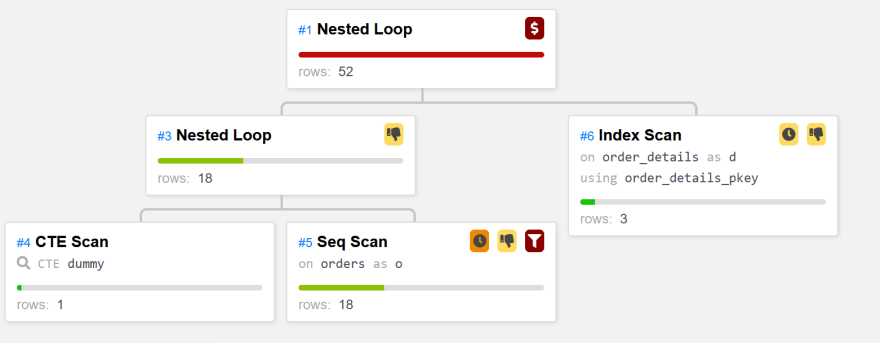 ](https://res.cloudinary.com/practicaldev/image/fetch/s--eWZZ27AB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/sk0hvrjsk92nq13ufey8.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--eWZZ27AB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/sk0hvrjsk92nq13ufey8.png)
这是正确的访问方式,除了添加这个虚拟 CTE 之外,我所要做的就是提到 20% 的未解释选择性。我还提到,从“order_details”开始时的选择性是 100%,使用 Rows(dummy d *1)。这不会改变任何东西,但重要的是要考虑查询规划器可能考虑的所有可能的连接顺序,并确保您的提示匹配所有这些。我还可以添加 Rows(dummy o d *3) 来提及每个“订单”平均有 3 个“订单_详细信息”。我也可以决定使用像 Rows(dummy o #18) Rows(dummy d #2155) Rows(dummy o d *2.5) 这样的确切数字,即使表格发生变化,也可以为连接方法保持正确的平衡决定。最后,我没有提示不以我的虚拟 CTE 开头的连接路径,因为我希望查询计划器总是从那里开始(由于 VALUE 或 LIMIT 构造,它知道只有一行)。
提醒:当查询计划程序无法正确估计基数并且您希望通过统计数据无法显示的基数和选择性知识来帮助它时,提示是解决方法。添加 CTE 是另一种解决方法。

PostgreSQL社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献19909条内容
已为社区贡献19909条内容

所有评论(0)