使用 Postgres 在 Vercel 上部署 Python API
近年来,API 改变了软件的构建方式,允许更多可重用的代码与任何软件开发工具交互。现代 API 已经获得了对开发人员友好、易于使用且被广泛理解的定义标准(通常是 HTTP 和 REST),这使开发人员更容易构建具有安全检查的可维护代码以及全面的文档。
FastAPI是一个高性能的 Python Web 框架,用于创建具有标准 Python 类型提示的 API,使您能够轻松创建快速、直观、健壮且错误更少的 Web 应用程序。此外,它还内置了对由 Swagger 提供支持的 API 文档的支持。
在本教程中,我们将通过创建一个简单的任务管理器应用程序来学习如何在 Vercel 上构建和部署 Postgres FastAPI 应用程序。接下来,请确保您为此项目克隆Github存储库。让我们开始吧!。
先决条件
本教程是一个动手演示。要继续进行,请确保您已安装以下内容:
-
弧型
-
Postgres 数据库
-
邮递员
-
蟒蛇
-
Heroku CLI
什么是 Vercel?
Vercel是一个云托管平台,被广泛认为是部署任何前端应用程序的最佳场所。 Vercel 为其全球边缘网络提供零配置部署的灵活性,从而实现动态应用程序可扩展性而不会费力。
Vercel 结合了最卓越的开发体验和对最终用户效率的高度关注,以及一系列令人兴奋的功能,例如:
-
快速刷新:为您的 UI 组件提供可靠的实时编辑体验。
-
通用数据获取:将您的页面连接到任何数据源、无头 CMS 或 API,以确保它们在每个人的开发环境中都能正常工作。
-
本地主机完美:您的所有云原语,从缓存到无服务器功能,都可以在本地主机上完美运行。
设置我们的项目
在我们深入研究之前,让我们创建我们的项目结构并安装我们的应用程序所需的依赖项。我们将从创建项目文件夹开始。打开终端并运行以下命令:
mkdir PostgresWithFastAPI && cd PostgresWithFastAPI
touch {main,database,model,schema,session}.py
进入全屏模式 退出全屏模式
在运行上面的命令并为我们的项目创建一个虚拟环境之后(我们将在下一节中介绍),我们的项目结构将如下所示:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--_l_L2XCN--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cdn.hashnode.com/res/hashnode/image/upload/v1644363227586/tnhBOQZ7P.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--_l_L2XCN--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cdn.hashnode.com/res/hashnode/image/upload/v1644363227586/tnhBOQZ7P.png)
在本教程中,我们将使用这些文件中的每一个。
创建虚拟环境
为您构建的 Python 项目创建一个虚拟环境总是好的。虚拟环境将包含您对项目的依赖项并隔离它们,从而使您的项目保持整洁。我们将使用virtualenv为这个项目创建一个虚拟环境:
pip install virtualenv
进入全屏模式 退出全屏模式
现在,通过运行以下命令创建并激活您的虚拟环境:
python3 -m venv env
source env/bin/activate
进入全屏模式 退出全屏模式
我们已经成功地为该项目创建了一个虚拟环境。还需要使用以下命令安装 Fastapi、Uvicorn、Sqlalchemy 和 psycopg2-binary:
pip install fastapi uvicorn sqlalchemy psycopg2-binary
进入全屏模式 退出全屏模式
现在运行以下命令将我们的依赖项保存在 requirements.txt 文件中。
pip freeze > requirements.txt
进入全屏模式 退出全屏模式
出色的。现在,让我们继续创建我们的 FastAPI 服务器。
创建 FastAPI 服务器
随着我们的项目设置,我们现在可以创建我们的 FastAPI 服务器。首先,打开项目根目录下的main.py文件,添加如下代码:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"message": "Server is up and running!"}
进入全屏模式 退出全屏模式
接下来,导航到终端上的项目根目录,并通过运行以下命令测试服务器:
uvicorn main:app --reload
进入全屏模式 退出全屏模式
我们添加到命令中的 --reload 标志告诉 FastAPI 监视我们的代码库上的更新,如果发现更新,则重新加载服务器。现在,向服务器发出一个 Get 请求 以确保一切都与Postman一起工作。
[
我们的服务器已成功创建并运行。接下来,我们需要一个数据库来保存我们的用户记录。让我们继续设置一个。
设置 Postgres 数据库
我们现在可以设置我们的 Postgres 数据库来使用我们的服务器设置来存储我们的用户记录。我们将使用SQLAlchemy ORM(对象关系映射器)将我们的数据库与我们的应用程序连接起来。首先,我们需要通过以下步骤创建一个数据库。首先,切换到系统的 Postgres 用户帐户。
sudo su - postgres
进入全屏模式 退出全屏模式
然后,创建一个新的用户帐户。然后,您可以按照下面的屏幕截图继续操作。
createuser --interactive
进入全屏模式 退出全屏模式
[
接下来,创建一个新数据库。您可以使用以下命令执行此操作:
createdb task
进入全屏模式 退出全屏模式
现在,我们将连接到刚刚创建的数据库。打开database.py文件,并在下面添加以下代码片段:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "postgresql://postgres:1234@localhost:5432/task"
engine = create_engine(SQLALCHEMY_DATABASE_URL)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
进入全屏模式 退出全屏模式
在上面的代码片段中,使用我们从 SqlAlchemy 导入的 create_engine 类与我们的数据库建立连接。我们还从 sessionmaker 类创建了一个 Sessionlocal 实例。我们禁用了 autocommit 和 autoflush,然后将数据库引擎绑定到会话。最后,我们从 declarative_base 类创建了一个 Base 实例,我们将使用它来创建应用程序的数据库模型和数据库连接。
创建我们的数据库模型
通过我们的 Postgres 数据库设置,让我们通过创建模型来定义如何存储用户的数据。打开model.py文件并向其中添加以下代码片段。
from sqlalchemy.schema import Column
from sqlalchemy.types import String, Integer, Text
from database import Base
class Task(Base):
__tablename__ = "Tasks"
id = Column(Integer, primary_key=True, index=True)
task_name = Column(String(20))
task_des = Column(Text())
created_by = Column(String(20))
date_created = Column(String(15))
进入全屏模式 退出全屏模式
在上面的代码片段中,我们通过导入 Column 并传递我们希望为数据库中的每个字段(Integer、String()和Text())存储的数据类型来定义我们的数据模型。
我们还导入了我们在 database.py 文件中创建的 Base 实例,该文件用于创建基本模型类。然后我们使用 tablename 属性设置我们的表名(Tasks)。为了区分存储在我们数据库表中的数据,我们将 primary_key 和 index 参数添加到我们的 id 字段并将它们设置为 true。
创建我们的数据库模式
让我们为我们的应用程序定义一个模式。我们需要定义一个Pydantic模式,它将读取数据并从 API 返回。打开Schema.py文件并向其中添加以下代码片段:
from pydantic import BaseModel
from typing import Optional
class task_schema(BaseModel):
task_name :str
task_des :str
created_by : Optional[str]= None
date_created : Optional[str]= None
class Config:
orm_mode = True
进入全屏模式 退出全屏模式
在上面的代码片段中,我们定义了模型验证,以确保来自客户端的数据与我们定义的字段的数据类型相同。我们期望我们的 task_name 和 task_des 字段的字符串值,以及 created_by 和 date_created 字段的可选字符串值。 orm_mode 设置为 True 的子类配置将指示 Pydantic 模型将数据作为字典和属性读取。
创建我们的应用程序路线
创建模式后,让我们定义应用程序的路由。首先,打开session.py文件并创建一个 create_get_session() 函数以使用以下代码片段创建和关闭我们的路由会话:
import model
from database import SessionLocal, engine
model.Base.metadata.create_all(bind=engine)
def create_get_session():
try:
db = SessionLocal()
yield db
finally:
db.close()
进入全屏模式 退出全屏模式
在上面的代码片段中,我们通过调用 model.Base.metadata.create_all() 函数并将其绑定到我们的数据库引擎,使用我们在模型中定义的字段创建了我们的表。
然后,打开 main.py 文件并使用以下代码片段导入我们所有的模块:
from fastapi import FastAPI, Depends, HTTPException
from sqlalchemy.orm import Session
from typing import List
from model import Task
from schema import task_schema
from session import get_database_session
…
进入全屏模式 退出全屏模式
接下来,使用以下代码片段创建 read_tasks 路由:
…
@app.get("/task", response_model=List[task_schema], status_code=200)
async def read_tasks(db: Session = Depends(create_get_session)):
tasks = db.query(Task).all()
return tasks
…
进入全屏模式 退出全屏模式
在上面的代码片段中,我们创建了一个 read_tasks 路由,它将监听一个 GET 请求。 我们传入了响应模型,它返回了数据库中所有任务的列表和状态代码 200 (OK)。在我们的 read_tasks 函数中,引用了我们的模型会话,这将使我们能够在数据库中执行查询。
接下来,创建一个 create_task 路由,使用下面的代码片段将新任务添加到我们的数据库中:
…
@app.post('/task', response_model = task_schema, status_code=201)
async def create_task(task: task_schema, db: Session = Depends(create_get_session)):
new_task = Task(
task_name = task.task_name,
task_des = task.task_des,
created_by =task.created_by,
datecreated = task.date_created,
)
db.add(new_task)
db.commit()
return new_task
…
进入全屏模式 退出全屏模式
在上面的代码片段中,我们创建了一个 create_task 路由,它将监听 POST 请求。这次我们的响应模型将返回刚刚创建的任务,状态码为 201(Created)。然后我们通过传递一个 item 并将其分配给我们的 Pydantic 模型从请求正文中获取数据。此外,我们从模型类中创建了一个 new_task 对象,并将请求正文中的数据传递到模型中的字段。然后我们将 new_task 对象添加到我们的数据库会话中,提交它们并返回创建的对象。
接下来,我们创建 get_task 路由,它将返回一个任务,其 id 在请求参数中指定,代码片段如下:
…
@app.get("/task/{id}", response_model = task_schema, status_code=200)
async def get_task(id:int,db: Session = Depends(create_get_session)):
task = db.query(Task).get(id)
return task
…
进入全屏模式 退出全屏模式
在上面的代码片段中,我们创建了我们的 get_task 路由,它也将监听一个 GET 请求。但这一次,我们将任务的 id 作为参数传入端点。我们的响应模型将返回一个状态码为 200(OK) 的项目对象。然后我们查询我们的数据库模型(Tasks)以获取在请求参数中指定 id 的任务并将其返回给用户。
接下来,我们将创建我们的 update_task 路由,它将监听一个 PATCH 请求,我们还传入我们的响应模型,它将返回已更新的任务对象,状态码为200(正常)。然后我们在模型中查询请求参数中指定 id 的项目,重置任务的值,将其保存到数据库,刷新数据库,并将更新的记录对象返回给用户。
…
@app.patch("/task/{id}", response_model = task_schema, status_code=200)
async def update_task(id:int, task:task_schema, db: Session = Depends(create_get_session)):
db_task = db.query(Task).get(id)
db_task.task_name = task.task_name
db_task.task_des = task.task_des
db.commit()
db.refresh(db_task)
return db_task
…
进入全屏模式 退出全屏模式
最后,我们将创建 delete_task 路由,该路由将监听 DELETE 请求并删除请求参数中指定 id 的任务并返回状态码 200 (OK )。我们将在数据库中查询该项目,如果该项目在数据库中不存在,则引发 HTTPException 错误。然后传入一个状态码404 (NOT FOUND),返回null。
@app.delete('/task/{id}', status_code=200)
async def delete_task(id:int, db: Session = Depends(create_get_session)):
db_task = db.query(Task).get(id)
if not db_task:
raise HTTPException(status_code="404",detail="Task id does not exist")
db.delete(db_task)
db.commit()
return None
进入全屏模式 退出全屏模式
有了这个,我们已经设置了所有的路线。让我们在本地测试我们的应用程序。
测试应用程序
通过我们的应用程序设置,让我们继续使用 Postman 进行测试。我们将从 Post 路线开始。
[截图](https://res.cloudinary.com/practicaldev/image/fetch/s--wrqWoIGK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://lh5.googleusercontent .com/cp3MQD5snMTRyQ4tYqNgHWiJFmFBStEhW3vrugXa1px8zSc28ImflNWtj0G9vm-sNJxyPm--VPr9hWQUW7_QHgZJ97aCmp8kKZ92YxMw4n9IznBEVsATWwTpVTDwUc5mTdpxjB5E)
接下来是 GET 路线。我们将以同样的方式对其进行测试。
[
接下来是 id 的 GET 路由。您应该看到如下所示的结果。
[
接下来是 PATCH 路线。同样,正确的响应将如下面的屏幕所示。
[
最后是 DELETE 路线。
[
一切看起来都很好。现在,让我们将我们的应用程序部署到 Vercel 上的云中。
部署到 Vercel
通过我们的路由测试,我们的应用程序已准备好部署到 Vercel 中的云。在部署应用程序之前,在 Heroku 上为项目配置远程数据库,并更新 database.py 文件中的数据库连接字符串。
SQLALCHEMY_DATABASE_URL = “Remote connection string”
进入全屏模式 退出全屏模式
然后在 Vercel 上注册帐户,并使用以下命令安装 Vercel CLI 工具:
//Ubuntu
sudo npm install vercel
//Windows
npm install -g vercel
进入全屏模式 退出全屏模式
安装完成后,使用以下命令登录 Vercel CLI:
Vercel login
进入全屏模式 退出全屏模式
上面的命令将提示您输入您要登录的身份验证帐户。做出选择,然后按 enter 键。您将被重定向到浏览器中的新选项卡,如果您看到成功消息,则表示您已成功登录到您的帐户。这意味着您现在可以从终端访问您的项目。
接下来,您需要一个配置文件来告诉 Vercel 在哪里可以找到您的 main 项目文件。在父目录中创建一个 vercel.json 文件并添加以下 JSON 代码片段:
{
"builds": [{ "src": "main.py", "use": "@vercel/python" }],
"routes": [{ "src": "/(.*)", "dest": "main.py" }]
}
进入全屏模式 退出全屏模式
在上面的代码片段中,我们创建了一个对象,该对象指示我们应用程序的 main 文件的路径。我们还在 routes 对象中声明了构建我们的应用程序时要使用的包。我们将所有路由定向到 main.py 文件。
现在,我们将使用以下命令初始化 Vercel:
Vercel .
进入全屏模式 退出全屏模式
上面的命令将提示您填写您的项目详细信息。按照下面屏幕截图中的提示执行此操作。
[
至此,我们的项目已经成功部署在 Vercel 上。您可以从链接对其进行测试。
用arctype可视化我们的数据
将我们的应用程序部署在 Vercel 上,让我们通过将数据库连接到 Arctype 来可视化数据库中的记录。要开始使用,请确保您已在计算机上下载并安装Arctype。启动 Arctype 并单击 Postgres 以创建连接。如果您需要帮助,请单击此链接。
[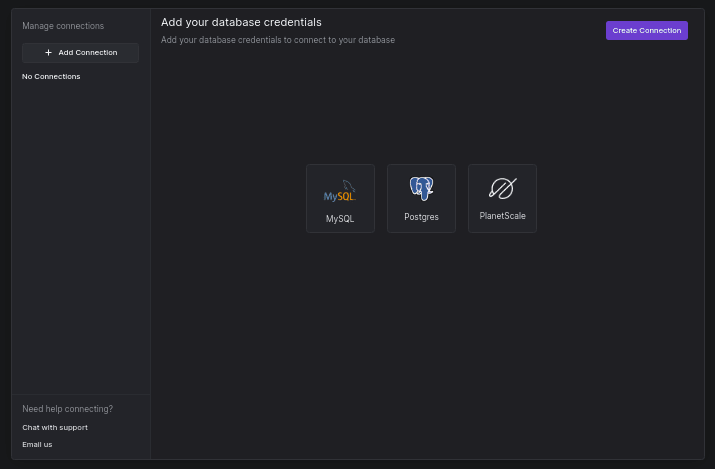
选择 Postgres 后, 添加您的数据库凭据并单击 save 按钮以连接到数据库。
[
我们已经连接到我们的远程数据库。单击 task 表以在 Arctype 上对我们的数据库运行一些查询。您可以从 Arctype 直接对数据库执行 CRUD 操作,从而产生如下所示的输出。
[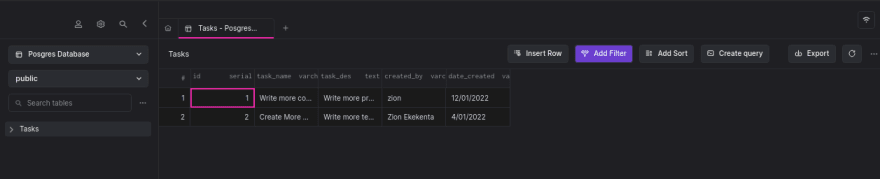 截图](https://res.cloudinary.com/practicaldev/image/fetch/s--eFn2WwA1--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype.com /blog/content/images/2022/02/Screenshot-from-2022-02-04-20-15-40.png)
截图](https://res.cloudinary.com/practicaldev/image/fetch/s--eFn2WwA1--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype.com /blog/content/images/2022/02/Screenshot-from-2022-02-04-20-15-40.png)
Arctype 是一个强大的 SQL 客户端,具有高级协作和数据可视化工具。一定要尝试并尝试找到研究应用程序数据的最佳方法。
结论
在本教程中,您学习了如何在 Vercel 上构建和部署 Postgres FastAPI 应用程序。我们从 Vercel 和 FastAPI 的简要概述开始。然后我们创建了一个 FastAPI 服务器,设置了一个 Postgres 数据库,将应用程序连接到 Postgres,执行 CRUD 操作,并使用 Arctype 可视化数据。
现在您已经掌握了这些知识,您打算如何构建下一个 FastAPI 应用程序?也许您可以从他们的网站上了解更多关于FastAPI和Arctype的信息,并将您学到的知识作为您下一个项目的灵感。请随时联系Twitter并分享您的进度和问题。

PostgreSQL社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献19909条内容
已为社区贡献19909条内容

所有评论(0)