使用 Postgres 更快地计数
计数查询可能是关系数据库中最常用的聚合查询。计数是许多 CRUD 应用程序(如排序、分页和搜索)所需的基本操作。但是随着数据集的增长,计数记录可能会变得非常缓慢。幸运的是,有一些策略可以解决这个问题。本文将向您展示一些方法。
数据设置
由于我们只是在探索计数查询,因此我们不需要大量的数据设置。我们可以创建一个只有一列的简单表。您可以使用以下命令执行此操作:
CREATE TABLE sample_data (id int);
INSERT INTO sample_data SELECT generate_series(1, 200000);
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--LKVztTWs--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype.com /blog/content/images/2022/03/Arctype_Count_Article_1.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--LKVztTWs--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype.com /blog/content/images/2022/03/Arctype_Count_Article_1.png)
简单计数查询
让我们了解一个简单计数查询的查询计划。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--IGUM1M7V--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype. com/blog/content/images/2022/03/Arctype_Count_Article_2.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--IGUM1M7V--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype. com/blog/content/images/2022/03/Arctype_Count_Article_2.png)
这在桌子上运行了一个基本的Seq Scan。如果您不熟悉阅读查询计划,那么我强烈建议您阅读下面链接的文章:
[

](/rettx)[
PostgreSQL 查询计划剖析
Arctype Team ・ 21 年 4 月 10 日 ・ 10 分钟阅读
#postgres #数据库 #sql
](/rettx/anatomy-of-a-postgresql-query-plan-4fp2)
要大致了解Scans,您可能还会发现这篇文章很有帮助:
[

](/arctype)[
在 PostgreSQL 中分析扫描
Arctype 团队为 Arctype ・ 21 年 10 月 21 日 ・ 5 分钟阅读
#guide #postgres #schema #database
](/arctype/analyzing-scans-in-postgresql-djo)
并行处理计数
PostgreSQL 不使用并行处理,因为行数太少,并且使用并行工作器可能会减慢计数过程。让我们在示例表中插入更多数据,让 PostgreSQL 能够使用更多工作人员。
INSERT INTO sample_data SELECT generate_series(200000, 4000000);
SET max_parallel_workers_per_gather = 4;
进入全屏模式 退出全屏模式
然后尝试分析一下方案,如下图:
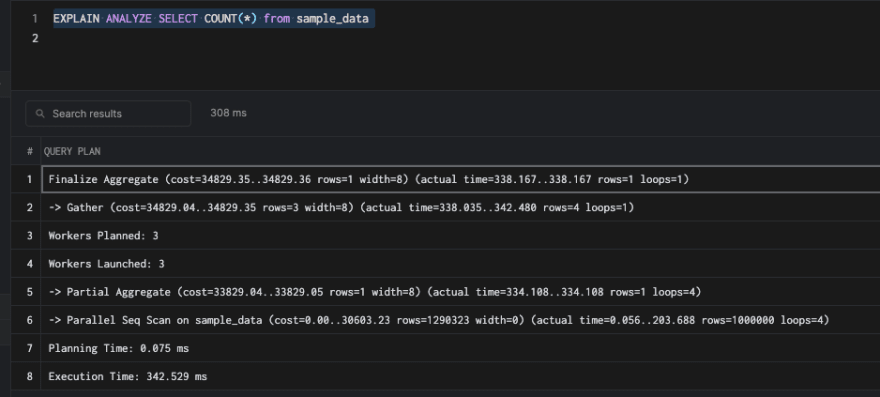
这使用了我们配置的四个工人中的三个。并行查询是显而易见的。他们只是在问题上投入硬件以实现更快的查询执行。但是在事务数据库中,我们不能简单地依赖并行查询——正如你在这个例子中看到的,它仍然需要342毫秒。
为什么索引对普通count没有帮助
任何数据库用户都会做的第一件事就是添加索引以加快查询速度。让我们在这里试试。
CREATE INDEX id_btree ON sample_data USING BTREE(id)
进入全屏模式 退出全屏模式
与其他查询不同,索引在这里没有帮助。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--n99GqyeZ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype. com/blog/content/images/2022/04/Arctype_Count_Article_4.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--n99GqyeZ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype. com/blog/content/images/2022/04/Arctype_Count_Article_4.png)
这是因为计数必须触及表格的所有行。如果有where子句,则索引会有所帮助,否则,扫描索引会很慢。我们可以理解,当我们关闭Seq scan时。
SET enable_seqscan = OFF;
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--inD_-SLD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// arctype.com/blog/content/images/2022/04/Arctype_Count_Article_5.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--inD_-SLD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// arctype.com/blog/content/images/2022/04/Arctype_Count_Article_5.png)
BTree 数据结构中的节点计数需要O(n),其中n是行数,并且还需要额外的内存 -O(h),其中h是树的高度。直接访问索引也会增加访问成本,因此对普通元组/表数据进行顺序扫描是可取的。
使用Where子句计数
一旦涉及到where子句,那么规划器就很容易使用索引,因为它会从结果中减少很多行。让我们考虑一个完整索引和一个部分索引。
全索引
由于我们已经有一个完整的索引,在id列上使用where子句的计数查询会非常快。
SELECT COUNT(id) FROM sample_data WHERE id = 200000
进入全屏模式 退出全屏模式

部分索引
如果我们要仅使用特定的where子句计算行数,那么我们可以使用部分索引。
CREATE INDEX id_btree ON sample_data USING BTREE(id) WHERE id = 200000;
进入全屏模式 退出全屏模式

部分索引更快,由于它们的大小更易于缓存,并且更易于维护。
不同计数与重复计数
默认情况下,count查询会计算所有内容,包括重复项。让我们来谈谈distinct,它经常与 count 一起使用。
SELECT DISTINCT(id) FROM sample_data
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--S_e0a-sw--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype.com /blog/content/images/2022/04/Arctype_Count_Article_8.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--S_e0a-sw--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://arctype.com /blog/content/images/2022/04/Arctype_Count_Article_8.png)
此命令使用仅索引扫描,但仍需要大约 3.5 秒。速度取决于许多因素,包括基数、表的大小以及索引是否被缓存。现在,让我们尝试计算表中唯一行的数量。
SELECT COUNT(DISTINCT(id)) FROM sample_data
进入全屏模式 退出全屏模式
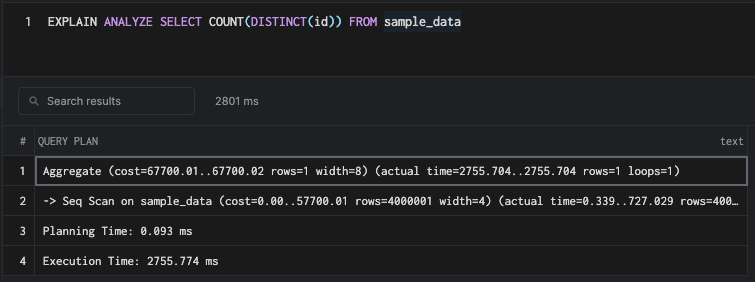
此命令不使用索引并诉诸顺序扫描。作为规划者,您选择顺序扫描是正确的,因为完全遍历索引的成本更高,正如我们在上面已经看到的那样。
关系数据库系统的经验法则是永远不要处理distinct个查询。我们永远无法完全摆脱distinct,但是通过适当的数据库建模(将重复的行移动到不同的表并使用一对多关系、单独存储唯一计数等),带有where子句的查询会更快.
近似计数
在大多数实际用例中,我们永远不需要表的确切行数。我们可能想用where子句(可以用索引解决)来计算特定的行数,但从不计算完整的行数。典型的 OLTP 工作负载一天不会增加一百万行。可能有几千行分布在不同的时间窗口中。 PostgreSQL 中有一些方法可以获得近似的行数而不是实际的行数,并且仍然可以满足业务用例。
使用统计数据获得近似计数
PostgreSQL 中基于成本的查询计划器使用统计信息来计划查询。我们可以利用这些信息来给出近似的行数。
SELECT
reltuples::bigint AS estimate
FROM
pg_class
WHERE
oid = 'public.sample_data' ::regclass;
进入全屏模式 退出全屏模式
这将返回行计数为4000001。我们还可以运行全计数查询来验证此行计数是否准确。这在生产工作负载中可能不准确,具体取决于VACCUM ANALYZE的运行时间。我们将在下一节中看到这一点。
使统计数据保持最新
讨论Vaccuum进程的内部结构超出了本博客的范围,但对于大多数 OLTP 工作负载,默认的Auto Vacuum设置可以正常工作。如果表上有任何巨大的数据负载,如果需要,我们可以手动执行Vacuum Analyze <table_name>。Vacuum进程按照它的名字命名。它使用最新和最准确的信息清理和更新统计表。
重新思考问题和外部解决方案
保持准确的表计数不一定是单独的数据库问题。可以使用各种其他方式来保持计数。让我们通过几个简单的想法。
在应用程序级别使用缓存
如果应用程序是一个简单的两层应用程序,只有 UI 和某种形式的后端,那么我们可以使用缓存层,例如EH Cache或缓存工具来维护插入时的行数它。这些缓存可以由持久性支持,这样数据就不会丢失。缓存是轻量级的并且非常快。或者,可以将计数存储在数据库本身中。这种方法的关键特性是更新计数的触发器是应用程序的责任。
在触发器/挂钩的帮助下使用变量。
如果您不熟悉钩子或触发器,这些文章将为您提供理解它们的良好起点:
[
](/arctype)[
Hooks:为 Postgres 生态系统提供动力的秘密功能
Arctype Team for Arctype ・ 3 月 11 日 ・ 7 分钟阅读
#programming #postgres #tutorial #productivity
](/arctype/hooks-the-secret-feature-powering-the-postgres-ecosystem-3p0p)
[

](/arctype)[
触发警告! SQL 触发器完整指南 - 在 Postgres 中设置数据库跟踪
Daniel Lifflander for Arctype ・ 21 年 1 月 13 日 ・ 10 分钟阅读
#sql #postgres #数据库
](/arctype/trigger-warning-a-complete-guide-to-sql-triggers-setting-up-db-tracking-in-postgres-14)
使用触发器或钩子,我们可以在 Postgres 表中或系统外部维护变量。选择此策略取决于您的数据库的设置方式,并且通常适用于具有大量下游系统供使用的应用程序。一般来说,触发器或钩子更可靠,适用于更复杂的应用。
类似Redis的缓存
在许多服务与数据库通信的微服务架构中,存储许多表的所有行计数相关信息将成为瓶颈,因为可能存在数百个微服务和大量数据库。它也可能导致与同步相关的问题。
[
](/arctype)[
为微服务世界构建数据库系统
Arctype 团队 Arctype ・ 21 年 8 月 5 日 ・ 11 分钟阅读
#guide #数据库
](/arctype/architecting-database-systems-for-the-microservices-world-4k4g)
Redis是一个适合这种 N-Tier 架构的系统。这是:
-
快。
-
线程安全
-
可扩展(使用分片)
-
持久(可启用)
所有单个服务都可以根据Saga 模式或API 组合模式调用Redis来更新值。
它在微服务领域被广泛用作缓存,但我们必须记住,将更多的外部系统引入图片会导致学习曲线、维护和故障排除的增加。如果您没有复杂的 N 层系统,那么您最好使用更简单的解决方案。
结论
我们详细了解了 count 和 distinct 查询是如何在表面下运行的,以及如何使它们变得更快。总结一下:
-
如果您需要相当准确的计数,请选择近似计数。
-
顺序扫描非常慢并且对数据库造成压力。
-
并行扫描可用于加速顺序扫描。
-
使用完整索引或部分索引可以更快地计数特定用例。
-
外部解决方案如果维护计数的用例要求很高,则可以使用。

PostgreSQL社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献19902条内容
已为社区贡献19902条内容

所有评论(0)