我们如何使用 TimescaleDB 2.7 在 PostgreSQL 上更好更快地进行数据聚合
时间序列数据是当今几乎每个行业的分析革命的命脉。对于应用程序开发人员和数据科学家来说,最困难的挑战之一是有效地聚合数据,而不必总是查询数十亿(或数万亿)的原始数据行。多年来,开发人员和数据库创建了许多解决此问题的方法,通常类似于以下选项之一:
预先聚合数据并将其存储在常规表中的 DIY 流程。 虽然这提供了很大的灵活性,特别是在索引和数据保留方面,但开发和维护很麻烦,尤其是决定如何使用数据跟踪和更新聚合迟到或过去已更新。
提取转换和加载 (ETL) 流程以进行长期分析。 即使在今天,由于创建和维护完美流程的持续开销,开发团队仍使用专门管理数据库和应用程序的 ETL 流程的整个团队。
物化视图。 虽然这些视图灵活且易于创建,但它们是聚合数据的静态快照。不幸的是,开发人员需要在所有当前实现中使用 TRIGGER 或类似 CRON 的应用程序来管理更新。除了极少数数据库之外,所有历史数据每次都会被替换,从而防止开发人员在每次刷新数据时丢弃较旧的原始数据以节省空间和计算资源。
大多数开发人员选择其中一条路径,因为我们通常很难了解到,在相同的原始数据上运行报告和分析查询,一个又一个请求,在重负载下表现不佳。事实上,大多数原始时间序列数据在保存后不会发生变化,因此这些复杂的聚合计算每次都会返回相同的结果。
事实上,作为一名长期的时间序列数据库开发人员,我也使用了所有这些方法,这样我就可以管理历史汇总数据,从而使报告、仪表板和分析更快、更有价值,即使在大量使用的情况下也是如此。
我喜欢客户开心的时候,即使这意味着在幕后需要大量工作来维护这些数据。
但是,我一直希望有一个更直接的解决方案。
**
TimescaleDB 如何改进 PostgreSQL 中聚合数据的查询
**
2019 年,TimescaleDB 引入了连续聚合来解决这个问题,使海量时间序列数据的持续聚合变得简单灵活。作为一名希望构建更具可扩展性的时间序列应用程序的 PostgreSQL 开发人员,这个特性首先引起了我的注意——正是因为我长期以来一直在努力做到这一点。
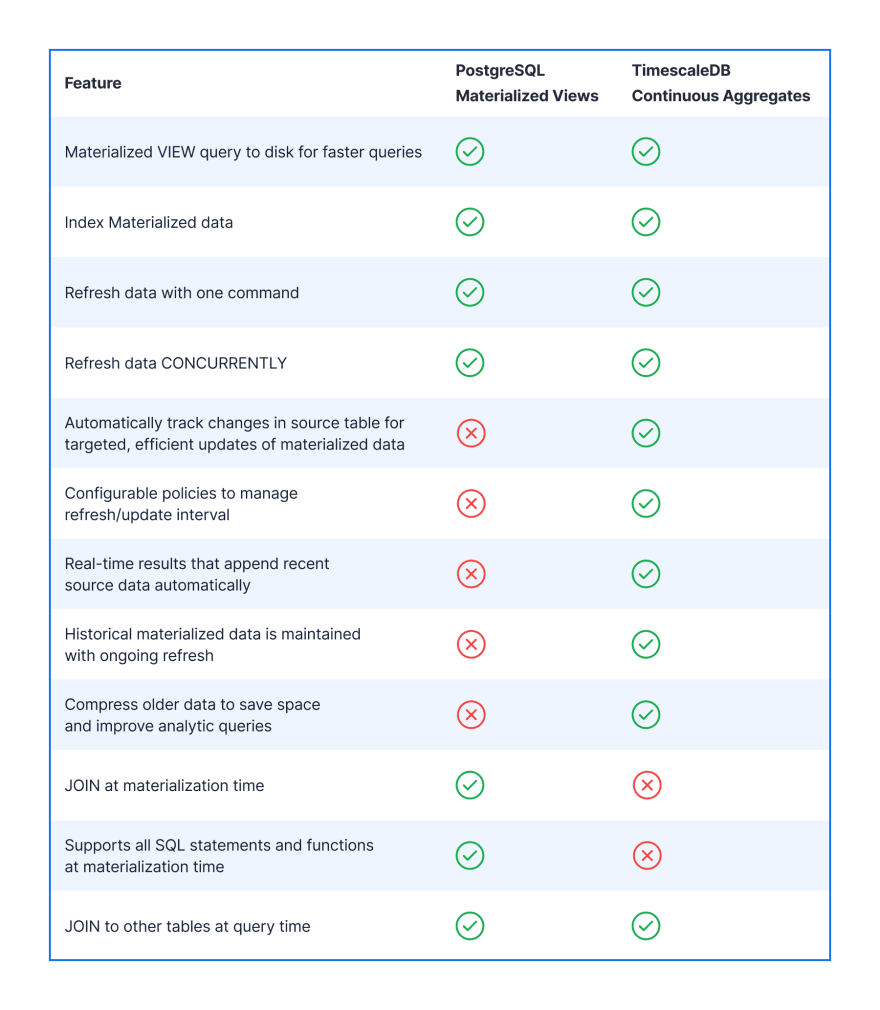
连续聚合的外观和行为类似于 PostgreSQL 中的物化视图,但具有许多我一直在寻找的附加功能。这些只是他们所做的一些事情:
-
自动跟踪基础原始数据的更改和添加。
-
提供可配置的、用户定义的策略,以使物化数据自动保持最新。
-
在计划进程实现到磁盘之前自动追加新数据(默认为实时聚合)。此设置是可配置的。
-
即使删除了基础原始数据,也保留历史汇总数据。
-
可以压缩以减少存储需求并进一步提高分析查询的性能。
-
保持仪表板和报表平稳运行。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--RvbUKfLP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/mw9qkerxxfy3d08ec5kv.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--RvbUKfLP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/mw9qkerxxfy3d08ec5kv.png)
**
其他数据库呢?
**
到现在为止,一些读者可能会沿着这些思路思考:
“连续聚合可能有助于 PostgreSQL 中时间序列数据的管理和分析,但这正是 NoSQL 数据库的用途——它们从一开始就提供了您需要的功能。为什么不尝试 NoSQL 数据库?”
嗯,我做到了。
市场上有许多时间序列和 NoSQL 数据库试图解决这个特定问题。我查看(并使用了)其中的许多。但根据我的经验,没有什么能比得上关系数据库的优势和时间序列数据的连续聚合等特性。这些其他选项为无数用例提供了许多功能,但它们并不是解决这个特定问题的正确解决方案。
MongoDB呢?
MongoDB 一直是许多数据密集型应用程序的首选。自 4.2 版起包含一个称为按需物化视图的功能。从表面上看,它的工作原理类似于物化视图,通过将聚合管道功能与 $merge 操作相结合来模拟聚合数据集合的持续更新。但是,这个过程没有内置的自动化,而且 MongoDB 不会跟踪对基础数据的任何修改。开发人员仍然需要跟踪实现哪些时间框架以及回顾多远。
InfluxDB 怎么样?
多年来,InfluxDB 一直是时间序列应用程序的目的地。尽管我们在其他文章中讨论了 InfluxDB 如何无法有效扩展,尤其是对于高基数数据集,但它确实提供了一个称为连续查询的功能。此功能也类似于物化视图,并且通过自动保持数据集更新比 MongoDB 更进了一步。不幸的是,它同样缺乏对原始数据的监控,并且在数据集的创建和存储方式上没有提供与 SQL 一样多的灵活性。
Clickhouse 怎么样?
Clickhouse 和 Firebolt 等最近的几个分支重新定义了一些分析工作负载的执行方式。即使有一些令人印象深刻的查询性能,它也提供了一种类似于物化视图的机制,由 AggregationMergeTree 引擎支持。从某种意义上说,这提供了几乎实时的聚合数据,因为所有插入都保存到常规表和物化视图中。这种方法的最大缺点是处理更新或修改过程的时间。
连续聚合的最新改进:满足 TimescaleDB 2.7
连续聚合最早是在 TimescaleDB 1.3 中引入的,解决了包括我在内的许多 PostgreSQL 用户面临的时间序列数据和物化视图的问题:自动更新、实时结果、易于数据管理以及使用视图进行下采样的选项.
但是连续聚合已经走了很长一段路。之前的改进之一是在 TimescaleDB 2.6 中为连续聚合引入了压缩。现在,随着 TimescaleDB 2.7 的到来,我们更进一步,它在连续聚合中引入了显着的性能改进。 它们现在速度极快——在某些查询中比以前的版本快 44,000 倍。
让我举一个具体的例子:在使用实时股票交易数据的初始测试中,典型烛台聚合的查询速度比之前的连续聚合版本快近 2,800 倍(已经很快了!)
在这篇文章的后面,我们将通过展示使用多个数据集和查询的连续聚合的完整基准来深入探讨 TimescaleDB 2.7 引入的性能和存储改进。 🔥
但改进并不止于此。
首先,对于许多常见的聚合,新的连续聚合所需的存储(平均)也比以前减少了 60%,这直接转化为存储节省。其次,在以前的 TimescaleDB 版本中,连续聚合具有某些限制:例如,用户不能使用某些功能,如 DISTINCT、FILTER 或 ORDER BY。这些限制现在已经消失了。 TimescaleDB 2.7 附带了一个完全重新设计的物化过程,它解决了许多以前的可用性问题,因此您可以使用任何聚合函数来定义您的连续聚合。查看我们的发行说明,了解有关新功能的所有详细信息。
现在,有趣的部分。
给我看数字:基准聚合查询
为了测试新版本的连续聚合,我们选择了两个代表常见时间序列数据集的数据集:物联网和财务分析。
IoT 数据集(约 17 亿行):我们利用的 IoT 数据是由 Todd Schneider 维护多年的 New York City Taxicab 数据集,他的 GitHub 存储库中提供了脚本以将数据加载到 PostgreSQL .不幸的是,在他最近一次更新一周后,维护实际数据集的交通当局将其长期存在的导出数据格式从 CSV 更改为 Parquet,这意味着当前的脚本将无法工作。因此,我们测试的数据集来自该更改之前的数据,涵盖了 2014 年至 2021 年的骑行信息。
股票交易数据集(约 2370 万行):我们使用的金融数据集是由 Twelve Data 提供的实时股票交易数据集,并收录了从 2022 年 2 月至今按交易量计算的前 100 只股票的持续交易。实时交易数据通常是许多股票交易分析应用程序的来源,这些应用程序需要在时间间隔内汇总汇总以进行可视化,例如烛台图和机器学习分析。虽然我们的示例数据集比一个成熟的金融应用程序要维护的要小,但它提供了一个使用连续聚合、TimescaleDB 本机压缩和自动原始数据保留(同时保留聚合数据以进行长期分析)的持续数据摄取的工作示例。
您可以使用 Twelve Data 慷慨提供的数据样本,按照本教程尝试 TimescaleDB 2.7 中的所有改进,该教程提供了过去 30 天的股票交易数据。设置好数据库后,您可以更进一步,注册 API 密钥并按照我们的教程从 Twelve Data API 获取正在进行的事务。
使用标准 PostgreSQL 聚合函数创建连续聚合
我们进行基准测试的第一件事是创建一个使用标准 PostgreSQL 聚合函数(如 MIN()、MAX() 和 AVG())的聚合查询。在我们测试的每个数据集中,我们在 TimescaleDB 2.6.1 和 2.7 中创建了相同的连续聚合,确保两个聚合计算并存储了相同数量的行。
物联网数据集
这种连续聚合产生了跨越七年数据的 1,760,000 行聚合数据。
每小时创建物化视图_trip_stats
WITH (timescaledb.continuous, timescaledb.finalizedu003dfalse)
作为
选择
time_bucket('1 小时',pickup_datetime) 桶,
平均(票价_金额)平均_票价,
最小(票价_金额)最小_票价,
最大(票价_金额)最大_票价,
平均(行程\距离)平均\距离,
最小(行程\距离)在\距离,
最大(行程\距离)最大\距离,
平均(拥堵_附加费)平均_附加费,
分钟(拥塞_附加费)分钟_附加费,
最大(拥塞_附加费)最大_附加费,
出租车_类型_id,
乘客_count
从
旅行
通过...分组
桶,出租车_type_id,乘客_count
股票交易数据集
这种连续的聚合在测试时产生了 950,000 行数据,尽管这些数据会随着新数据的出现而更新。
创建物化视图五_分钟_蜡烛_delta
WITH (timescaledb.continuous) AS
选择
time_bucket('5 minute', time) 作为存储桶,
象征,
FIRST(price, time) AS "open",
MAX(price) AS high,
MIN(价格)最低,
LAST(price, time) AS "close",
MAX(day_volume) AS day_volume,
(LAST(price, time)-FIRST(price, time))/FIRST(price, time) AS change_pct
FROM stock_real_time srt
GROUP BY 桶,符号;
为了测试这两个连续聚合的性能,我们选择了以下查询,这些查询是我们用户对物联网和金融用例的所有常见查询:
-
选择计数 (*)
-
SELECT COUNT (*) with WHERE
-
订购
-
time_bucket 重新聚合
-
过滤器
-
有
让我们来看看结果。
查询 #1:SELECT COUNT(*) FROM…
从 PostgreSQL 执行 COUNT() 是一个已知的性能瓶颈。这是我们在 TimescaleDB 中创建近似_row_count() 函数的原因之一,该函数使用表统计信息来提供总行数的近似值。但是,对于大多数用户(以及我们自己,如果我们诚实的话)来说,尝试通过执行 COUNT() 查询来快速获取行数是本能的:
-- 物联网数据集
SELECT count(*) FROM hourly_trip_stats;
-- 股票交易数据集
从五个_min_candle_delta中选择计数(*);
大多数用户认识到,在以前版本的 TimescaleDB 中,物化数据似乎比正常执行 COUNT 慢。
考虑我们的两个示例数据集,两个连续聚合都将原始数据的总行数减少了 20 倍或更多。因此,虽然在 PostgreSQL 中计算行数很慢,但总感觉比它必须的要慢一些。原因是 PostgreSQL 不仅必须扫描和计算所有数据行,还必须对数据进行第二次分组,因为 TimescaleDB 作为原始连续聚合设计的一部分存储了一些额外的数据。随着 TimescaleDB 2.7 中连续聚合的新设计,不再需要第二个分组,PostgreSQL 可以正常查询数据,转化为更快的查询。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--H4yD60u_--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/q3eywqfb7zy6ht4laz88.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--H4yD60u_--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/q3eywqfb7zy6ht4laz88.png)
TimescaleDB 2.6.1 和 TimescaleDB 2.7 中连续聚合中的 SELECT COUNT (*) 查询的性能
查询 #2:SELECT COUNT(*) 基于列的值
许多分析应用程序执行的另一个常见查询是统计聚合值在一定范围内的记录数:
-- 物联网数据集
SELECT count(*) FROM hourly_trip_stats
WHERE avg_fare > 13.1
AND 桶 > '2018-01-01' AND 桶 < '2019-01-01';
-- 股票交易数据集
从五个_min_candle_delta 中选择计数(*)
哪里改变_pct > 0.02;
在以前版本的连续聚合中,TimescaleDB 必须先确定该值,然后才能根据谓词值对其进行过滤,这导致查询执行速度更慢。使用新版本的连续聚合,PostgreSQL 现在可以直接搜索值,我们可以为有意义的列添加索引以进一步加快查询速度!
对于金融数据集,我们看到了非常显着的改进:快了 1,336 倍。性能的巨大变化可归因于必须对连续聚合中的所有数据行进行计算的公式查询。对于物联网数据集,我们正在与一个简单的平均函数进行比较,但对于股票数据,必须先确定多个值(FIRST/LAST),然后才能计算公式并将其用于过滤器。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--um_N5iq8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/m2z1qz6w3qz80rkhz7l9.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--um_N5iq8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/m2z1qz6w3qz80rkhz7l9.png)
在 TimescaleDB 2.6.1 和 TimescaleDB 2.7 中使用 SELECT COUNT (*) 加上 WHERE 在连续聚合中的查询性能
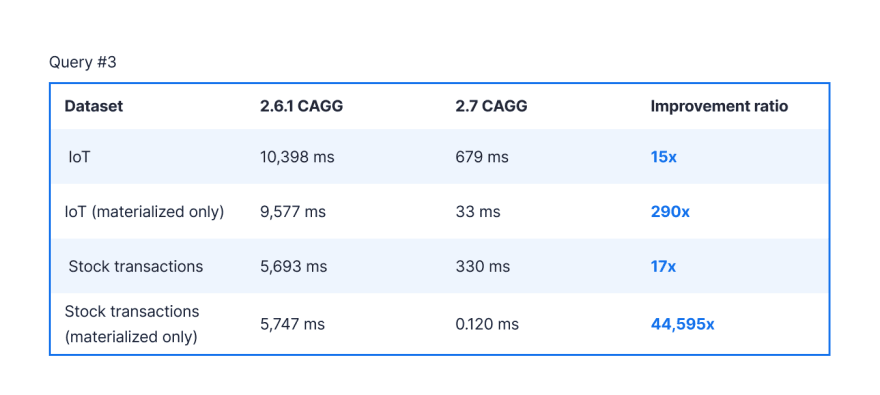
查询 #3:按值选择前 10 行
将第一个示例更进一步,在一个时间范围内查询数据并获取顶部行是很常见的:
-- 物联网数据集
SELECT * FROM hourly_trip_stats
ORDER BY avg_fare desc
限制 10;
-- 股票交易数据集
选择 * 从五个_min_candle_delta
ORDER BY change_pct DESC
限制 10;
在这种情况下,我们使用连续聚合集测试查询以提供实时结果(连续聚合的默认值)和仅物化结果。当设置为实时时,TimescaleDB 总是先查询已物化的数据,然后(使用 UNION)附加(使用 UNION)存在于原始数据中但尚未被持续刷新策略物化的任何新数据。而且,因为现在可以对连续聚合中的列进行索引,所以我们在 ORDER BY 列上添加了一个索引。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--A2_oSIyQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/7bbvv3hctn85gfk6b8ww.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--A2_oSIyQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/7bbvv3hctn85gfk6b8ww.png)
在连续聚合 TimescaleDB 2.6.1 和 TimescaleDB 2.7 中使用 ORDER BY 查询的性能
是的,你没看错。当查询仅搜索物化数据时,ORDER BY 的性能提高了近 45,000 倍。
实时查询和仅物化查询之间的巨大差异是因为物化和原始聚合数据的联合。 PostgreSQL 计划程序需要合并总结果,然后才能将查询限制为 10 行(在我们的示例中),因此需要先读取两个表中的所有数据并对其进行排序。当你只查询物化数据时,PostgreSQL 和 TimescaleDB 知道它只能查询物化数据的索引。
同样,存储数据的最终形式和索引列值会极大地影响历史聚合数据的查询性能!所有这些都以非破坏性的方式随着时间的推移不断更新——这是任何其他关系数据库都无法做到的,包括 vanilla PostgreSQL。
查询 #4:重新聚合到更高时间桶中的时间尺度超函数
我们想要测试的另一个例子是最终确定数据值对我们的分析超函数套件的影响。作为 TimescaleDB 工具包的一部分,我们提供的许多超函数使用自定义聚合值,这些值允许稍后根据应用程序或报告的需要访问许多不同的值。此外,这些聚合值可以重新聚合到不同大小的时间桶中。这意味着如果聚合函数适合您的用例,一个连续聚合可以产生许多不同 time_bucket 大小的结果!随着时间的推移,这是许多用户要求的功能,而超功能使这成为可能。
对于这个例子,我们只检查了纽约市出租车数据集来衡量最终 CAGG 的影响。目前,没有与股票数据集所需的 OHLC 值一致的聚合超函数,但是,有一个功能请求! (😉)
尽管目前没有任何一对一的超函数可以为我们的 min/max/avg 示例提供精确的替换,但我们仍然可以使用原始查询中每个列的 tdigest 值来观察查询改进。
多列的原始最小/最大/平均连续聚合:
每小时创建物化视图_trip_stats
WITH (timescaledb.continuous, timescaledb.finalizedu003dfalse)
作为
选择
time_bucket('1 小时',pickup_datetime) 桶,
平均(票价_金额)平均_票价,
最小(票价_金额)最小_票价,
最大(票价_金额)最大_票价,
平均(行程\距离)平均\距离,
最小(行程\距离)在\距离,
最大(行程\距离)最大\距离,
平均(拥堵_附加费)平均_附加费,
分钟(拥塞_附加费)分钟_附加费,
最大(拥塞_附加费)最大_附加费,
出租车_类型_id,
乘客_count
从
旅行
通过...分组
桶,出租车_type_id,乘客_count
基于超函数的多列连续聚合:
每小时创建实体化视图_trip_stats_toolkit
WITH (timescaledb.continuous, timescaledb.finalizedu003dfalse)
作为
选择
time_bucket('1 小时',pickup_datetime) 桶,
tdigest(1,fare_amount) 票价_digest,
tdigest(1,trip\distance) 距离\摘要,
tdigest(1,congestion_surcharge) 附加费_digest,
出租车_类型_id,
乘客_count
从
旅行
通过...分组
桶,出租车_type_id,乘客_count
创建连续聚合后,我们以两种不同的方式查询这些数据:
*_1\。使用连续聚合中定义的相同time_bucket()大小,在此示例中为一小时数据。
*_
选择
桶 AS b,
出租车_类型_id,
乘客_计数,
min_val(ROLLUP(票价_digest)),
最大值_val(ROLLUP(票价_digest)),
平均值(ROLLUP(票价_digest))
从每小时\旅行\统计\工具包
WHERE 桶 > '2021-05-01' AND 桶 < '2021-06-01'
GROUP BY b,出租车_type_id,乘客_count
ORDER BY b DESC、cab_type_id、passenger_count;
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--bjqZzkto--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/8zdqafcqs358ygqtla4a.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--bjqZzkto--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/8zdqafcqs358ygqtla4a.png)
_TimescaleDB 2.6.1 和 TimescaleDB 2.7 中连续聚合中的 time_bucket() 查询的性能(查询使用与连续聚合定义相同的桶大小)_
**2.我们将数据从一小时存储桶重新聚合到一天存储桶中。 **这使我们可以根据连续聚合的原始桶大小有效地查询不同的桶长度。
选择
time_bucket('1 day', bucket) AS b,
出租车_类型_id,
乘客_计数,
min_val(ROLLUP(票价_digest)),
最大值_val(ROLLUP(票价_digest)),
平均值(ROLLUP(票价_digest))
从每小时\旅行\统计\工具包
WHERE 桶 > '2021-05-01' AND 桶 < '2021-06-01'
GROUP BY b,出租车_type_id,乘客_count
ORDER BY b DESC、cab_type_id、passenger_count;
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--zUarEb3R--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/j09v65k24hfwi0c0llr0.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--zUarEb3R--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/j09v65k24hfwi0c0llr0.png)
TimescaleDB 2.6.1 和 TimescaleDB 2.7 中连续聚合中使用 time_bucket() 的查询的性能。查询将一小时桶中的数据重新聚合到一天桶中
在这种情况下,速度几乎相同,因为必须查询相同数量的数据。但是,如果这些聚合满足您的数据要求,则在许多情况下只需要一个连续聚合,而不是针对每个存储桶大小(一分钟、五分钟、一小时等)使用不同的连续聚合。
查询 #5:使用 FILTER 透视查询
在以前的连续聚合版本中,由于部分数据是在以后存储和最终确定的,因此不允许使用许多常见的 SQL 功能。使用 PostgreSQL FILTER 子句就是这样一种限制。
例如,我们获取 IoT 数据集并创建了一个简单的 COUNT(*) 来计算每个公司每小时的出租车乘车次数 (cab_type_id)。在 TimescaleDB 2.7 之前,您必须以窄列格式存储这些数据,在每个 cab 类型的连续聚合中存储一行。
每小时创建实体化视图_ride_counts_by_type
WITH (timescaledb.continuous, timescaledb.finalizedu003dfalse)
作为
选择
time_bucket('1 小时',pickup_datetime) 桶,
出租车_类型_id,
数数(*)
从旅行
WHERE cab_type_id IN (1,2)
通过...分组
桶,驾驶室_type_id;
然后以旋转方式查询这些数据,我们可以在事后过滤连续聚合数据。
选择桶,
sum(count) FILTER (WHERE can_type_id IN (1)) yellow\cab_count,
sum(count) FILTER (WHERE cab_type_id IN (2)) green_cab_count
FROM hourly_ride\counts\by\type
WHERE 桶 > '2021-05-01' AND 桶 < '2021-06-01'
GROUP BY 存储桶
按桶排序;
在 TimescaleDB 2.7 中,您现在可以使用 FILTER 子句存储聚合数据,一步即可获得相同的结果!
每小时创建实体化视图_骑行_计数\按\类型_新
WITH (timescaledb.continuous)
作为
选择
time_bucket('1 小时',pickup_datetime) 桶,
COUNT(_) FILTER (WHERE cab_type_id IN (1)) 黄色_cab_count,
COUNT(_) FILTER (WHERE cab_type_id IN (2)) green_cab_count
从旅行
通过...分组
桶;
查询这些数据也简单得多,因为数据已经被旋转并最终确定。
SELECT * FROM hourly_ride_counts_by_type_new
WHERE 桶 > '2021-05-01' AND 桶 < '2021-06-01'
按桶排序;
这节省了存储空间(在这种情况下,行数减少了 50%)和 CPU 以最终确定 COUNT(*),然后每次根据 cab_type_id 过滤结果。我们可以在查询性能数字中看到这一点。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--rqXpWUYb--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/1a8zmqf30mqt1c954rmo.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--rqXpWUYb--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/1a8zmqf30mqt1c954rmo.png)
_在 TimescaleDB 2.6.1 和 TimescaleDB 2.7 中的连续聚合中使用 FILTER 进行查询的性能。 _
能够使用 FILTER 和其他 SQL 功能可以长期提高开发人员的体验和灵活性!
查询 #6:存储的物化数据显着减少
作为持续聚合的改进将如何影响您的日常开发和分析流程的最后一个示例,让我们看一个使用 HAVING 子句减少聚合存储的行数的简单查询。
在以前版本的 TimescaleDB 中,不能在实现时应用 having 子句。取而代之的是,HAVING 子句在所有聚合数据最终确定后应用到它。在许多情况下,这极大地影响了对连续聚合的查询速度和整体存储的数据量。
以我们的股票数据为例,让我们创建一个连续聚合,该聚合仅在 change_pct 值大于 20 % 时存储一行数据。这表明股票价格在一小时内发生了巨大变化,这是我们预计在大多数每小时股票交易中不会看到的。
创建 MATERIALIZED VIEW one_hour_outliers
WITH (timescaledb.continuous) AS
选择
time_bucket('1 小时', time) 作为存储桶,
象征,
FIRST(price, time) AS "open",
MAX(price) AS high,
MIN(价格)最低,
LAST(price, time) AS "close",
MAX(day_volume) AS day_volume,
(LAST(price, time)-FIRST(price, time))/LAST(price, time) AS change_pct
FROM stock_real_time srt
GROUP BY 桶,符号
HAVING (LAST(price, time)-FIRST(price, time))/LAST(price, time) > .02;
创建数据集后,我们可以查询每个聚合以查看有多少行符合我们的条件。
SELECT count(*) FROM one_hour_outliers;
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--W7cT6ufD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/45hoy2rmf5zp3xewpjmq.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--W7cT6ufD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/45hoy2rmf5zp3xewpjmq.png)
在 TimescaleDB 2.6.1 和 TimescaleDB 2.7 中将查询的性能与 HAVING 在连续聚合中的性能进行比较。
这里最大的区别(随着时间的推移会对应用程序的性能产生更大的负面影响)是这些聚合数据的存储大小。因为 TimescaleDB 2.7 只存储符合条件的行,所以数据占用空间要小得多!
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--cEs3l8AQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/uc6np5kkh8mzfugjrdqw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--cEs3l8AQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/uc6np5kkh8mzfugjrdqw.png)
TimescaleDB 2.6.1 和 TimescaleDB 2.7 中按小时计算的连续聚合分桶股票交易的存储足迹
TimescaleDB 2.7 中的存储节省
这次更新的最后一个让我们兴奋的部分是随着时间的推移将节省多少存储空间。在许多情况下,拥有在其连续聚合中包含复杂方程的大型数据集的用户会加入我们的 Slack 社区,询问为什么汇总的聚合需要比原始数据更多的存储空间。
在我们测试的每种情况下,新的、最终形式的连续聚合都比以前版本的 TimescaleDB 中的相同示例小,无论有没有可能过滤掉额外数据的 HAVING 子句。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--DWwg35Ar--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/h3zlhlo6exstawgnn3xl.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--DWwg35Ar--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/h3zlhlo6exstawgnn3xl.png)
TimescaleDB 2.6.1 和 TimescaleDB 2.7 中不同连续聚合的存储节省
新的连续聚合是游戏规则的改变者
对于那些处理大量时间序列数据的人来说,连续聚合是解决长期困扰 PostgreSQL 用户的问题的最佳方法。以下列表详细说明了连续聚合如何扩展物化视图:
-
它们始终保持最新状态,自动跟踪源表中的更改,以实现有针对性、高效的物化数据更新。
-
您可以使用可配置的策略来方便地管理刷新/更新间隔。
-
即使在原始数据被删除后,您也可以保留具体化数据,从而允许您对大型数据集进行下采样。
-
并且您可以压缩旧数据以节省空间并改进分析查询。
-
在 TimescaleDB 2.7 中,连续聚合变得更好。
首先,它们的速度非常快:正如我们在基准测试中所展示的那样,连续聚合的性能在查询和数据集上始终如一地变得更好,对于普通查询,性能提高了数千倍。它们也变得更轻,所需的存储空间平均减少了 60%。
但除了性能改进和存储节省之外,可用于连续聚合的聚合查询类型的限制要少得多,例如:
-
具有 DISTINCT 的聚合
-
使用 FILTER 聚合
-
在 HAVING 子句中使用 FILTER 聚合
-
没有组合功能的聚合
-
有序集聚合
-
假设集聚合
这个新版本的连续聚合默认在 TimescaleDB 2.7 中可用:现在,当您创建新的连续聚合时,您将自动受益于所有最新更改。对于您现有的连续聚合,我们建议您在最新版本中重新创建它们以利用所有这些改进。阅读我们的发行说明了解有关 TimescaleDB 2.7 的更多信息,以及有关如何升级的说明,查看我们的文档。

PostgreSQL社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献19904条内容
已为社区贡献19904条内容

所有评论(0)