
TOP开源数据库软件
数据就是一切。通过扩展,数据库也是如此。以下是您下一个严肃项目的一些出色的开源选项。
对于一个由 Oracle 和 SQL Server 等数据库套件主导的世界,现在似乎有无穷无尽的解决方案。部分原因是开源推动了创新——真正有才华的开发人员想要抓紧痒痒,创造出他们可以陶醉的东西。
另一部分是新商业模式的出现,其中企业维护其产品的社区版本以获得思想份额和牵引力,同时还提供商业附加产品。
 结果?
结果?
数据库数量超过一个可以跟上的。对此没有官方统计数据,但我敢肯定,如果您结合从特定于堆栈的对象数据库到大学中不太受欢迎的项目的所有内容,我们今天有一百多个可用选项。
我知道;它也让我害怕。太多的选择——太多的文档要经过——而且生命如此短暂。 🙂
这就是我决定写这篇文章的原因,介绍十个可以用来改进解决方案的最佳数据库,无论是为自己构建还是为他人构建。
**没有 MySQL **
请注意:此列表不包含 MySQL,尽管它可以说是目前最流行的开源数据库解决方案。
 为什么?
为什么?
仅仅因为 MySQL 无处不在——它是每个人首先学习的东西,几乎所有 CMS 或框架都支持它,而且它对大多数用例都非常非常好。换句话说,MySQL 不需要被“发现”。 🙂
也就是说,请注意以下内容不一定是 MySQL 的替代品。在某些情况下,它们可能是,而在其他情况下,它们是针对完全不同需求的完全不同的解决方案。别担心,因为我也会讨论它们的用途。
特别说明:兼容性
在我们开始之前,我还必须提到兼容性是您需要牢记的事情。如果您有一个项目,无论出于何种原因,只支持特定的数据库引擎,那么您的选择几乎是通过了。
例如,如果您正在运行 WordPress,那么这篇文章对您毫无用处。 🙂 同样,那些在 JAMStack 上运行静态站点的人会因为过于认真地寻找替代方案而一无所获。
由您决定兼容性方程。但是,如果您有一张白纸并且架构由您决定,这里有一些简洁的建议。
PostgreSQL
如果你来自 PHP 领域(WordPress、Magento、Drupal 等),那么PostgreSQL对你来说听起来很陌生。然而,这种关系数据库软件自 1997 年以来就已经存在,并且是 Ruby、Python、Go 等社区的首选。
 事实上,许多开发人员最终“毕业”到 PostgreSQL 是因为它提供的特性或者仅仅是为了稳定性。在这样的简短文章中很难说服某人,但将 PostgreSQL 视为一个经过深思熟虑的设计产品,永远不会让你失望。
事实上,许多开发人员最终“毕业”到 PostgreSQL 是因为它提供的特性或者仅仅是为了稳定性。在这样的简短文章中很难说服某人,但将 PostgreSQL 视为一个经过深思熟虑的设计产品,永远不会让你失望。
有许多优秀的 SQL 客户端可用于连接到 PostgreSQL 数据库以进行管理和开发。
独特的功能
与其他关系数据库(特别是 MySQL)相比,PostgreSQL 有几个引人入胜的特性,例如:
-
Array、Range、UUID、Geolocation等内置数据类型。
-
原生支持文档存储(JSON 风格)、XML 和键值存储(Hstore)
-
同步和异步复制
-
可在 PL、Perl、Python 等中编写脚本
-
全文检索
-
我个人最喜欢的是地理定位引擎(它消除了使用基于位置的应用程序时的痛苦——尝试手动查找所有附近的点,你就会明白我的意思)和对数组的支持(许多 MySQL 项目因需要而撤消的数组,而不是选择臭名昭著的逗号分隔的字符串)。
何时使用 PostgreSQL
PostgreSQL 总是比任何其他关系数据库引擎更好的选择。也就是说,如果你正在开始一个新项目并且之前被 MySQL 咬过,那么现在是考虑使用 PostgreSQL 的好时机。我有朋友放弃了与 MySQL 的神秘事务锁故障作斗争并永久地继续前进。如果你做出同样的决定,你就不会反应过度。
如果您需要用于混合数据模型的部分 NoSQL 工具,PostgreSQL 也具有明显的优势。由于本机支持文档和键值存储,因此您无需寻找、安装、学习和维护另一个数据库解决方案。
不使用 PostgreSQL 时
当您的数据模型不是关系型和/或当您有非常具体的架构要求时,PostgreSQL 没有意义。例如,考虑分析,其中不断从现有数据创建新报告。当对它们施加严格的模式时,此类系统读取量很大并且会受到影响。当然,PostgreSQL 有一个文档存储引擎,但是当您处理大型数据集时,事情就开始崩溃了。
换句话说,除非您 100% 知道自己在做什么,否则请始终使用 PostgreSQL! 🙂
MariaDB
MariaDB是由开发 MySQL 的同一个人创建的,以替代 MySQL。
使困惑?
嗯,实际上,在 MySQL 于 2010 年被 Oracle 收购之后(通过收购 Sun Microsystems,顺便说一下,这也是 Oracle 控制 Java 的方式),MySQL 的创建者开始了一个名为 MariaDB 的新开源项目。
 为什么所有这些无聊的细节都很重要,你问?这是因为 MariaDB 是从与 MySQL 相同的代码库创建的(在开源世界中,这被称为“分叉”现有项目)。因此,MariaDB 被呈现为 MySQL 的“插入式”替代品。
为什么所有这些无聊的细节都很重要,你问?这是因为 MariaDB 是从与 MySQL 相同的代码库创建的(在开源世界中,这被称为“分叉”现有项目)。因此,MariaDB 被呈现为 MySQL 的“插入式”替代品。
也就是说,如果您使用 MySQL 并想迁移到 MariaDB,那么这个过程非常简单,您简直不敢相信。
 不幸的是,这样的迁移是一条单行道。从 MariaDB 回到 MySQL 是不可能的,如果您尝试使用强制,将确保永久数据库损坏!
不幸的是,这样的迁移是一条单行道。从 MariaDB 回到 MySQL 是不可能的,如果您尝试使用强制,将确保永久数据库损坏!
独特的功能
尽管 MariaDB 本质上是 MySQL 的克隆,但严格来说并非如此。自从引入数据库以来,两者之间的差异一直在扩大。在撰写本文时,采用 MariaDB 需要您做出深思熟虑的决定。也就是说,MariaDB 中有很多新事物可以帮助您完成这种过渡:
-
真正的自由和开放:由于没有单一的企业实体控制 MariaDB,您可以免除突然的掠夺性许可和其他后顾之忧。
-
针对特殊需求的存储引擎的更多选择:例如,用于分布式事务的Spider引擎;用于海量数据仓库的ColumnStore;用于并行、分布式存储的 ColumnStore 引擎;还有很多很多。
-
速度比 MySQL 有所提高,特别是由于复杂查询的 Aria 存储引擎。
-
表中不同行的动态列。
-
更好的复制能力(例如多源复制)
-
几个JSON函数
-
虚拟列。 . .还有很多很多。跟上所有 MariaDB 的特性很累。 🙂
何时使用 MariaDB
如果您想真正替代 MySQL,您应该使用 MariaDB,因为他们希望保持创新曲线并且不打算再次返回 MySQL。一个很好的用例是在 MariaDB 中使用新的存储引擎来补充您项目现有的关系数据模型。
何时不使用 MariaDB
与 MySQL 的兼容性是这里唯一关心的问题。也就是说,随着 WordPress、Joomla、Magento 等项目开始支持 MariaDB,问题变得越来越小。我的建议是不要使用 MariaDB 来欺骗不支持它的 CMS,因为许多特定于数据库的技巧很容易使系统崩溃。
CockroachDB
CockroachDB背后的团队似乎是由受虐狂组成的。有了这样的产品名称,他们肯定想不顾一切地战胜他们并仍然获胜吗?
嗯,不完全是。
 “蟑螂”背后的想法是,它是一种为生存而生的昆虫。无论发生什么——掠食者、洪水、永恒的黑暗、腐烂的食物、轰炸,蟑螂都能找到生存和繁殖的方法。
“蟑螂”背后的想法是,它是一种为生存而生的昆虫。无论发生什么——掠食者、洪水、永恒的黑暗、腐烂的食物、轰炸,蟑螂都能找到生存和繁殖的方法。
这个想法是,CockroachDB 背后的团队(由前谷歌工程师组成)在大规模处理时对传统 SQL 解决方案的局限性感到沮丧。这是因为,从历史上看,SQL 解决方案应该托管在单台机器上(数据没有那么大)。长期以来,没有办法构建运行 SQL 的数据库集群,这也是 MongoDB 备受关注的原因。
 即使复制和集群出现在 MySQL、PostgreSQL 和 MariaDB 中,充其量也是痛苦的。 CoackroachDB 希望改变这一点,为 SQL 世界带来轻松的分片、集群和高可用性。
即使复制和集群出现在 MySQL、PostgreSQL 和 MariaDB 中,充其量也是痛苦的。 CoackroachDB 希望改变这一点,为 SQL 世界带来轻松的分片、集群和高可用性。
何时使用 CockroachDB
CockroachDB 是系统架构师的梦想成真。如果您对 SQL 发誓,并且一直对 MongoDB 的扩展能力深感兴趣,那么您会喜欢 CockroachDB。现在,您可以快速设置集群,向其发送查询,并在晚上安然入睡。 🙂
什么时候不使用 CockroachDB
你认识的魔鬼比你不认识的魔鬼好。我的意思是,如果您现有的 RDBMS 对您来说运行良好,并且您认为您可以管理它带来的扩展难题,请坚持使用它。 CockroachDB 是一款适用于所有相关天才的新产品,您不想以后再与它作斗争。另一个主要原因是 SQL 兼容性——如果你正在做一些奇特的 SQL 东西并依赖它来处理关键的事情,CockroachDB 将呈现太多你喜欢的边缘案例。
从现在开始,我们将考虑满足高度专业化需求的非 SQL(或称为 NoSQL)数据库解决方案。
ClickHouse
正在寻找一个快速、开源的 OLAP 数据库系统?
去ClickHouse。
它最大限度地利用每个硬件来更快地处理每个查询。处理查询的峰值性能通常保持在每秒 2 TB 以上。为了避免增加延迟,读取在健康副本之间自动平衡。
它支持多主异步复制,您可以将其部署在不同的数据中心。由于节点保持相等,您甚至可以避免单个故障点。单个节点或整个数据中心的停机时间永远不会影响系统在写入和读取方面的可用性。
ClickHouse 非常易于使用和简单。它简化了数据处理,以有组织的方式将所有数据放入系统中,并可立即用于构建报告。此外,SQL 方言有助于在不使用任何非标准 API 的情况下表达结果,您可以在替代系统中获得这些 API。
 您可以依靠这个数据库管理系统将它配置为一个分布式系统,它位于没有故障点的不同节点上。此外,它的安全功能非常强大,包括企业级安全性和万一出现人为错误的故障安全机制。
您可以依靠这个数据库管理系统将它配置为一个分布式系统,它位于没有故障点的不同节点上。此外,它的安全功能非常强大,包括企业级安全性和万一出现人为错误的故障安全机制。
与具有相同 CPU 容量和 I/O 吞吐量的面向行的系统相比,ClickHouse 可以更快地处理查询。其列式数据存储格式有助于将更多数据保存在 RAM 中,从而缩短响应时间。
使用具有旋转磁盘驱动器的商用硬件而不是使用 NVMe/SSD 可以降低总拥有成本,而不会牺牲查询的延迟。它致力于提高 CPU 效率,优化对磁盘驱动器的访问,并最大限度地减少数据传输。
此外,由于其功能丰富的 SQL 数据库,您可以立即高效地处理查询、连接位于同一地点和分布式的数据、有效地管理非规范化信息等等。 ClickHouse 可以水平和垂直扩展,并且可以轻松适应在具有数千个节点的单个服务器或集群上执行。
将 ClickHouse 用于 Web 和应用程序分析、电信、广告网络、在线游戏、物联网、商业智能、金融、电子商务、监控等。
它与 Hadoop、Postgres 和 MySQL 集成。
如果您还没有准备好安装和设置服务器,您可以尝试 Kamatera,它一键提供 ClickHouse。
Neo4j
近十年来最重要的发展之一是互联数据。我们周围的世界并没有被分割成表格、行和盒子——它是一个巨大的混乱,几乎所有东西都连接到其他东西。
社交网络就是一个典型的例子,使用 SQL 甚至基于文档的数据库构建类似的数据模型是一场噩梦。
这是因为这些解决方案的理想数据结构是图,这是一个完全不同的野兽。为此,您需要像Neo4j这样的图形数据库。
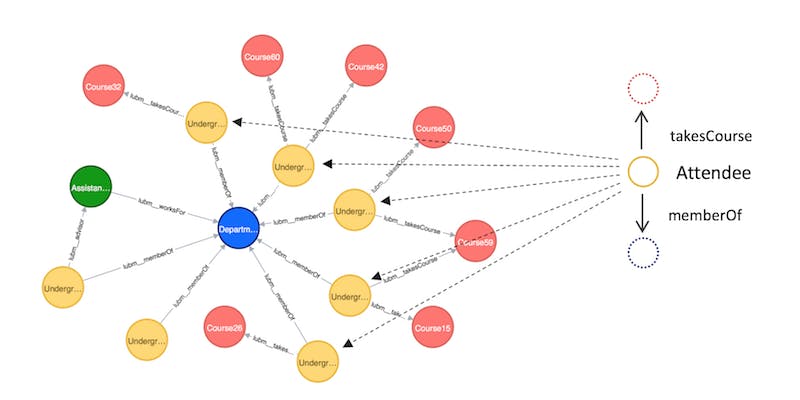 上面的示例直接取自 Neo4j 网站,展示了大学生如何与他们的部门和课程建立联系。这样的数据模型对于 SQL 来说是完全不可能的,因为很难避免无限循环和内存溢出。
上面的示例直接取自 Neo4j 网站,展示了大学生如何与他们的部门和课程建立联系。这样的数据模型对于 SQL 来说是完全不可能的,因为很难避免无限循环和内存溢出。
独特的功能
图形数据库本身是独一无二的,Neo4j 几乎是处理图形的唯一选择。因此,它具有的任何功能都是独一无二的。 🙂
-
支持事务应用程序和图形分析。
-
将大规模表格数据消化成图表的数据转换能力。
-
查询图数据库的专用查询语言(Cypher)
-
可视化和发现功能
讨论何时使用 Neo4j 何时不使用是一个有争议的问题。如果您需要数据之间基于图形的关系,则需要 Neo4j。 🙂
MongoDB
MongoDB 是第一个在科技行业掀起波澜的非关系型数据库,并继续占据相当大的份额。
 与关系型数据库不同,MongoDB 是一个“文档数据库”,它以块的形式存储数据,相关数据聚集在同一个块中。通过想象这样的 JSON 结构的聚合可以最好地理解这一点:
与关系型数据库不同,MongoDB 是一个“文档数据库”,它以块的形式存储数据,相关数据聚集在同一个块中。通过想象这样的 JSON 结构的聚合可以最好地理解这一点:
 在这里,与基于表的结构不同,用户的联系方式和访问级别位于同一个对象中。获取用户对象会自动获取关联数据,并且没有连接的概念。这是对 MongoDB 的更详细介绍。
在这里,与基于表的结构不同,用户的联系方式和访问级别位于同一个对象中。获取用户对象会自动获取关联数据,并且没有连接的概念。这是对 MongoDB 的更详细介绍。
独特的功能
MongoDB有一些严重的(我几乎想写“kick-ass”来传达影响,但它可能不适合在公共网站上)使一些经验丰富的架构师永远放弃关系领域的特性:
-
用于特殊/不可预测用例的灵活模式。非常简单的分片和集群。您只需要为集群设置配置并忘记它。
-
从集群中添加或删除节点非常简单。
-
分布式事务锁。早期版本中缺少此功能,但最终被引入。
-
它针对非常快的写入进行了优化,使其非常适合作为缓存系统分析数据。
如果我听起来像是 MongoDB 的代言人,我很抱歉,但很难夸大 MongoDB 的优势。当然,NoSQL 数据建模一开始很奇怪,有些人永远不会掌握它,但对于许多架构师来说,它几乎总是胜过基于表的模式。
何时使用 MongoDB
MongoDB 是从结构化、严格的 SQL 世界到无定形、几乎令人困惑的 NoSQL 世界的一座伟大的跨界桥梁。它擅长开发原型,因为根本不需要担心架构,并且当您真正需要扩展时。是的,您可以使用云 SQL 服务来解决数据库扩展问题,但是天哪,它很贵吗!
最后,在某些用例中,基于 SQL 的解决方案是行不通的。例如,如果您正在创建像 Canva 这样的产品,用户可以在其中创建任意复杂的设计并能够在以后进行编辑,那么祝您使用关系数据库好运!
何时不使用 MongoDB
MongoDB 提供的完全缺乏模式可以作为那些不知道自己在做什么的人的 tar 坑。数据不匹配、死数据、不应为空的空字段——所有这些以及更多都是可能的。 MongoDB本质上是一个“哑”的数据存储,如果你选择它,应用程序代码必须承担很多维护数据完整性的责任。
如果您是开发人员,那么您会发现这很有用。
RethinkDB
顾名思义,RethinkDB在涉及实时应用程序时“重新思考”了数据库的概念和功能。
 当数据库更新时,应用程序无法知道。公认的方法是应用程序在有更新时立即触发通知,该通知通过复杂的桥接器(PHP -> Redis -> Node ->Socket.io就是一个例子) )。
当数据库更新时,应用程序无法知道。公认的方法是应用程序在有更新时立即触发通知,该通知通过复杂的桥接器(PHP -> Redis -> Node ->Socket.io就是一个例子) )。
但是如果更新可以直接从数据库推送到前端呢?!
是的,这就是 RethinkDB 的承诺。因此,如果您要制作真正的实时应用程序(游戏、市场、分析等),Rethink DB 值得一看。
Redis
说到数据库,几乎很容易忽视 Redis 的存在。那是因为Redis是内存数据库,主要用于支持缓存等功能。
 学习这个数据库是一个十分钟的工作(字面意思!),它是一个简单的键值存储,存储具有到期时间的字符串(当然可以设置为无穷大)。 Redis 在实用程序和性能方面弥补了功能上的损失。由于它完全存在于 RAM 中,因此读写速度非常快(每秒几十万次操作并非闻所未闻)。
学习这个数据库是一个十分钟的工作(字面意思!),它是一个简单的键值存储,存储具有到期时间的字符串(当然可以设置为无穷大)。 Redis 在实用程序和性能方面弥补了功能上的损失。由于它完全存在于 RAM 中,因此读写速度非常快(每秒几十万次操作并非闻所未闻)。
Redis 还有一个复杂的发布-订阅系统,这使得这个“数据库”的吸引力增加了一倍。
换句话说,如果你有一个项目可以从缓存中受益,或者有一些分布式组件,那么 Redis 是首选。
SQLite
是的,我保证我们已经完成了关系数据库,但是SQLite太可爱了,不容忽视。
 SQLite 是一个提供关系数据库存储引擎的轻量级 C 库。该数据库中的所有内容都位于一个文件中(扩展名为 .sqlite),您可以将其放在文件系统中的任何位置。这就是您使用它所需的全部内容!是的,没有要安装的“服务器”软件,也没有要连接的服务。
SQLite 是一个提供关系数据库存储引擎的轻量级 C 库。该数据库中的所有内容都位于一个文件中(扩展名为 .sqlite),您可以将其放在文件系统中的任何位置。这就是您使用它所需的全部内容!是的,没有要安装的“服务器”软件,也没有要连接的服务。
有用的功能
尽管 SQLite 是 MySQL 之类的数据库的轻量级替代品,但它还是很有冲击力的。它的一些令人震惊的特点是:
-
完全支持事务,包括 COMMIT、ROLLBACK 和 BEGIN。
-
支持每表32000列
-
JSON 支持
-
64路JOIN支持
-
子查询、全文搜索等
-
最大数据库大小为 140 TB!
-
最大行大小为 1 GB!
-
比文件 I/O 快 35%
何时使用 SQLite
SQLite 是一个非常专业的数据库,它专注于一种严肃的、一劳永逸的方法。如果您的应用程序相对简单,并且您不希望使用成熟的数据库带来麻烦,那么 SQLite 是一个不错的选择。这对于中小型 CMS 和演示应用程序特别有意义。
当不使用 SQLite 时
虽然令人印象深刻,但 SQLite 并未涵盖标准 SQL 或您最喜欢的数据库引擎的所有功能。缺少集群、存储过程和脚本扩展。此外,没有客户端可以连接、查询和探索数据库。最后,随着应用程序大小的增长,性能会下降。
卡桑德拉
尽管许多人宣称 Java 的末日即将来临,但每隔一段时间,社区就会投下重磅炸弹,让批评者闭嘴。Cassandra就是这样一个例子。
 Cassandra 属于所谓的“列”数据库家族。 Cassandra 中的存储抽象是一列而不是一行。这里的想法是将所有数据物理地存储在磁盘上的列中,从而最大限度地减少寻道时间。
Cassandra 属于所谓的“列”数据库家族。 Cassandra 中的存储抽象是一列而不是一行。这里的想法是将所有数据物理地存储在磁盘上的列中,从而最大限度地减少寻道时间。
独特的功能
Cassandra 的设计考虑到了一个特定的用例——处理写入繁重的负载和对停机时间的零容忍。这些成为其独特的卖点。
-
极快的写入性能。在处理繁重的写入负载时,Cassandra 可以说是目前最快的数据库。
-
线性可扩展性。也就是说,您可以根据需要不断向集群添加任意数量的节点,并且集群的复杂性或脆弱性将为零。
-
分区容差不匹配。也就是说,即使 Cassandra 集群中的多个节点出现故障,数据库也可以在不丢失完整性的情况下保持运行。
-
静态类型
何时使用 Cassandra
日志记录和分析是 Cassandra 的两个最佳用例。但这还不是全部——最佳时机是当您需要处理非常大的数据时(Apple 的 Cassandra 部署处理 400+ PB 的数据,而在 Netflix,它每天处理 1 万亿个请求)而停机时间几乎为零。高可用性是 Cassandra 的标志之一。
何时不使用 Cassandra
Cassandra 的列存储方案也有它的缺点。数据模型相当扁平,如果您需要聚合,那么 Cassandra 就达不到要求了。此外,它通过牺牲一致性来实现高可用性(请记住分布式系统的 CAP 定理),这使得它不太适合需要高读取精度的系统。
时标
新的发展需要新型数据库,而物联网 (IoT) 就是这样一种现象。最好的开源数据库之一是Timescale。
 时间刻度是一种所谓的“时间序列”数据库。它不同于传统的数据库,当时是关注的主轴,海量数据集的分析和可视化是重中之重。时间序列数据库很少看到现有数据发生变化;一个例子是温室中传感器发送的温度读数——新数据每秒都在不断积累,这对于分析和报告很有意义。
时间刻度是一种所谓的“时间序列”数据库。它不同于传统的数据库,当时是关注的主轴,海量数据集的分析和可视化是重中之重。时间序列数据库很少看到现有数据发生变化;一个例子是温室中传感器发送的温度读数——新数据每秒都在不断积累,这对于分析和报告很有意义。
那么,为什么不只使用带有时间戳字段的传统数据库呢?嗯,有两个主要原因:
通用数据库未针对使用基于时间的数据进行优化。对于相同数量的数据,通用数据库会慢得多。数据库需要处理大量数据,因为新数据不断涌入,以后删除数据或更改模式不是一种选择。独特的功能
Timescale DB 具有一些令人兴奋的特性,使其与同类数据库中的其他数据库区分开来:
它建立在 PostgreSQL 之上,可以说是目前最好的开源关系数据库。如果您的项目已经在运行 PostgreSQL,Timescale 将直接滑入。查询是通过熟悉的 SQL 语法完成的,从而减少了学习曲线。快得离谱的写入速度——每秒数百万次插入并非闻所未闻。数十亿行或 PB 的数据——这对 Timescale 来说没什么大不了的。架构的真正灵活性——根据您的需要从关系或无架构中进行选择。谈论何时使用或不使用 Timescale DB 没有多大意义。如果物联网是您的领域,或者您追求类似的数据库特征,那么 Timescale 值得一看。
沙发数据库
CouchDB是一个简洁的小型数据库解决方案,它静静地坐在角落里,拥有一个小而专注的追随者。它的创建是为了解决网络丢失和数据最终解析的问题,而这恰好是一个非常混乱的问题,以至于开发人员宁愿换工作而不是处理它。
 本质上,您可以将 CouchDB 集群视为大大小小的节点的分布式集合,其中一些预计会离线。一旦节点上线,它就会将数据发送回集群,这些数据会被缓慢而仔细地消化,最终可供整个集群使用。
本质上,您可以将 CouchDB 集群视为大大小小的节点的分布式集合,其中一些预计会离线。一旦节点上线,它就会将数据发送回集群,这些数据会被缓慢而仔细地消化,最终可供整个集群使用。
独特的功能
在数据库方面,CouchDB 是一个独特的品种。
-
离线优先数据同步能力
-
移动和网络浏览器的专用版本(PouchDB、CouchDB Lite 等)
-
抗碰撞,久经考验的可靠性
-
具有冗余数据存储的轻松集群
-
何时使用 CouchDB
CouchDB 是为离线容忍而构建的,在这方面仍然无与伦比。一个典型的用例是移动应用程序,其中您的一部分数据驻留在用户手机上的 CouchDB 实例上(因为这是生成数据的地方)。令人兴奋的是,您不能一直依赖用户的设备来连接,这意味着数据库必须是机会主义的,并准备好在以后解决冲突的更新。这是使用令人印象深刻的 Couch 复制协议实现的。
何时不使用 CouchDB
尝试在其预期用例之外使用 CouchDB 将导致灾难。它使用的存储空间比其他任何东西都多,仅仅是因为它需要维护数据的冗余副本和冲突解决结果。结果,写入速度也非常缓慢。最后,CouchDB 不适合作为通用模式引擎,因为它不能很好地适应模式更改。
结论
我不得不漏掉很多像 Riak 这样有趣的候选人,所以这份名单应该被当作指南而不是诫命。我希望我能够通过这篇文章实现我的目标——不仅提供数据库软件推荐的集合,而且还简要讨论了它们需要在哪里以及如何使用(并避免使用!)。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐
 0
0 0
0- 0



 已为社区贡献27134条内容
已为社区贡献27134条内容

所有评论(0)