
使用 Flyte Airflow Provider 为机器学习任务扩展 Airflow
Apache Airflow 是一个开源平台,可用于创作、监控和调度数据管道。它被 Airbnb、Lyft 和 Twitter 等公司使用,并且一直是数据工程生态系统中的首选工具。
随着数据管道编排需求的增加,Airflow 见证了巨大的增长。它已将其范围从数据扩展到机器学习,现在被用于各种用例。
但由于机器学习本身需要独特的编排,因此需要扩展 Airflow 以适应所有 MLOps 要求。
为了更好地理解这一点,让我们深入了解机器学习和 ETL(提取-转换-加载)任务与机器学习工程要求之间的区别。
机器学习与 ETL 任务
机器学习任务与 ETL 任务有不同的要求。
-
机器学习需要运行资源密集型计算。
-
机器学习需要适当的数据沿袭或数据感知平台来简化调试过程。
-
机器学习需要对代码进行版本控制以确保可重复性。
-
机器学习需要基础设施自动化。
此外,从静态工作流到动态工作流已经发生了重大转变,过程快速且不可预测,更多的计算能力被用于运行工作流,迭代是一种基本要求等;因此,处理管道的传统方式将不起作用。
为什么要延长气流?
Airflow 旨在协调数据工作流程。运行 ETL/ELT 任务非常有用,因为它可以轻松连接到一组标准的第三方源以实现数据编排。然而,机器学习从业者有额外的要求。
-
资源密集型任务:Airflow 没有提出直接的方法来处理这个问题,但是,您可以使用KubernetesPodOperator通过容器化代码来克服资源限制。
-
数据沿袭:Airflow 不是数据感知平台;它只是构建流程,但忽略了包含传递数据的内部细节。
-
版本控制:已经有一些间接技术来处理 Airflow 中代码的版本控制,但它仍然不是一个明显的功能。此外,Airflow 也不支持重新访问 DAG 并按需重新运行工作流。
-
基础设施自动化:在大多数情况下,机器学习代码需要高处理能力。但是,我们不希望在工作流未运行或工作流中的某些任务不需要更多计算能力时保持资源空闲——这很难通过 Airflow 实现。
-
缓存:缓存任务输出可以帮助加快执行速度并消除资源的重用,这也是 Airflow 不支持的。
Airflow 支持利用 Amazon Sagemaker 和 Databricks 等运营商构建机器学习管道。问题是我们不会获得所有编排收益,并且在 Airflow 端无法确保可重复性或任何上述保证。简而言之,这个场景中缺少的基本部分是_细粒度的机器学习编排_。
想象一个场景,机器学习工程师被带入数据工程师建立的现有 Airflow 项目中。由于 Airflow 主要是一个面向数据编排的平台,因此在术语、概念方法以及对每个团队的工作努力缺乏理解方面往往存在如此大的差距。让 Airflow 成为一个成熟的机器学习编排服务需要比平时更大的努力,毕竟考虑到 Airflow 对 ETL 的倾向,这可能不是正确的选择。
也就是说,Airflow 仍可用于构建“静态”机器学习管道,但如果您的用例是为了适应围绕机器学习不断发展和快节奏的生态系统,并极度关注迭代(以及当然,部署),您可能必须扩展 Airflow。
气流 + Flyte u003d 最大灵活性
Flyte 的诞生是为了解决 Airflow 带来的挑战,尤其是对机器学习工程师、从业者和数据科学家而言。它是建立在 Kubernetes 之上的成熟工作流编排服务,可确保机器学习管道的可扩展性。那么,为什么不利用 Airflow 和 Flyte 两全其美来扩展 Airflow 以完成机器学习任务?
介绍Flyte Airflow Provider。您现在可以在 Airflow 中构建 ETL 管道,在 Flyte 中构建机器学习管道,并使用提供程序从 Airflow 中触发机器学习或 Flyte 管道。
如果您是 Airflow 的长期用户,您可以零敲碎打地编写代码,而不必担心 Airflow 和 Flyte 是如何交织在一起的。
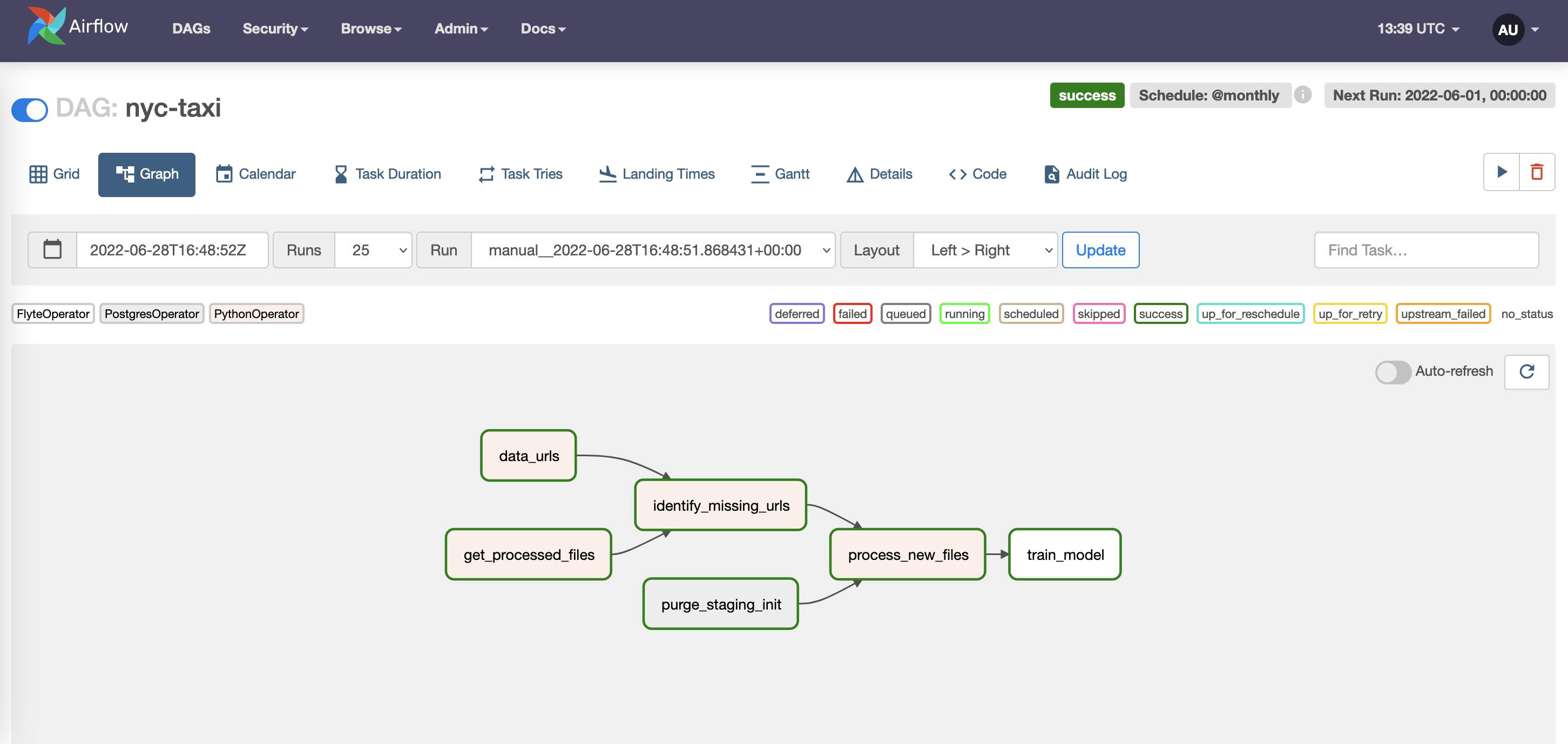 Airflow UI 上的示例 DAG,其中
Airflow UI 上的示例 DAG,其中train_model是FlyteOperator。
浮点运算符
您可以使用FlyteOperator从 Airflow 中触发 Flyte 执行(无论是任务还是工作流执行),在此之前您必须在后端注册您的 Flyte 工作流。在触发 Airflow DAG 时,会触发相应的 Flyte 执行,瞧!您将在 Airflow 中获得 Flyte 的所有好处。
流量传感器
如果您需要等待执行完成,FlyteSensor出现在图片中。使用FlyteSensor进行监控允许您仅在 Flyte 执行完成时触发下游流程。
示例
在安装和设置 Airflow之后,将以下内容放在dags/目录下。
from datetime import datetime, timedelta
from airflow import DAG
from flyte_provider.operators.flyte import FlyteOperator
from flyte_provider.sensors.flyte import FlyteSensor
with DAG(
dag_id="example_flyte",
schedule_interval=None,
start_date=datetime(2021, 1, 1),
dagrun_timeout=timedelta(minutes=60),
catchup=False,
) as dag:
task = FlyteOperator(
task_id="diabetes_predictions",
flyte_conn_id="flyte_conn",
project="flytesnacks",
domain="development",
launchplan_name="ml_training.pima_diabetes.diabetes.diabetes_xgboost_model",
inputs={"test_split_ratio": 0.66, "seed": 5},
)
sensor = FlyteSensor(
task_id="sensor",
execution_name=task.output,
project="flytesnacks",
domain="development",
flyte_conn_id="flyte_conn",
)
task >> sensor
pima_diabetesPython 文件的源代码在这里可用。
将airflow-provider-flyte添加到requirements.txt文件中,并通过将Conn Id设置为flyte_conn并将Conn Type设置为 Flyte 来创建到 Flyte 的 Airflow 连接。
! zoz100040 Flyte 执行 UI。](https://cdn.hashnode.com/res/hashnode/image/upload/v1657188030973/h0lv2emYi.png?auto=compress,format&format=webp)Flyte exkytyon OI.
在 Airflow 或 Flyte 端终止执行时,相关事件将传播到另一个平台并取消执行。如果 Flyte 端执行失败,Airflow 端的执行也会失败。
如果您想了解此提供程序的实际用例,请观看这个视频。它演示了从 S3 提取纽约出租车数据、将其上传到 CrateDB 并构建 XGBoost 模型的示例。
Airflow 是运行 ETL 管道的强大工具;但是,需要扩展 Airflow 以运行机器学习管道。
使用 Flyte,您可以对代码进行版本控制、审计数据、重现执行、缓存输出和插入检查点,而无需考虑机器学习管道的可扩展性。试试 Flyte Airflow Provider,并在Slack上与我们分享您的示例用例!

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐
 0
0 0
0- 0



 已为社区贡献27131条内容
已为社区贡献27131条内容

所有评论(0)