
Google、Amazon 和 Pinterest 中的自动更正以及如何编写自己的
在本文中,我将解释什么是搜索功能领域的拼写纠正,它在 Google、Amazon 和 Pinterest 中的工作原理,并将演示如何使用自定义搜索引擎 Manticore Search 从头开始实现您自己的实现 拼写更正也称为: 自动校正 文字修正 修复拼写错误 错字容差 “你的意思是?” 等等是一种软件功能,可以建议您替代或自动更正您输入的文本。 卡内基梅隆大学界面设计教授布拉德迈尔斯说,纠正打
在本文中,我将解释什么是搜索功能领域的拼写纠正,它在 Google、Amazon 和 Pinterest 中的工作原理,并将演示如何使用自定义搜索引擎 Manticore Search 从头开始实现您自己的实现
拼写更正也称为:
-
自动校正
-
文字修正
-
修复拼写错误
-
错字容差
-
“你的意思是?”
等等是一种软件功能,可以建议您替代或自动更正您输入的文本。
卡内基梅隆大学界面设计教授布拉德迈尔斯说,纠正打字文本的概念可以追溯到 1960 年代。就在这时,一位名叫 Warren Teitelman 的计算机科学家也发明了“撤消”命令,他提出了一种名为 D.W.I.M. 或“Do What I mean”的计算哲学。 Teitelman 说我们应该对计算机进行编程以识别明显的错误,而不是让计算机只接受格式完美的指令。
第一个提供拼写纠正功能的知名产品是 1993 年发布的 Microsoft Word 6.0。
如今,如果没有消息传递、搜索、浏览和使用不同的业务应用程序,人们无法想象他们的真实生活:文本编辑器、内容管理系统 (CMS)、客户关系管理系统 (CRM) 等。在所有这些人中,人们都会犯打字错误,忘记正确的单词拼写,有时会出现语法错误等等。这绝对没问题,每个人都会犯错。一个好的软件所做的就是帮助您以最简单和最有效的方式修复这些错误。它有很多方法可以做到这一点:从它如何寻找用户、它带来什么价值以及它是如何在幕后制作的。
在本文中,我们将特别关注搜索系统,因为对于它们而言,在处理之前(或期间)更正您的搜索查询尤为重要,否则您的搜索结果可能绝对错误。
自动更正的不同方法
在用户体验方面,我们可以将这些方法分为两组:
-
在第一个中,系统会在您键入文本时尝试更正您的文本
-
在另一个中它认为它是给定的,然后给你建议
在大多数情况下,这些方法会结合使用,因此系统会在您键入时尝试纠正您,并且如果它认为仍然存在一些问题 - 在您获得搜索结果后建议您进行更正。
[
-
Autocorrect — 立即更正错误类型的查询
-
自动完成 — 许多现代网站的另一个重要功能,通常与自动更正功能结合使用
-
建议——这是一种自动完成和自动更正的混合体,通常看起来像是在暗示你与你输入的内容有点不同,但仍然有意义(见下图)
-
突出显示错误 - 另一个不错的功能是错误突出显示。它也可以在您键入时和之后完成
-
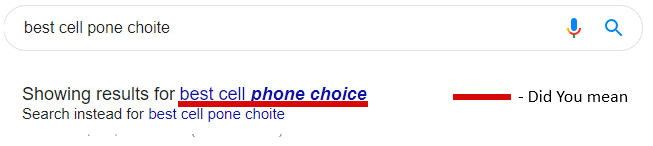
“您的意思是” - 许多系统建议您不仅在您输入时优化搜索查询,而且在显示搜索结果时也是如此。我们称之为“你的意思是......?”。反过来有两种模式:
-
按您的原始搜索查询进行搜索,然后向您显示推荐的查询(就像 Google 所做的那样)
-
或者按细化搜索,建议“改为搜索”
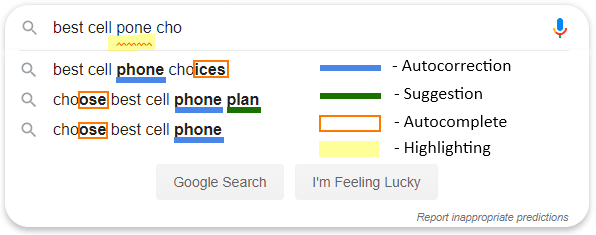
键入组件时:
[
查询后:
[
让我用图片向您展示不同的流行网站如何使用上述技术。
Google 作为互联网上排名第一的网站,可以做所有事情:自动更正、自动完成、建议、错误突出显示和“您的意思是”。 Google 使用预测服务来帮助完成搜索,甚至是在地址栏中键入的 URL:这些建议或预测(作为 Google 名称)基于相关的网络搜索、您的浏览历史记录和 Google 的网站排名。
[
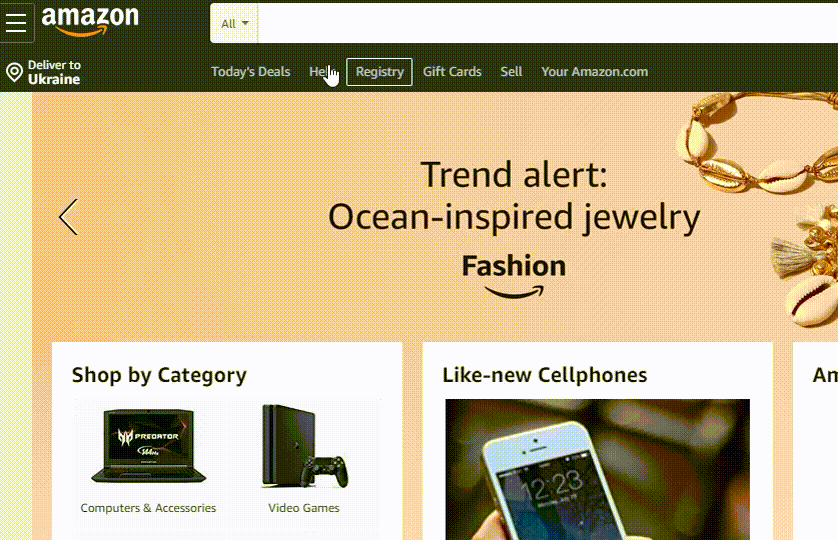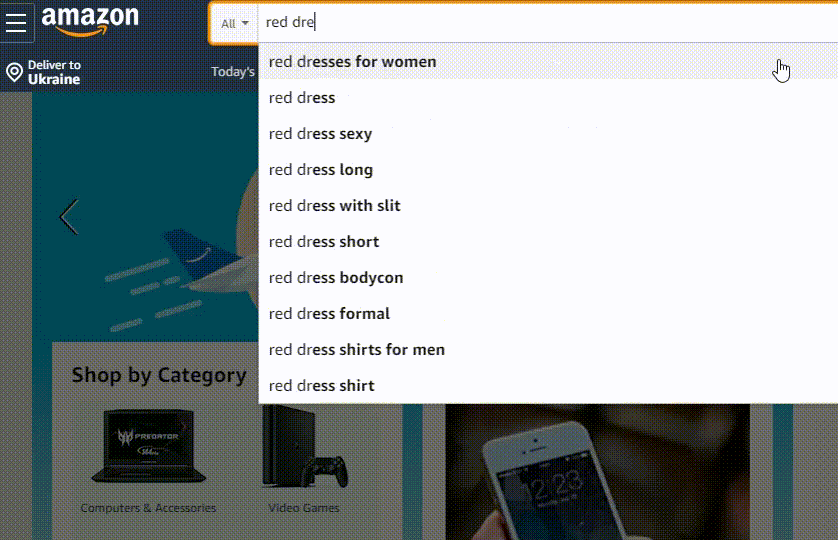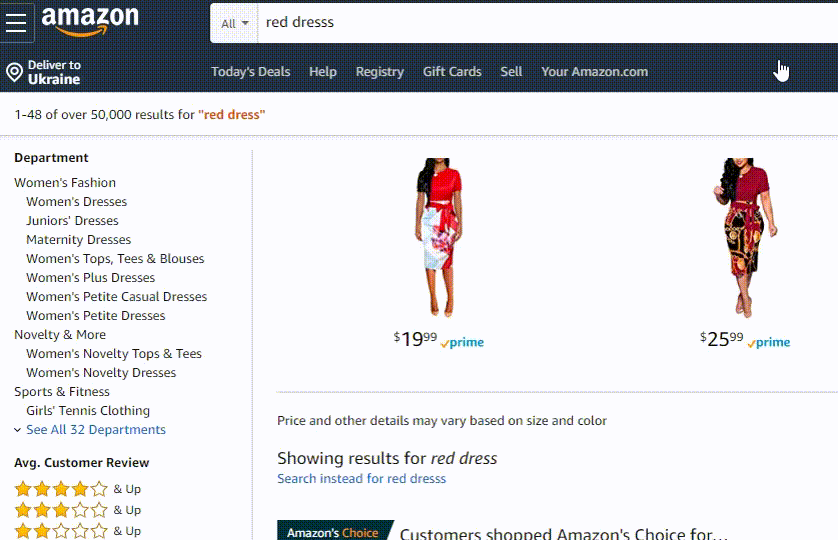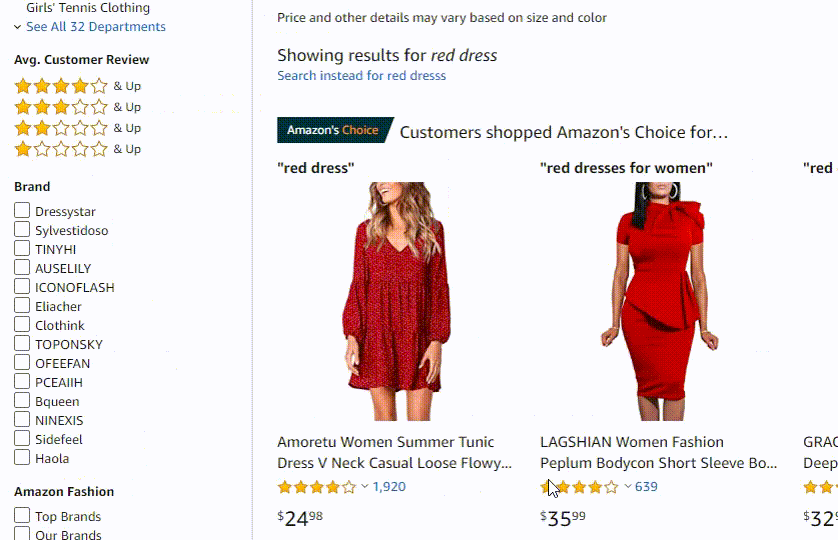
Amazon 使用称为 A9 的面向电子商务的搜索算法。它与谷歌算法的不同之处在于它非常强调销售转化。
就亚马逊的自动更正实施而言,它由前面提到的所有组件组成,但由于它是一个市场,它的建议排名公式似乎包括一个建议在销售方面对你的吸引力的因素。
[
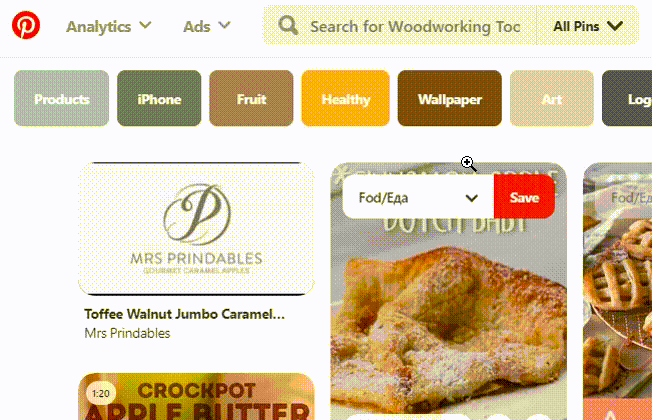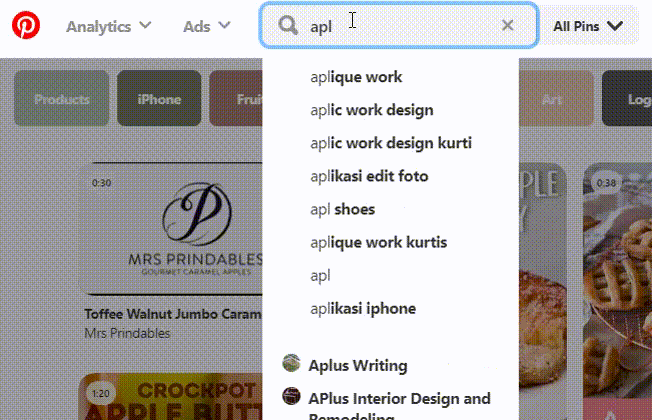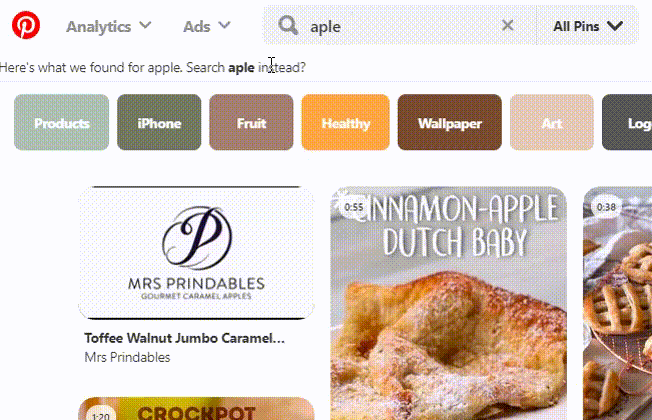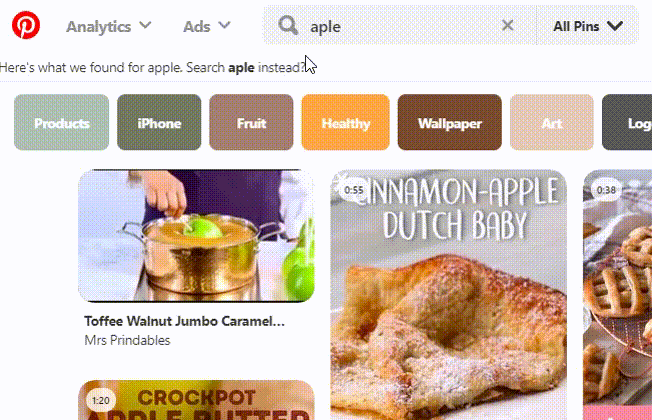
Pinterest 也有自己的基于内部域/pins/pinners 相关性的算法。
[
工作原理
现在让我们考虑如何进行拼写校正。方法很少,但重要的是,没有纯粹的编程方式可以将您输入错误的“ipone”转换为“iphone”(至少质量不错)。大多数情况下,必须有一个系统所基于的数据集。数据集可以是:
- 正确拼写单词的字典。反过来,它可以是:
- 基于您的真实数据。这里的想法是,大多数情况下,在由您的数据组成的字典中,拼写是正确的,然后对于每个键入的单词,系统只是试图找到一个与之最相似的单词(我们将讨论如何准确地完成它不久)
2.或者可以基于与您的数据无关的外部字典。这里可能出现的问题是您的数据和外部字典可能相差太大:字典中可能缺少某些单词,您的数据中可能缺少某些单词。例如。就像在这些情况下:

但是对于较小的数据集合可能仍然有意义,因为这样搜索查询被更正的可能性就更高
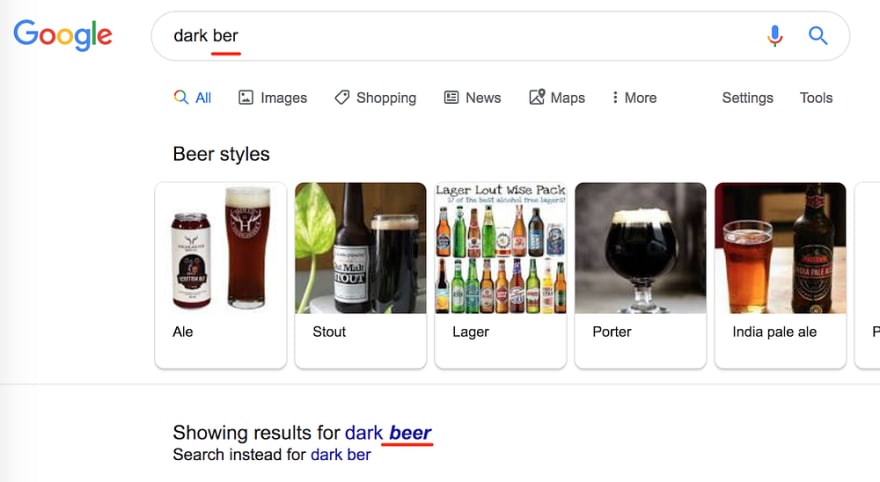
- 不仅基于字典,而且 context-aware,就像如果我搜索“white ber” Google 明白我的意思是熊:
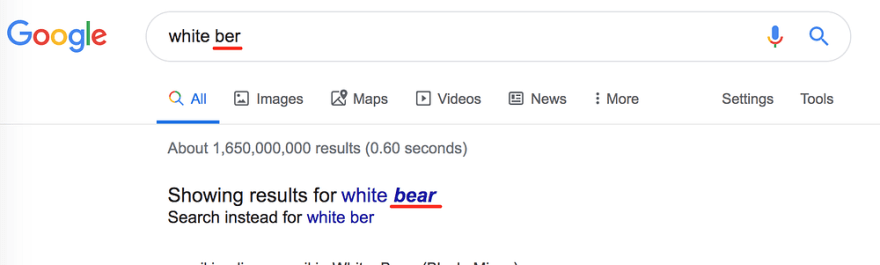
但是,如果我将其更改为“dark ber”,它就会明白我的意思是啤酒:
[
上下文可能不仅仅是您查询中的相邻词,还包括您的位置、时间日期、当前句子的语法(比如将“那里”更改为“他们的”或没有)、您的搜索历史以及几乎任何其他可以影响你的意图。
-
另一种经典方法是使用以前的搜索查询作为拼写校正的数据集。它甚至更多地用于自动完成功能,但也适用于自动更正。这里的想法是大多数用户的拼写是正确的,因此我们可以使用他们搜索历史中的单词作为事实来源,即使我们的文档中没有单词也没有使用外部词典。上下文感知在这里也是可能的。
-
另一种方法是使用用户以前的搜索查询和/或您的字典和/或文档来找出一些更正规则,并仅使用它们来更正新的搜索查询。甚至还有关于这个的专利 https://patents.google.com/patent/US6618697B1/en
对于所有方法,都可以使用不同的算法来搜索和评估候选拼写校正:
-
从最简单的开始,例如将给定单词与字典中的所有单词进行比较
-
早期拒绝允许显着缩小候选人列表的算法(我们将在下面详细介绍)
-
不同种类的有限自动机以提高寻找候选者的性能(Lucene 的方式)
-
概率模型,例如Etsy 基于先前搜索查询使用的隐马尔可夫模型
-
到通常需要大量训练数据的不同机器学习技术
看看最近人工智能、机器学习和语义搜索的发展速度有多快,我相信在这十年中,拼写纠正技术的前景可能会发生巨大变化,但目前上述方法似乎是最常用的。大多数解决方案都基于您现有的数据收集和由它组成的字典。
如何编写自定义自动更正
在这里,我将描述我自己在 Manticore Search 的帮助下进行网站搜索的部分经验。大约一年前,我在处理一些客户项目时发现了这个产品,由于它的轻量级和快速搜索以及许多开箱即用的功能,我仍在我的几个项目中使用它。
现在让我们谈谈您可以使用哪些工具将自动更正功能添加到您的系统中,同时更深入地了解至少更简单的技术是如何工作的。
Todo 我们将采用流行的自定义搜索引擎之一,因为它们通常提供我们正在寻找的功能。我喜欢 Manticore Search,因为与更知名的 Elasticsearch 相比,它更轻量级,更容易处理,因为它是 SQL 原生的,并且在大多数情况下运行速度更快。它是如此原生的 SQL,您甚至可以使用标准的 MySQL 客户端连接到它。他们提供了一个官方的 docker 镜像,所以我将使用它来演示自动更正在 Manticore Search 中的工作原理:
➜ ~ docker run --name manticore -d manticoresearch/manticore
1ac28e94b3ca728fb431ba79255f81eb31ec264b5d9d49f1d2db973e08a32b9f
在容器内,我将运行 mysql 以连接到那里运行的 Manticore Search 服务器:
➜ ~ docker exec -it manticore mysql
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.5.21
Copyright © 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
它附带 2 个测试表,我们可以使用它们快速进行拼写校正:
MySQL [(none)]> show tables;
+--------+-----------+
| Index | Type |
+--------+-----------+
| pq | percolate |
| testrt | rt |
+--------+-----------+
2 rows in set (0.00 sec)
让我们检查一下 testrt 的架构:
MySQL [(none)]> describe testrt;
+---------+--------+------------+
| Field | Type | Properties |
+---------+--------+------------+
| id | bigint | |
| title | field | stored |
| content | field | stored |
| gid | uint | |
+---------+--------+------------+
4 rows in set (0.00 sec)
并在其中插入一些文档。让它成为电影标题:
MySQL [(none)]> insert into testrt(title) values('The Godfather'),('The Wizard of Oz'),('Combat!'),('The Shawshank Redemption'),('Pulp Fiction'),('Casablanca'),('The Godfather: Part II'),('Mortal Kombat'),('2001: A Space Odyssey'),('Schindler\'s List');
Query OK, 10 rows affected (0.00 sec)
我们现在可以在索引中看到我们所有的文档:
MySQL [(none)]> select * from testrt;
+---------------------+------+--------------------------+---------+
| id | gid | title | content |
+---------------------+------+--------------------------+---------+
| 1657719407478046741 | 0 | The Godfather | |
| 1657719407478046742 | 0 | The Wizard of Oz | |
| 1657719407478046743 | 0 | Combat! | |
| 1657719407478046744 | 0 | The Shawshank Redemption | |
| 1657719407478046745 | 0 | Pulp Fiction | |
| 1657719407478046746 | 0 | Casablanca | |
| 1657719407478046747 | 0 | The Godfather: Part II | |
| 1657719407478046748 | 0 | Mortal Kombat | |
| 1657719407478046749 | 0 | 2001: A Space Odyssey | |
| 1657719407478046750 | 0 | Schindler's List | |
+---------------------+------+--------------------------+---------+
10 rows in set (0.00 sec)
刚刚发生的事情:当我们插入标题时,不仅 Manticore Search 按原样保存了它们,而且它为自然语言处理 (NLP) 做了很多必不可少的事情:标记化(将标题拆分为单词)、规范化(将所有内容小写) ) 和许多其他事情,但对我们来说有一个重要的事情就是它将单词拆分为它们所组成的三元组。例如“战斗!” (或者实际上是标准化后的“战斗”)被拆分为“com”、“omb”、“mba”、“bat”。那为什么这很重要?
为了回答这个问题,让我们假设我们在“combat”中输入错误并改为输入“combat”。我们现在希望找到“战斗”,我们将如何做到这一点?选项包括:
-
我们可以遍历整个字典并将每个单词与我们的关键字(“comabt”)进行比较,然后我们将评估这两个单词之间的差异。它被称为 Levenshtein 距离。对于给定的一对单词,计算它的方法很少,但问题是,即使你可以对 2 个单词进行如此快速的计算,也可能需要一段时间才能将字典中的每个单词与给定单词进行比较
-
因此,最好不要比较所有字典单词,而只比较那些更有可能成为给定单词更正的单词。这里出现了 trigrams 的概念——如果我们将所有字典单词拆分为 trigrams 和搜索关键字,我们现在可以操作这些较小的标记来查找候选词。
所以在这种情况下,内部所做的是 Manticore Search 首先将“comabt”拆分为中缀:“com”、“oma”、“mab”和“abt”,然后在字典中找到相应的单词,就像插入文档时一样也做了同样的事情。由于该算法的复杂度不是很高(远低于将每个单词相互比较),Manticore 很快发现有一个单词“combat”,其中也有“com”,并且它是唯一的候选词。因此,之后要做的就是确保候选词与给定词没有太大差异。它计算 Levensthein 距离,认为它不大于限制(默认为 4)并返回候选:
MySQL [(none)]> call qsuggest('comabt', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 2 | 1 |
+---------+----------+------+
1 row in set (0.00 sec)
在其他情况下,可能会有更多的候选人。例如,如果您搜索“combat”,字典中有一个单词与您的查询完全匹配(Levenshtein 距离为 0),但您可能指的是另一个单词,CALL SUGGEST 也会返回它:
MySQL [(none)]> call qsuggest('combat', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 0 | 1 |
| kombat | 1 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
如果您输入 2 个字 CALL QSUGGEST 只处理您的最后一个:
MySQL [(none)]> call qsuggest('mortal combat', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 0 | 1 |
| kombat | 1 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
那么如何在我的应用程序中使用这个功能呢?”你可能会问。这很简单。只是:
-
在每个新字符之后继续将搜索查询发送到 CALL QSUGGEST
-
并将其输出给用户
这是在我们的数据集的情况下它将给出的日志,注意输入(在“call qsuggest”之后)和输出(在“suggest”列中):
MySQL [(none)]> call qsuggest('m', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mo', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mor', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mort', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| mortal | 2 | 1 |
+---------+----------+------+
1 row in set (0.01 sec)
MySQL [(none)]> call qsuggest('morta', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| mortal | 1 | 1 |
+---------+----------+------+
1 row in set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| mortal | 0 | 1 |
+---------+----------+------+
1 row in set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal c', 'testrt');
Empty set (0.01 sec)
MySQL [(none)]> call qsuggest('mortal co', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal com', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal comb', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 2 | 1 |
| kombat | 3 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal comba', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 1 | 1 |
| kombat | 2 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal combat', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 0 | 1 |
| kombat | 1 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
结论
-
自动更正是许多系统中常用的一个非常好的功能,它可以帮助用户找到更好的结果,并且网站所有者不会因为输入错误或不正确的查询而失去对没有结果感到沮丧的用户
-
实现方式有很多种
-
谷歌、亚马逊、Pinterest、Etsy 和其他大型网站的实现似乎相当复杂,并且基于非平凡的算法
-
但在许多情况下,更简单的事情也可能有意义
-
Manticore Search 可用于提供所需的功能。顺便说一下,他们的网站](https://play.manticoresearch.com/didyoumean/)上有关于它的互动课程[

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐
 0
0 0
0- 0



 已为社区贡献27141条内容
已为社区贡献27141条内容

所有评论(0)