
使用 Superset 和 Cube 构建指标仪表板
TL;DR:在本教程中,我们将学习如何使用 Apache Superset(一个现代的开源数据探索和可视化平台)构建指标仪表板。我们还将使用开源指标存储 Cube 作为 Superset 的数据源,这将使我们的仪表板能够在一秒钟内加载——这与您通常对 BI 工具的期望完全相反,对吧?
最终结果如下所示:
[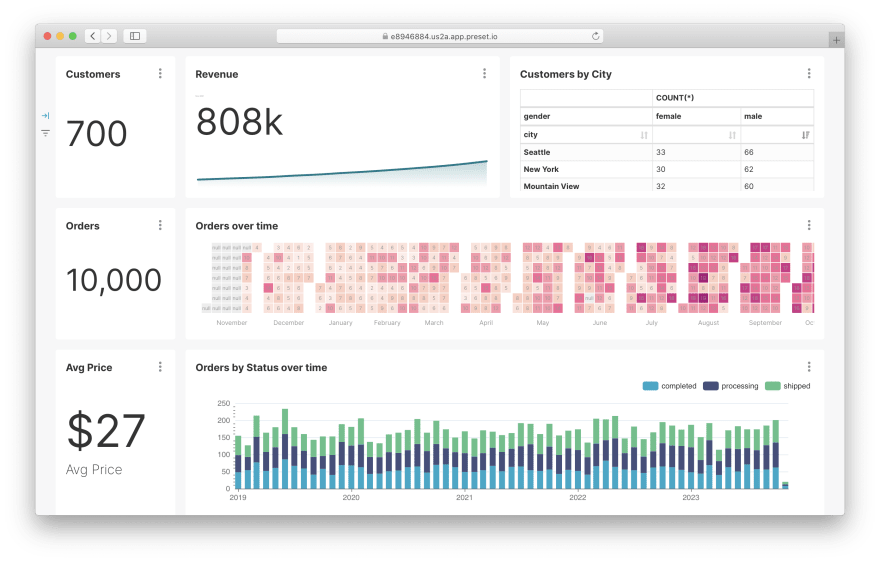 ](https://res.cloudinary.com/practicaldev/image/fetch/s--jZV2lfdf--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/11d780fa-b9b3-45d2-af61-e1f3ce270731.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--jZV2lfdf--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/11d780fa-b9b3-45d2-af61-e1f3ce270731.png)
现在我们都准备好了。让我们看看这个指标商店的货架上有什么🏪
什么是 Apache 超集?
Apache Superset是一个数据探索和可视化平台,或者通俗地说,是一个工具,您可以使用它为内部用户构建带有图表的仪表板。 2015 年诞生于 Airbnb 的一场黑客马拉松,在 GitHub 上有超过 41,000 颗星,现在它是领先的开源商业智能工具。
Superset 有许多数据库的连接器,从 Amazon Athena 到 Databricks 到 Google BigQuery 到 Postgres。它提供了基于 Web 的 SQL IDE 和用于构建图表和仪表板的无代码工具。
运行 Superset。 现在让我们运行 Superset 来探索这些功能。为简单起见,我们将在Preset Cloud中运行完全托管的 Superset,您可以在 Starter 计划中永久免费使用它。 (如果您想使用 Docker 在本地运行 Superset,请参阅这些说明。)
首先,请前往注册页面并填写您的详细信息。请注意,Preset Cloud 支持使用您的 Google 帐户注册。在几秒钟内,您将被带到您的帐户,并提供一个现成的工作区:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--vk-Wls2l--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/8cc1e93b-3cd2-4232-b723-8f3b99f42324.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--vk-Wls2l--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/8cc1e93b-3cd2-4232-b723-8f3b99f42324.png)
切换到该工作区将显示一些示例仪表板,您可以稍后查看。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--EonV7E9d--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/91134cc7-13e7-46de-b924-75c606c9fbbd.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--EonV7E9d--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/91134cc7-13e7-46de-b924-75c606c9fbbd.png)
现在,让我们通过顶部菜单导航到Data / Databases,然后......哎呀!我们需要一个指标存储来连接。让我们看看 Cube 如何帮助我们构建一个。
什么是立方体?
Cube是一个开源的指标存储,迄今为止在GitHub上有近 12,000 颗星。它作为所有指标的单一事实来源,并提供 API 用于支持 BI 工具和构建数据应用程序。您可以将 Cube 配置为连接到任何数据库,通过声明性数据模式定义指标,并立即获得可与 Superset 或许多其他 BI 工具一起使用的 API。
运行 Cube。 与 Superset 类似,让我们在Cube Cloud中运行一个完全托管的 Cube,它也有免费计划。 (如果您想使用 Docker 在本地运行 Cube,请参阅这些说明。)
首先,请前往注册页面并填写您的详细信息。请注意,Cube Cloud 支持使用您的 GitHub 帐户注册。在几秒钟内,您将被带到您的帐户,您可以在其中创建您的第一个 Cube 部署:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--b9WM8Wld--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/1ccba445-9cbf-4bb6-acfe-1e3c1d2fa325.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--b9WM8Wld--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/1ccba445-9cbf-4bb6-acfe-1e3c1d2fa325.png)
继续为您的部署提供名称,选择云提供商和区域:
[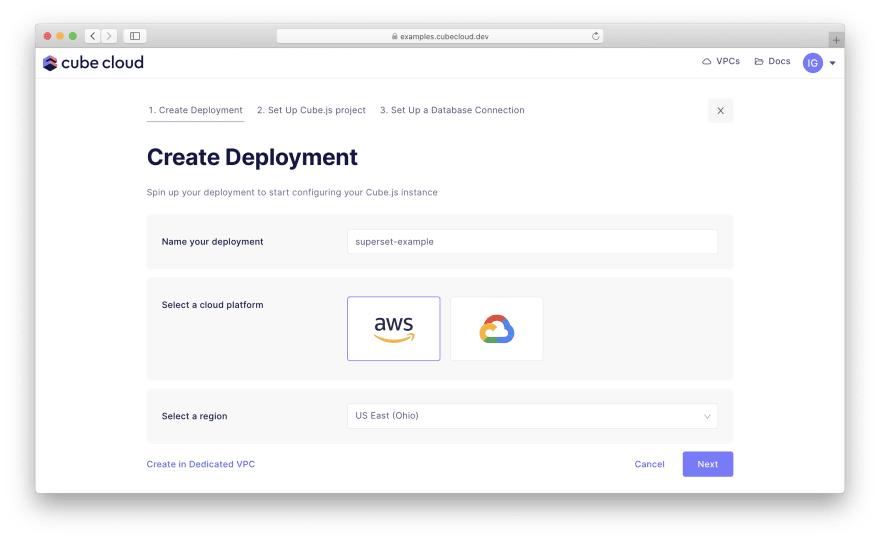 ](https://res.cloudinary.com/practicaldev/image/fetch/s--hptldz-n--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/28ad847d-10f6-47ed-8bf5-66a2b441eef3.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--hptldz-n--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/28ad847d-10f6-47ed-8bf5-66a2b441eef3.png)
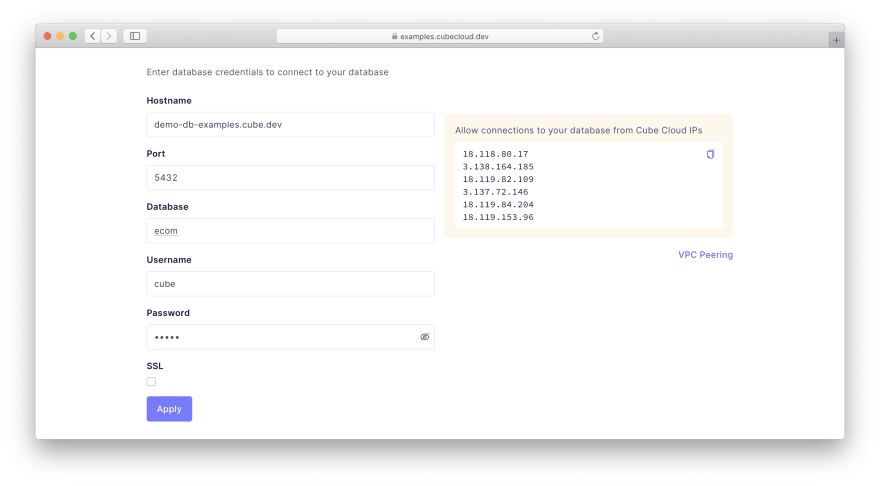
下一步,选择Create从头开始一个新的 Cube 项目。然后,选择Postgres进入可以输入以下凭据的屏幕:
Hostname: demo-db-examples.cube.dev
Port: 5432
Database: ecom
Username: cube
Password: 12345
进入全屏模式 退出全屏模式
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--f9lyB6RA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/835c5600-7f79-44b3-81c1-3726a787c440.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--f9lyB6RA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/835c5600-7f79-44b3-81c1-3726a787c440.png)
Cube 将连接到我已经设置的公开可用的 Postgres 数据库。
配置的最后一部分是数据架构,它以声明方式描述了我们将放在仪表板上的指标。实际上,Cube 可以为我们生成它!从列表中选择顶级public数据库:
[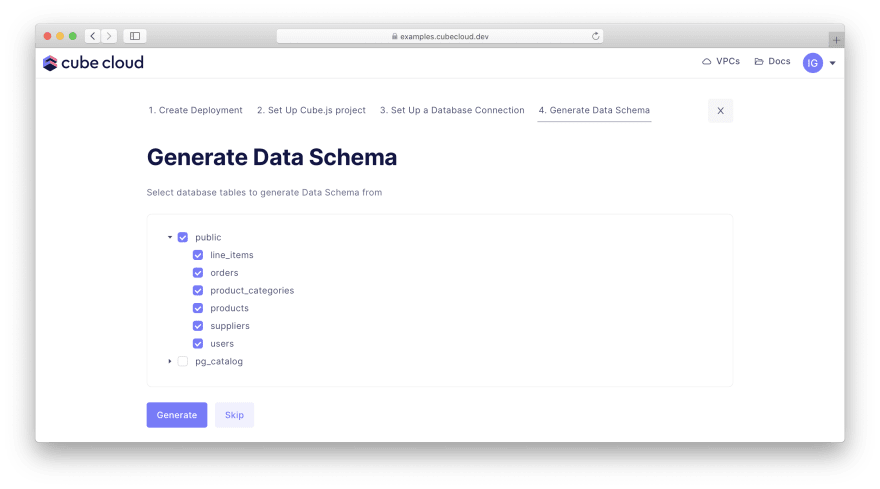 ](https://res.cloudinary.com/practicaldev/image/fetch/s--eylAvg5G--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/c721028f-e20c-425c-900d-75b9f294a3bc.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--eylAvg5G--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/c721028f-e20c-425c-900d-75b9f294a3bc.png)
稍后,您的 Cube 部署将启动并运行:
[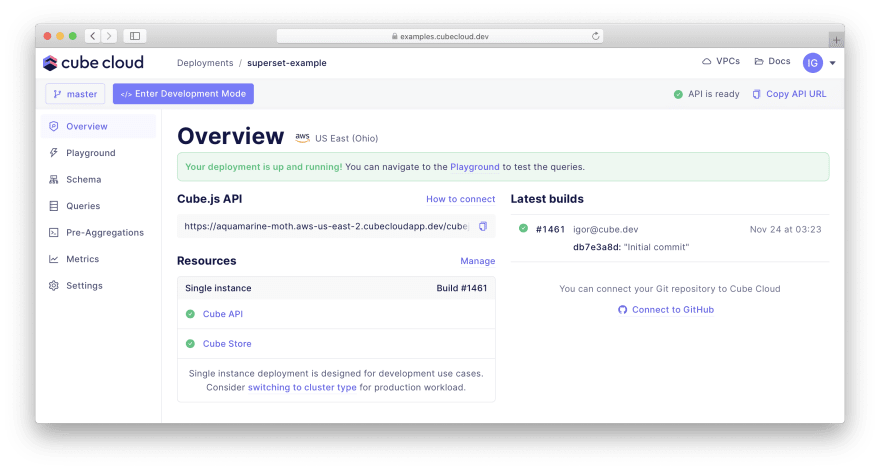 ](https://res.cloudinary.com/practicaldev/image/fetch/s--x7Ge33SM--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/5c39e57e-3311-4f40-9b89-8bc40d49df00.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--x7Ge33SM--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/5c39e57e-3311-4f40-9b89-8bc40d49df00.png)
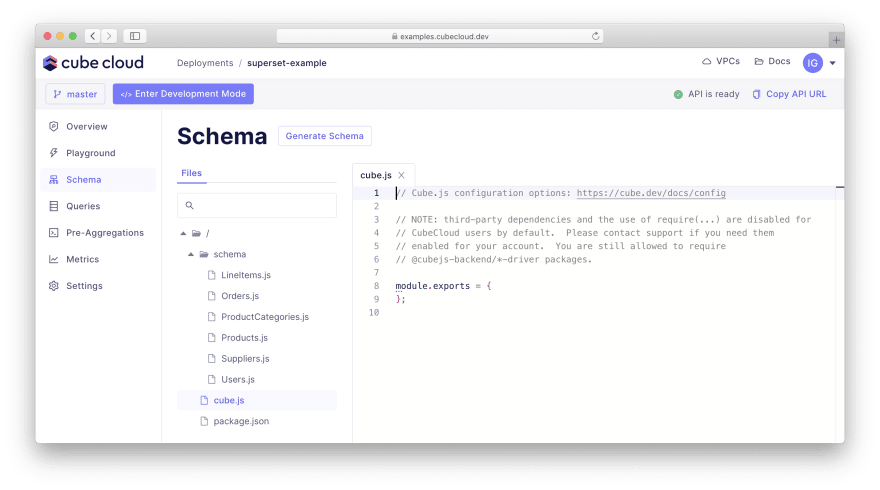
定义指标。 请导航到“架构”选项卡。您将在“schema”文件夹下看到LineItems.js、Orders.js、Users.js等文件。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--ss-Xd9bO--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/8fb089b2-f33a-4795-9450-9f564dbd40d4.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--ss-Xd9bO--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/8fb089b2-f33a-4795-9450-9f564dbd40d4.png)
让我们回顾一下LineItems.js,它定义了“LineItems”多维数据集中的指标。此文件与 Cube Cloud 中的文件不同,但我们稍后会处理。
cube(`LineItems`, {
sql: `SELECT * FROM public.line_items`,
measures: {
count: {
type: `count`
},
price: {
sql: `price`,
type: `sum`
},
quantity: {
sql: `quantity`,
type: `sum`
},
// A calculated measure that reference other measures.
// See https://cube.dev/docs/schema/reference/measures#calculated-measures
avgPrice: {
sql: `${CUBE.price} / ${CUBE.quantity}`,
type: `number`
},
// A rolling window measure.
// See https://cube.dev/docs/schema/reference/measures#rolling-window
revenue: {
sql: `price`,
type: `sum`,
rollingWindow: {
trailing: `unbounded`,
},
}
},
dimensions: {
id: {
sql: `id`,
type: `number`,
primaryKey: true
},
createdAt: {
sql: `created_at`,
type: `time`
}
},
dataSource: `default`
});
进入全屏模式 退出全屏模式
这里的主要学习:
-
多维数据集是将度量和维度组合在一起的逻辑实体
-
使用
sql语句,这个多维数据集定义在整个public.line_items表上;实际上,可以在选择数据的任意 SQL 语句上定义多维数据集 -
个度量(定量数据)被定义为数据集中列上的聚合(例如,
count、sum等)
在数据集中的文本、数字或时间列上定义了* 个维度(定性数据)
- 您可以使用自定义
sql语句或对其他度量的引用来定义复杂的度量和维度
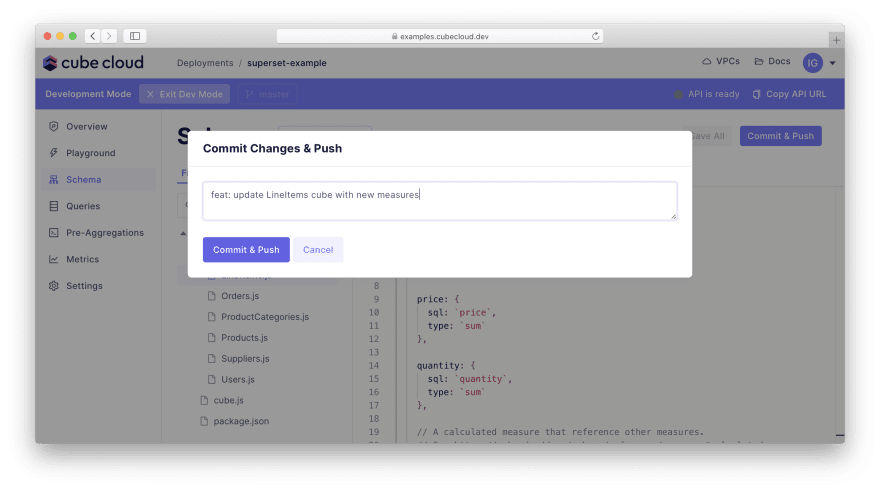
**开发模式。**现在,让我们更新 Cube Cloud 中的模式文件以匹配上面的内容。首先,单击Enter Development Mode解锁模式文件以进行编辑。这实质上创建了 Cube API 的“分支”,用于跟踪您在数据模式中的更改。
导航到LineItems.js并将其内容替换为上面的代码。然后,通过单击Save All将更改应用到 API 的开发版本来保存更改。您可以根据需要应用任意数量的更改,但我们现在已经完成了。单击Commit & Push将您的更改合并回主分支:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--E8MrCxsY--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/85eeca4a-e85f-4109-8459-4dbde074d005.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--E8MrCxsY--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/85eeca4a-e85f-4109-8459-4dbde074d005.png)
在“概述”选项卡上,您将看到已部署的更改:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--8e6ipaci--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/5e7746a3-8839-47e3-bddc-a8b67460207a.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--8e6ipaci--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/5e7746a3-8839-47e3-bddc-a8b67460207a.png)
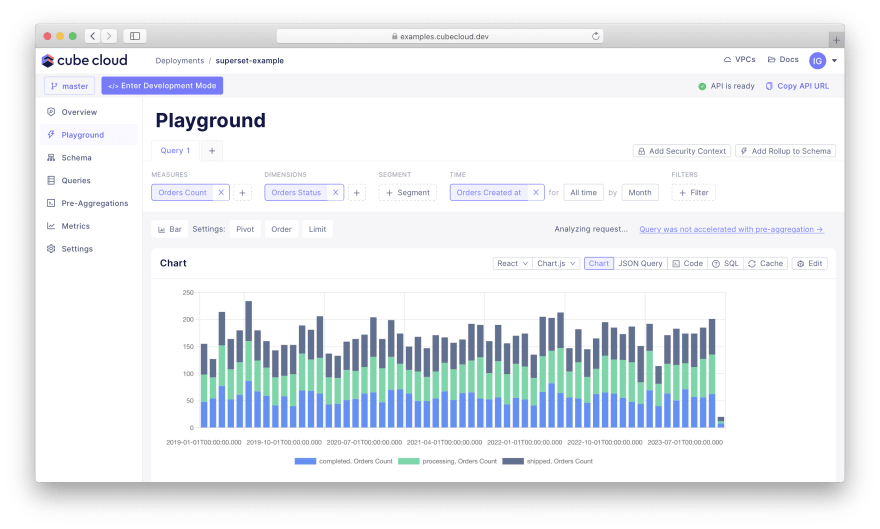
现在您可以在“Playground”选项卡上探索指标:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--snB-CDlK--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/df9a8062-4026-4476-8c65-b10e1360075e.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--snB-CDlK--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/df9a8062-4026-4476-8c65-b10e1360075e.png)
好的!我们已经建立了一个可以连接到 Superset 的指标存储。如何?
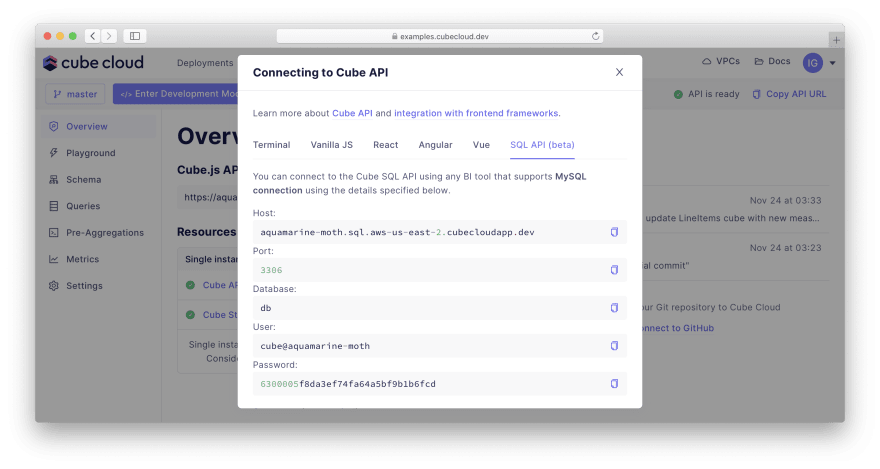
请返回“Overview”选项卡并单击How to connect。“SQL API”选项卡将有一个开关,可以启用 Superset 和其他 BI 工具的 API。打开它将为您提供所有必要的凭据:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--C2Akl2g_--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/e2751eeb-c7bb-4f8d-9ff9-d6184097e9ce.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--C2Akl2g_--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/e2751eeb-c7bb-4f8d-9ff9-d6184097e9ce.png)
现在,让我们构建一个仪表板!
在 Superset 中构建仪表板
我们需要经过几个步骤:
-
将 Superset 连接到 Cube
-
定义数据集
-
创建图表并将其添加到仪表板
我们走吧!
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--d7SdokEm--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/dee5d4cc-df2a-47a8-a812-9e54aef57e5d.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--d7SdokEm--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/dee5d4cc-df2a-47a8-a812-9e54aef57e5d.png)
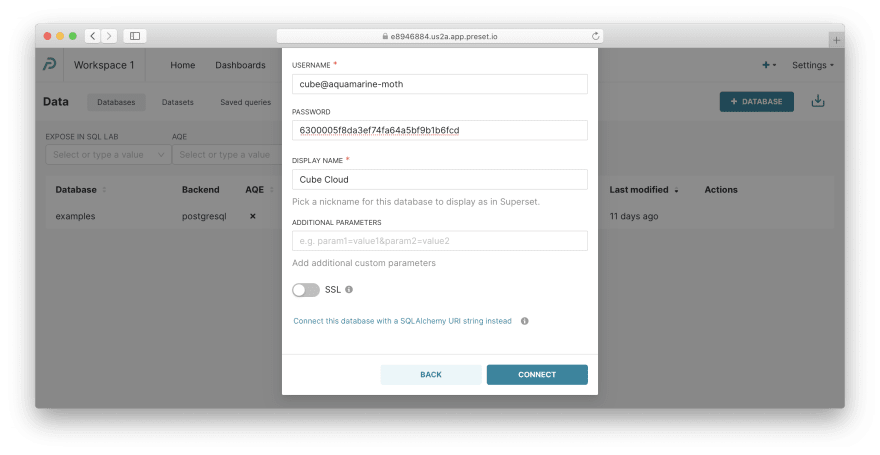
将 Superset 连接到 Cube。 切换回我们之前创建的工作区。然后,通过顶部菜单导航到Data / Databases,单击+ Database,选择MySQL,然后填写 Cube Cloud 实例中的凭据 — 或使用以下凭据:
-
主机:
aquamarine-moth.sql.aws-us-east-2.cubecloudapp.dev -
端口:
3306 -
数据库名称:
db -
用户名:
cube@aquamarine-moth -
密码:
6300005f8da3ef74fa64a5bf9b1b6fcd -
显示名称:
Cube Cloud(很重要)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--6bJHwcO9--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/42812095-82d4-4a65-a918-ab173c45689e.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--6bJHwcO9--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/42812095-82d4-4a65-a918-ab173c45689e.png)
您现在可以按Connect。
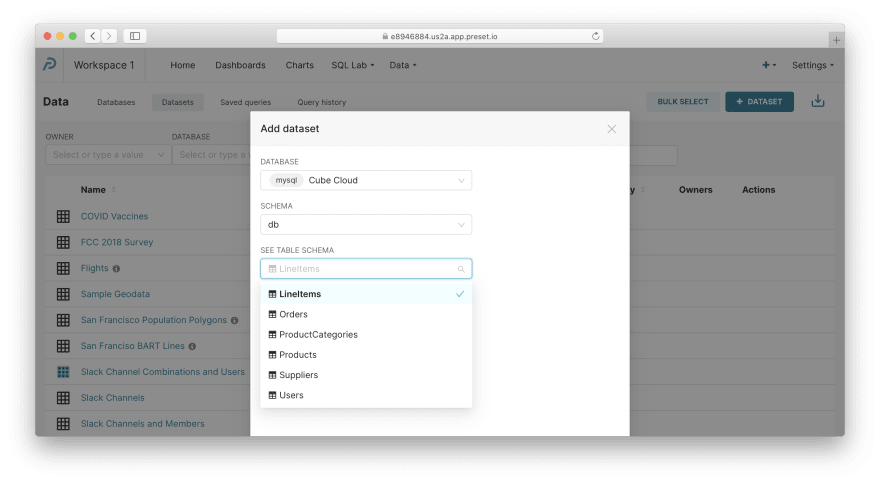
定义数据集。 通过顶部菜单导航到Data / Datasets,单击+ Dataset,然后填写以下凭据:
-
数据库:
Cube Cloud(我们刚刚创建的那个) -
架构:
db -
见表架构:
LineItems
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--PjKGdsnb--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/d8e50fc9-4df7-425b-b57b-f3904de984e0.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--PjKGdsnb--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/d8e50fc9-4df7-425b-b57b-f3904de984e0.png)
您现在可以按Add。然后,请对Users和Orders重复此操作。
创建图表和仪表板。 我们将迈出一大步,一步创建所有内容。
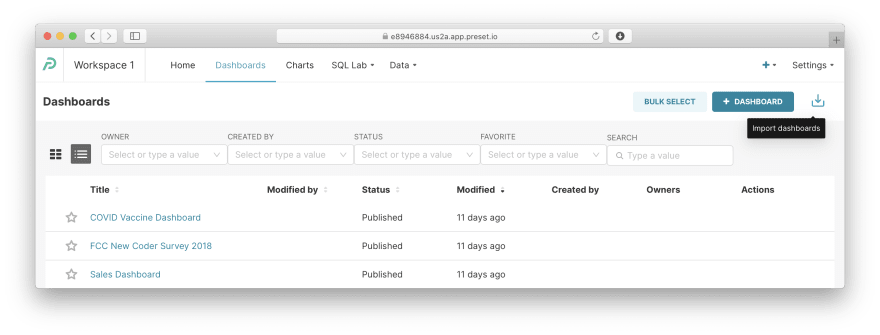
在 Superset 中,您可以将包含所有图表的仪表板导出为 JSON 文件,然后再导入。导航到Dashboards并单击右侧带有图标的链接:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--0oG8Y-ku--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/e2ea0cbd-1cd0-439d-8c4d-a36d9e61b0c7.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--0oG8Y-ku--/c_limit%2Cf_auto%2Cfl_progressive% 2Cq_auto%2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/e2ea0cbd-1cd0-439d-8c4d-a36d9e61b0c7.png)
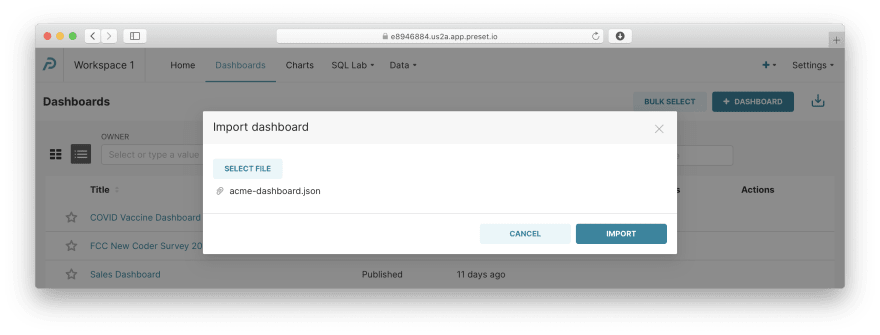
下载这个文件到你的机器,选中它,点击Import:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--phoqVJh3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/5256114e-d4a4-4e4d-96b0-137aee522bcb.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--phoqVJh3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/5256114e-d4a4-4e4d-96b0-137aee522bcb.png)
哇!现在我们有一个完整的 Acme, Inc 仪表板。单击它可以查看:
[](https://res.cloudinary.com/practicaldev/image/fetch/s--jZV2lfdf--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/11d780fa-b9b3-45d2-af61-e1f3ce270731.png)
看起来不错,不是吗?让我们探索引擎盖下的内容以及如何自行构建它。
深入超集
**仪表板剖析。**您可以看到仪表板上的图表按网格对齐。要重新排列它们,请单击右上角的铅笔图标。可以添加标签、页眉、分隔线、Markdown 块等,当然也可以添加图表。
[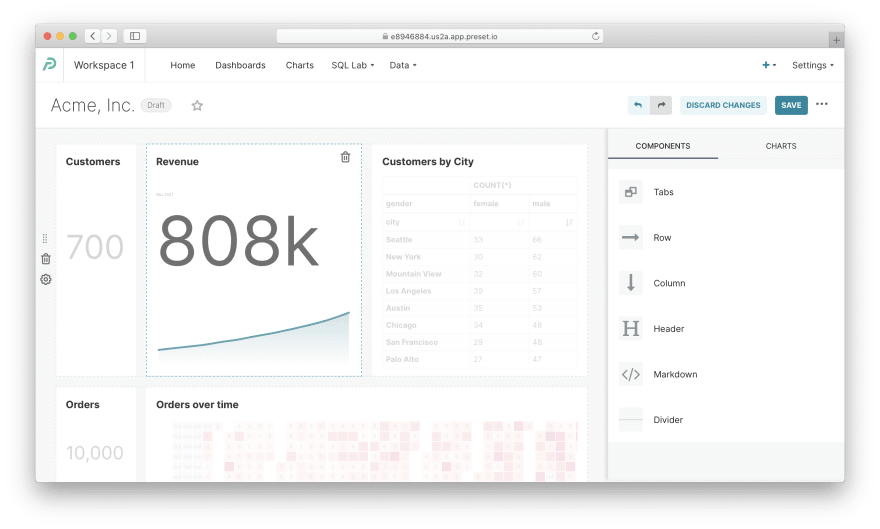 ](https://res.cloudinary.com/practicaldev/image/fetch/s--FE1lcTwz--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/f8905469-8f64-4e3d-85d0-e7ae283673f3.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--FE1lcTwz--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/f8905469-8f64-4e3d-85d0-e7ae283673f3.png)
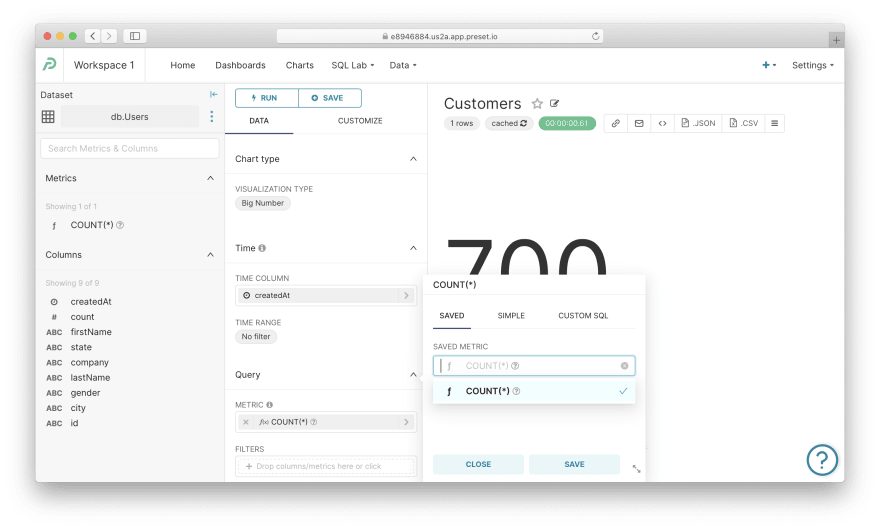
最简单的图表。 通过顶部菜单导航到Charts,然后单击任何具有Big Number可视化类型的图表,例如客户。在我看来,这是您可以在 Superset 中创建的最简单的图表。它包含一个指标,我怀疑图表可以变得比这更简单。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--JL5mIojR--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/afde957b-bdc9-4083-a704-11006c8805f1.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--JL5mIojR--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/afde957b-bdc9-4083-a704-11006c8805f1.png)
让我们剖析一下图表是如何定义的:
-
可视化类型:
Big Number— 您可以在此处选择或更改图表类型 -
时间列:
createdAt— 有趣的是,任何图表都应该定义这个时间列,即使显示的数据没有时间分量 -
公制:
COUNT(*)——这是任何图表配置中最重要的部分;单击此指标后,您将看到您可以选择保存的定义,“简单地”选择列和聚合,或编写“自定义 SQL”表达式
设置好所有配置选项后,按Run获取数据,然后按Save保存图表或将其添加到仪表板上(现在不需要这样做,它已经添加了)。
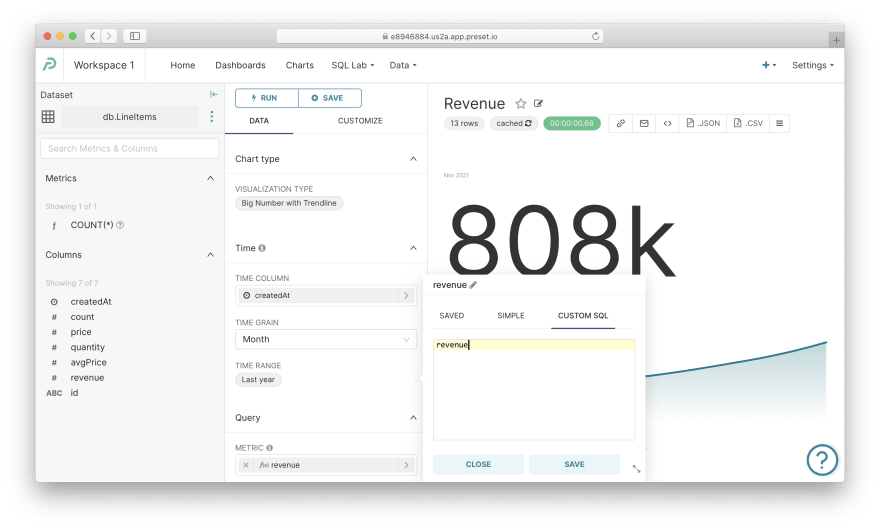
一个不太简单的图表。 通过顶部菜单导航到Charts,然后单击任何具有Big Number with Trendline可视化类型的图表,例如收入。尽管如此,它仍然包含一个指标以及底部的粗略图表。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--yDVre_C5--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/103ea21b-ef9b-4e17-b9a9-580d24a271b1.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--yDVre_C5--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/103ea21b-ef9b-4e17-b9a9-580d24a271b1.png)
让我们剖析一下这个图表是如何定义的(只有新选项):
-
时间粒度:
Month— 定义度量计算的时间粒度 -
时间范围:
Last year— 指定此图表的日期范围 -
公制:
revenue——很有趣;单击此指标以了解它是使用“自定义 SQL”定义的;那是因为 Cube 已经进行了聚合,不需要聚合聚合值,对吧?
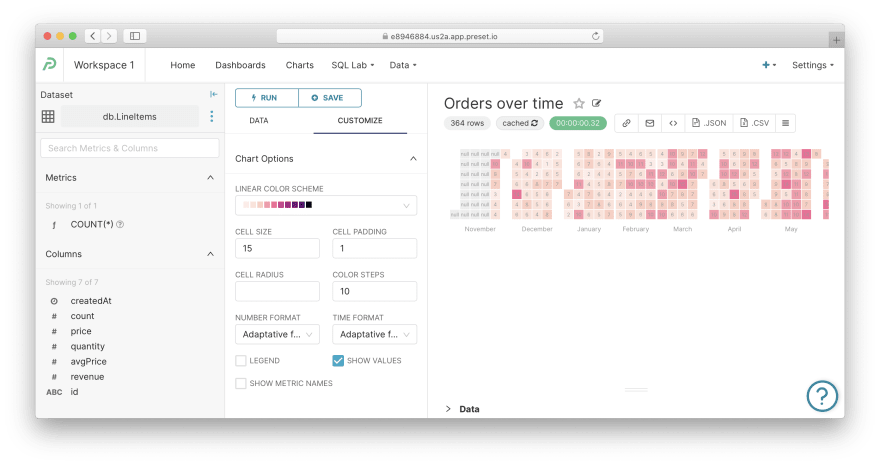
其他图表。 实际上,现在您知道了探索和剖析其他图表所需的一切。请记住,Superset 有很多可以应用于图表的自定义项——请参阅“自定义”选项卡以获取灵感。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--u9iyygU8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/eec079db-5c09-42be-822e-5ab583ce016d.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--u9iyygU8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/eec079db-5c09-42be-822e-5ab583ce016d.png)
查看 SQL。 对于任何图表,您都可以将 SQL 查询显示给由 Superset 生成的 Cube 以获取数据。按右上角的汉堡按钮(带有三条水平线),然后按View query。好的 ol' SQL,很好:
[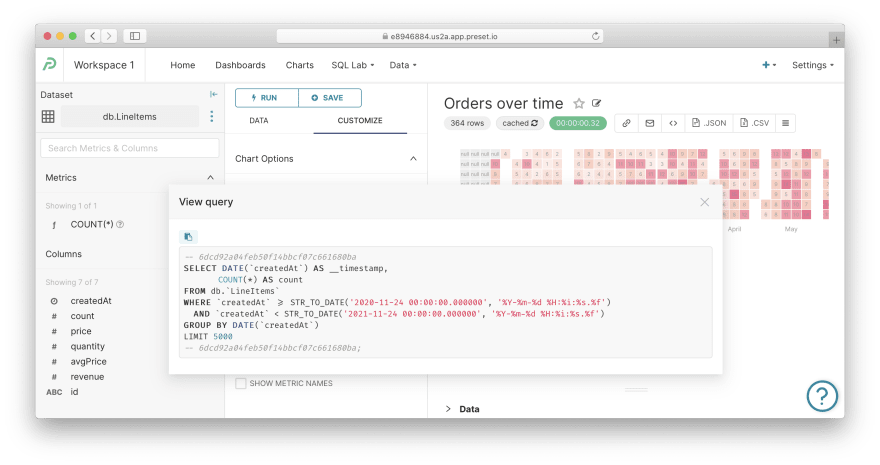 ](https://res.cloudinary.com/practicaldev/image/fetch/s--xjyIUNnk--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/68e680a9-3826-4597-8e21-934f901779c3.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--xjyIUNnk--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto% 2Cw_880/https://cubedev-blog-images.s3.us-east-2.amazonaws.com/68e680a9-3826-4597-8e21-934f901779c3.png)
此外,如果您想使用上述 SQL IDE,请通过顶部菜单导航到SQL Lab / SQL Editor。
让商业智能快速发展⚡
只剩下一件事要探索,但这是一件巨大的事情。
让我们导航回 Acme, Inc. 仪表板。加载需要2-3秒,无限大的旋转器清晰可见。它们并不烦人,但老实说——你不希望这个仪表板立即加载吗?是的,不到一秒钟。
Cube 提供了一个开箱即用的缓存层,它允许预先计算和实现为查询提供服务所需的数据。您需要做的就是定义应该加速哪些查询。它是在数据模式文件中以声明方式完成的。 (还请注意,Superset 有自己的轻量级缓存层,在您需要将 Cube + Superset 推到极限的情况下可能会很方便。)
请返回您的 Cube Cloud 实例,进入开发模式,切换到“架构”选项卡,并使用以下小片段更新您的数据架构文件。
首先,LineItems.js应该如下所示:
cube(`LineItems`, {
sql: `SELECT * FROM public.line_items`,
// Copy me ↓
preAggregations: {
main: {
measures: [ CUBE.count, CUBE.revenue, CUBE.price, CUBE.quantity ],
timeDimension: CUBE.createdAt,
granularity: 'day'
}
},
// Copy me ↑
measures: {
count: {
type: `count`
},
...
进入全屏模式 退出全屏模式
其次,Orders.js应该是这样的:
cube(`Orders`, {
sql: `SELECT * FROM public.orders`,
// Copy me ↓
preAggregations: {
main: {
measures: [ CUBE.count ],
dimensions: [ CUBE.status ],
timeDimension: CUBE.createdAt,
granularity: 'day'
}
},
// Copy me ↑
measures: {
count: {
type: `count`
},
...
进入全屏模式 退出全屏模式
最后,Users.js应该如下所示:
cube(`Users`, {
sql: `SELECT * FROM public.users`,
// Copy me ↓
preAggregations: {
main: {
measures: [ CUBE.count ],
dimensions: [ CUBE.city, CUBE.gender ]
}
},
// Copy me ↑
measures: {
count: {
type: `count`
}
...
进入全屏模式 退出全屏模式
不要忘记单击Save All,然后单击Commit & Push,并检查您的更改是否已部署在“概述”选项卡中。在后台,Cube 将构建必要的缓存。
是时候回到您的仪表板并刷新它了。现在再刷新一次。看?仪表板在一秒钟内加载。 ⚡
当然,您有很多选项可以微调缓存行为,例如,指定缓存重建计划。
结束
感谢您关注本教程。我鼓励您花一些时间阅读文档并探索 Apache Superset 的其他功能。另外,请查看包含大量内容的预设文档,例如,在创建图表上。
另外,感谢您了解有关使用Cube构建指标存储的更多信息。事实上,它是一个非常方便的工具,可作为所有指标](https://cube.dev/blog/introducing-cube-sql/?utm_source=dev-to&utm_medium=post&utm_campaign=building-metrics-dashboard-with-superset)的[单一事实来源。
请不要犹豫,喜欢和收藏这篇文章,写评论,并给 GitHub 上的Cube和Superset打个星。我希望当您决定在其上构建指标存储和商业智能应用程序时,这些工具将成为您工具包的一部分。
祝好运并玩得开心点!

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐
 1
1 1
1- 0



 已为社区贡献27134条内容
已为社区贡献27134条内容

所有评论(0)