使用 Node.js、Express.js、MongoDB、Face-api.js 构建人脸识别 API
简介
大家好,通过本文,我将演示如何使用 Node.js、Express、MongoDB 和 face-api.js 制作面部识别 API。这些是主要的包,但是我们还需要更多的包,我将在本文后面展示。我将编写代码向您展示它是如何工作的,此 API 的主要目标是持久将面部数据存储在数据库中,以便即使服务器关闭,我们也将数据存储在数据库。因此,我们不必再次使用所有图像训练模型。在我们开始之前,请确保您对以下主题有所了解
-
Node.js
-
Express.js
-
MongoDB + Mongoose
-
异步函数
API的用途
如今,面部识别正成为一项重要功能。最近,我不得不在我的大学开展一个项目,该项目需要基于面部识别的身份验证功能。在使用 Node.js 和 Express 处理这个项目时,我找不到足够的资源来将服务器与人脸识别模型集成并将数据存储在数据库中。此外,一些人脸识别 API 正在变得过时。幸运的是,我找到了一个名为 face-api.js 的包,它能够解决这个问题,但它没有足够的文档来实现服务器和数据库。因此我决定写这篇文章。我将在下面添加指向 face-api.js 文档、模型和本文 API 的整个代码的链接。 -
1.Face-api.js 文档链接
2.完整代码库链接
3.型号 zip 下载链接
API 的工作原理
为使本文简短,我将仅展示将面部识别用于通用应用程序所需的主要功能。这些功能是 -
-
获取一张人脸和标签的多张图片。
-
从图像中提取特征并将它们与标签一起存储在数据库中。
-
上传新图像时检查人脸并以最相似的图像响应。
这是其工作原理的简单架构-
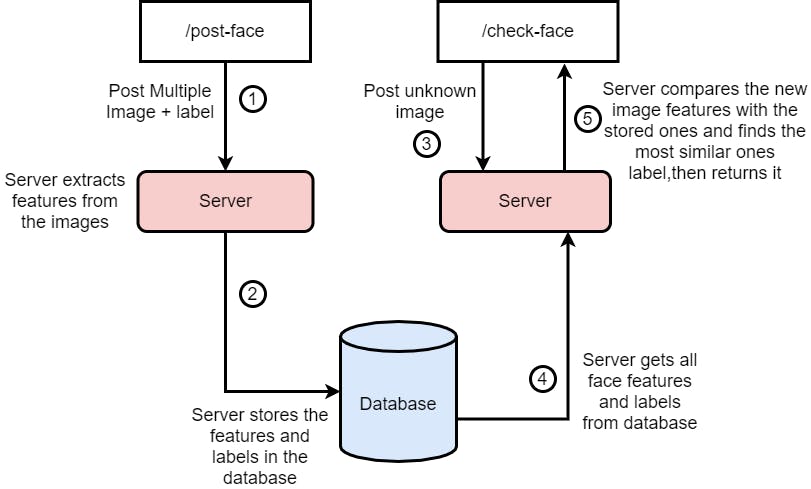
让我们进入代码
启动快递服务器
首先让我们从导入 API 所需的包开始。这是您需要使用 npm 包管理器安装的依赖项列表 -
express
mongoose
express-fileupload
face-api.js
canvas
安装软件包后,我们可以将它们导入到我们的主服务器文件中,在我的例子中是 app.js 文件。然后我们启动我们的 express 服务器,将它连接到数据库并监听所需的端口。我们还应该将 express-fileupload 作为中间件添加到我们的服务器。
const express = require("express");
const faceapi = require("face-api.js");
const mongoose = require("mongoose");
const { Canvas, Image } = require("canvas");
const canvas = require("canvas");
const fileUpload = require("express-fileupload");
faceapi.env.monkeyPatch({ Canvas, Image });
const app = express();
app.use(
fileUpload({useTempFiles: true})
);
// add your mongo key instead of the ***
mongoose.connect(
`***`,
{
useNewUrlParser: true,
useUnifiedTopology: true,
useCreateIndex: true,
}
).then(() => {
app.listen(process.env.PORT || 5000);
console.log("DB connected and server us running.");
}).catch((err) => {
console.log(err);
});
初始化模型
现在我们的服务器可以工作了,我们需要加载我们的模型。由于我们使用的是 face-api.js 包的预训练模型,我们需要下载他们保存的模型并使用模型启动我们的 face-api。为此请确保您可以下载模型,我在上面附上了链接下载它们,然后您可以将它们存储在服务器根目录下的文件夹中。对我来说,我将此文件夹命名为模型,命名由您决定,然后使用以下代码加载模型。我在将文件上传添加为中间件后添加了这个。
async function LoadModels() {
// Load the models
// __dirname gives the root directory of the server
await faceapi.nets.faceRecognitionNet.loadFromDisk(__dirname + "/models");
await faceapi.nets.faceLandmark68Net.loadFromDisk(__dirname + "/models");
await faceapi.nets.ssdMobilenetv1.loadFromDisk(__dirname + "/models");
}
LoadModels();
定义 MongoDB 模式
为了将我们的数据存储在 MongoDB 数据库中,我们需要首先创建一个数据库,并在我们的代码中定义一个 Schema。我不会在这里展示如何创建数据库,但下面的代码是我如何为我们的面部数据定义 Schema。注意 Schema 的数据类型很重要,我们将标签存储为字符串,将描述存储为数组(数组实际上包含对象)。
const faceSchema = new mongoose.Schema({
label: {
type: String,
required: true,
unique: true,
},
descriptions: {
type: Array,
required: true,
},
});
const FaceModel = mongoose.model("Face", faceSchema);
/post-face 路由并存入数据库
现在我们已经加载了模型并定义了模式,我们可以开始接收标记的面部图像并将它们存储在 MongoDB 数据库中。
为此,我们首先需要定义一个函数,该函数接收一组图像和一个标签,然后提取面部描述并将其存储在数据库中。以下函数执行我刚才所说的提取操作 -
async function uploadLabeledImages(images, label) {
try {
const descriptions = [];
// Loop through the images
for (let i = 0; i < images.length; i++) {
const img = await canvas.loadImage(images[i]);
// Read each face and save the face descriptions in the descriptions array
const detections = await faceapi.detectSingleFace(img).withFaceLandmarks().withFaceDescriptor();
descriptions.push(detections.descriptor);
}
// Create a new face document with the given label and save it in DB
const createFace = new FaceModel({
label: label,
descriptions: descriptions,
});
await createFace.save();
return true;
} catch (error) {
console.log(error);
return (error);
}
}
我们将图像和标签作为该函数的输入。然后我们用 try-catch 包装这个函数,这样如果过程中有任何错误,应用程序就不会崩溃。之后,我们定义一个数组来存储所有描述,然后再上传到数据库,然后我们遍历每个图像以使用 canvas.loadImage() 函数读取图像。然后我们将图像数据传递给 face-api 方法并检测人脸特征。然后从特征中提取描述并将其推送到描述数组中。因此,在提取完所有图像特征后,我们根据 Schema 将数据保存在数据库中,如果任务完成则返回 true。
main 方法已经准备好了,现在我们可以开始路由了。以下是路由的代码 -
app.post("/post-face",async (req,res)=>{
const File1 = req.files.File1.tempFilePath
const File2 = req.files.File2.tempFilePath
const File3 = req.files.File3.tempFilePath
const label = req.body.label
let result = await uploadLabeledImages([File1, File2, File3], label);
if(result){
res.json({message:"Face data stored successfully"})
}else{
res.json({message:"Something went wrong, please try again."})
}
})
路线非常简单。我们只是接收文件和标签,然后将其传递给我们之前定义的函数。然后我们根据它是否被保存向用户发送响应。
req.files 仅在您使用我之前提到的 express-fileupload 包时才有效。否则,您将需要使用其他方法上传图像。同样在这个例子中,我只上传了 3 张人脸图像,但更多的图像可以用来提高准确性。*
/face-check 路由和人脸识别
async function getDescriptorsFromDB(image) {
// Get all the face data from mongodb and loop through each of them to read the data
let faces = await FaceModel.find();
for (i = 0; i < faces.length; i++) {
// Change the face data descriptors from Objects to Float32Array type
for (j = 0; j < faces[i].descriptions.length; j++) {
faces[i].descriptions[j] = new Float32Array(Object.values(faces[i].descriptions[j]));
}
// Turn the DB face docs to
faces[i] = new faceapi.LabeledFaceDescriptors(faces[i].label, faces[i].descriptions);
}
// Load face matcher to find the matching face
const faceMatcher = new faceapi.FaceMatcher(faces, 0.6);
// Read the image using canvas or other method
const img = await canvas.loadImage(image);
let temp = faceapi.createCanvasFromMedia(img);
// Process the image for the model
const displaySize = { width: img.width, height: img.height };
faceapi.matchDimensions(temp, displaySize);
// Find matching faces
const detections = await faceapi.detectAllFaces(img).withFaceLandmarks().withFaceDescriptors();
const resizedDetections = faceapi.resizeResults(detections, displaySize);
const results = resizedDetections.map((d) => faceMatcher.findBestMatch(d.descriptor));
return results;
}
这部分非常关键,我们需要非常小心。首先,我们从数据库中获取所有的人脸数据。但是我们得到的数据只是数组中的对象。为了让我们的模型读取每个图像的描述,它需要是 LabeledFaceDescriptors 对象。但是,要做到这一点,我们需要将描述作为 Float32Array 传递。因此,对于每个人脸数据,我们循环遍历每个描述是对象。我们将这些 Object 类型转换为 Array,然后转换为 Float32Array。然后我们启动人脸匹配器,读取已经传入函数的图像进行识别。我们根据人脸 API 的文档运行处理和检测函数并返回结果。
现在我们可以定义检查面的路线。以下是路线——
app.post("/check-face", async (req, res) => {
const File1 = req.files.File1.tempFilePath;
let result = await getDescriptorsFromDB(File1);
res.json({ result });
});
在路由中我们只是传入图片,等待getDescriptorsFromDB函数进行人脸识别并返回结果。
测试
我们的 API 已准备就绪,现在让我们使用 Postman 对其进行测试。 Postman 是测试 API 的绝佳工具,免费。你可以在这里下载。
首先,我上传了 3 张带有这样标签的同一个人的图片 -
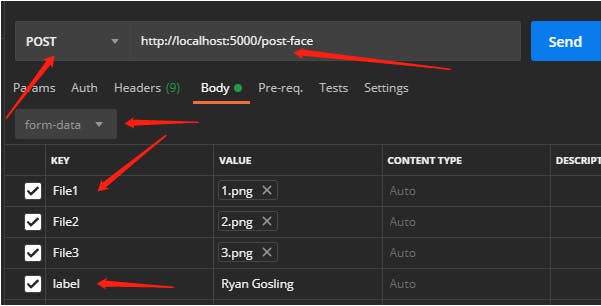
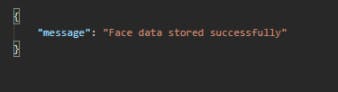
请注意指出的细节。如果这些与您的代码不匹配,服务器将响应错误。如果一切顺利,你应该会得到这样的回应——
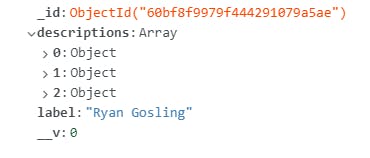
在数据库中,您应该为每个上传的面孔提供如下文件-
现在我可以上传一张测试图片,看看 API 是否可以识别出这张脸 -
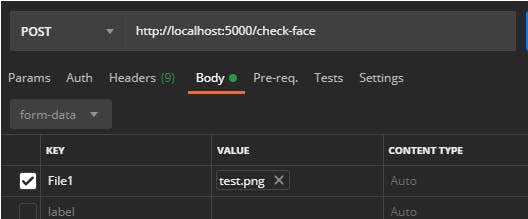
我得到的结果是这样的——
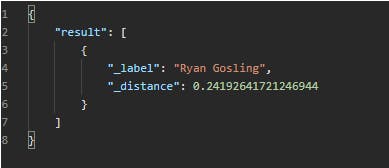
如果文章太长,我很抱歉,但这是我的第一篇文章。我希望你喜欢这些内容。如果这对您有帮助,请在我的github上加星,并与其他人分享此博客。如果您在使用此代码时遇到任何问题,可以在 Twitter 上通过@Zulkarn30860075与我联系。
非常感谢你!!!!

MongoDB社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献32862条内容
已为社区贡献32862条内容

所有评论(0)