如何使用 Node.js 从上传的 PDF 中提取文本内容并存储在 MongoDB 数据库中(5 个简单步骤)
所以我最近开始研究一个机器学习项目,部分功能要求我能够上传文件,提取 PDF 内容,并将书籍和文本内容存储在数据库中(在本例中为 MongoDB)。尽管我看到了有关如何解析 PDF 文件的文章,但它们的效率不足以帮助我实现我的目标。这就是为什么我决定用简单但详细的步骤写下我是如何进行这个项目的。谁激动???

虽然这种文本提取方法不仅限于 PDF,它也适用于其他文档类型,例如 Microsoft word 等。但是这个项目使用了 PDF,所以这篇文章也会在上面。
数以百万计的文本被埋在 PDF 文档中,无论是报告、文档等形式,从 PDF 中提取文本对于进一步的数据处理是必要的;事实上,有很多方法可以使用文本提取。如您所知,我正在使用它来构建数据解决方案。
嗯,看起来很简单,对吧......虽然不完全如此。这是因为 PDF 的结构主要用于阅读和打印目的。因此,PDF 以非常复杂的格式存储数据。它利用嵌入式字体、自定义间距。我们在 PDF 中看到的简单文本实际上是嵌入的字体,这使得从 PDF 中提取文本更加困难。所以让我们直接进入

在我们开始学习和编写代码之前,我希望我们了解环境以及所需的库。
对于这个项目,我们将在 Node.js 环境中工作,其中包含 pdf-parse、dotenv、ejs、express、mongoose、Multer 等库。
节点.js
Node.js 是一个用于后端开发的 JavaScript 库。 Node.js 是非阻塞 I/O,因此在处理文件时非常高效,无论文件有多大。节点。 Node.js 由于其单线程特性,主要用于非阻塞、事件驱动的服务器。它用于传统网站和后端 API 服务,但在设计时考虑了实时、基于推送的架构。
多腾夫
dotenv 是一个零依赖模块,它将环境变量从 .env 文件加载到 process.env 中。 Dotenv 允许您从源代码中分离秘密。这很有用,尤其是在协作环境(工作、开源等)中,您可能不想共享您的凭据,例如数据库登录凭据、OAuth 凭据等。
表达
Express 是一个最小且灵活的 Node.js 应用程序框架,它为 Web 和移动应用程序提供了一组强大的功能。 Express 的主要用途是为 Web 和移动应用程序提供服务器端逻辑,因此,它被广泛使用。
EJS
嵌入式 Javascript 模板,或俗称的 EJS,是 Node.js 使用的模板引擎。它是一种用于生成可包含动态数据的网页的工具。它帮助开发人员用最少的代码创建 HTML 模板。
猫鼬
Mongoose 是一个用于 MongoDB 和 Node.js 的对象数据建模 (ODM) 库。 js。它管理数据之间的关系,提供模式验证,并用于在代码中的对象和 MongoDB 中这些对象的表示之间进行转换。
鲻
Multer 是一个节点。 js中间件用于处理multipart/form-data,主要用于上传文件。中间件是可以访问请求对象 (req)、响应对象 (res) 的函数,也是应用程序请求-响应周期中的下一个中间件函数。中间件用于修改请求和响应对象,用于解析请求正文、添加响应标头等任务。
pdf解析
pdf-parse 是一个 node.js 依赖项,用于从 pdf 文档中提取数据。
编码时间!

我们要做的第一步是使用 npm 命令初始化我们的 node.js 项目。打开命令提示符并导航到要从中执行此项目的目录。写
npm init -y
这是您输入的“npm init -y”命令的视觉输出。
这会初始化一个我们将在其上编写代码的 npm 项目。要继续,请打开您的Visual Studio 代码编辑器或您用于编码的任何其他编辑器。当您的编辑器打开时,您会看到一个名为 package.json 的文件。该文件包含用于建立项目的所有必要信息和命令。
我们的下一步是安装上面列出的软件包。打开你的终端。如果您使用的是 Visual Studio 代码编辑器,则打开终端的快捷方式是“ctrl + `”。终端打开后,我们可以通过在终端中键入以下命令来安装依赖项。
npm i ejs express mongoose multer multer-gridfs-storage pdf-parse
您会看到一个名为 node_modules 的新文件夹,并创建了一个额外的文件 (package-lock.json)。您的 package.json 文件现在将如下更新:
让我们创建一个新文件,将其命名为 index.js 文件。这是我们将编写启动和保持服务器运行所需的代码的文件。
const express = require('express')
const mongoose = require('mongoose')
const fs = require('fs')
const path = require('path')
const dotenv = require('dotenv')
dotenv.config()
在上面的代码中,我们基本上调用了这个项目所需的所有依赖项。首先,我们需要 express,这将用于创建我们的服务器;我们还需要猫鼬。如前所述,猫鼬是 Node.js 和 MongoDB ODM;我们将使用它连接到我们的数据库。这很重要,因为我们将从 pdf 中提取的内容存储在数据库中。接下来,我们需要 fs,它是文件系统的缩写形式。这个库让我们可以访问我们的本地计算机;路径文件允许我们浏览我们的本地计算机。然后我们需要 dotenv 以便我们能够使用我们的凭据,并且除了开发人员之外,其他人都无法看到它。
const app = express()
const dotenv = require('dotenv')
dotenv.config()
mongoose.connect(`${process.env.START_MONGODB}${process.env.MONGODB_USERNAME}:${process.env.MONGODB_PASSWORD}${process.env.END_MONGODB}`, { useNewUrlParser: true, useUnifiedTopology: true })
.then(() => {
console.log('Nanana')
})
.catch((e) => {
console.log(e)
})
app.use(express.urlencoded({ extended: true }))
app.set('views', path.join(__dirname, 'views'))
app.set('view engine', 'ejs')
app.use(express.static(`${__dirname}/public`))
为了解释上面的内容,我们做的第一件事是创建一个我们的 express 依赖的实例,并将它存储在一个名为“app”的变量中。我们连接到我们的数据库;在这里,我们通过 mongo atlas 在线连接。要了解有关如何执行此操作的更多信息,请单击此处的。
然后我们包含了不同的中间件,定义了我们的views文件夹的路径,并告诉程序我们将使用ejs作为我们的模板引擎来编写我们的前端代码(编码不多,但你明白了) .我们还注意到,所有其他静态文件(例如 CSS 文件、图像、JavaScript 文件等)都将包含在公共文件夹中。
const port = process.env.PORT || 9000
app.listen(port, () => {
console.log(`Application is listening on port ${port}`)
})
在这里,我们定义了我们的端口。如您所见,此处定义了端口:
const port = process.env.PORT || 9000
这意味着告诉我们的节点服务器转到 .env 文件并查找“PORT”并在“PORT”定义的端口号上运行服务器;如果在 .env 文件中没有找到“PORT” , 然后使用数字 9000 作为端口号。“app.listen”允许我们运行我们的服务器,让服务器监听定义的任何端口。
要运行服务器,请打开命令提示符并键入命令,然后按 Enter。
node index.js
服务器启动,你可以去你的端口;目前你会看到一个错误说'cannot GET /',这是因为我们没有定义我们的路线;我们只是在测试我们的服务器以确保一切正常。上面的'index.js'是因为我们的服务器端代码可以在index.js文件中找到。因此,假设您使用不同的名称保存文件,例如server.js,tobe.js;为了能够运行服务器,您需要输入:
node whateveryourfilenameis.js
我们需要知道的一点是,每当我们在应用程序中编写代码时,为了查看我们编写的内容,我们需要通过按“Ctrl + c”并运行 node index.js 来重新启动服务器。这不省时,而且实际上降低了开发人员的生产力水平。为了推翻这一点,开发者依赖(nodemon)允许我们解决这个问题。基本上,在使用 nodemon 时,我们只需要启动一次服务器,每次我们对代码进行更改时,nodemon 都会为我们刷新我们的服务器,从而节省了我们的时间。要将 nodemon 添加到此项目,您所要做的就是使用以下命令安装它:
npm i -D nodemon
Nodemon 是一个开发依赖项,这就是在我们的命令中添加“-D”的原因。完成安装后,您会看到它已添加到您的 package.json 文件中,并且已添加到 dev 依赖项部分中。转到您的 package.json 文件并将 nodemon 命令添加到脚本部分,如下所示:
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "nodemon index"
}
这样您的 package.json 文件现在看起来像这样。
要运行服务器,您只需键入:
npm run dev
这将使用 nodemon 启动您的服务器,并注意您对代码所做的每一次更改,甚至为您的代码添加额外的空间,您的服务器都会自动重新启动。好对...让我们动起来
请记住,当我们第一次使用“node index.js”启动服务器时,我们遇到了一个错误说“无法获取 /”,现在我们要创建我们的路由。
但在我们这样做之前,让我们创建我们的模型。在您的项目文件夹中,创建一个名为 model 的文件夹,并在该文件夹中创建一个文件并将其命名为您想要的任何名称;就我而言,我称之为“bookModel.js”。我们要做的第一件事是要求我们将使用的依赖项,在我的例子中,这将是 mongoose。此外,我们将添加一个模式对象,并且我们将从 mongoose 包中获取此模式包。
const mongoose = require('mongoose')
const schema = mongoose.Schema
此后,我们将定义模型的结构(模式),为了这个项目,我们需要三个信息:标题、文本内容和我们从文档中提取信息的日期(pdf )。为此,我们将创建一个模式对象的实例,并将信息存储在一个名为 book schema 的变量中
const bookSchema = new schema({
title: {
type: String
},
textContent: {
type: String
},
createdAt: {
type: Date,
default: Date.now
}
})
现在我们已经定义了我们的模式,然后我们使用以下代码创建我们的模型,然后我们导出我们的 bookModel.js 文件,以便我们可以在另一个文件中使用它。
const Book = mongoose.model('book', bookSchema)
module.exports = Book
所以我们的书本模型看起来像这样:
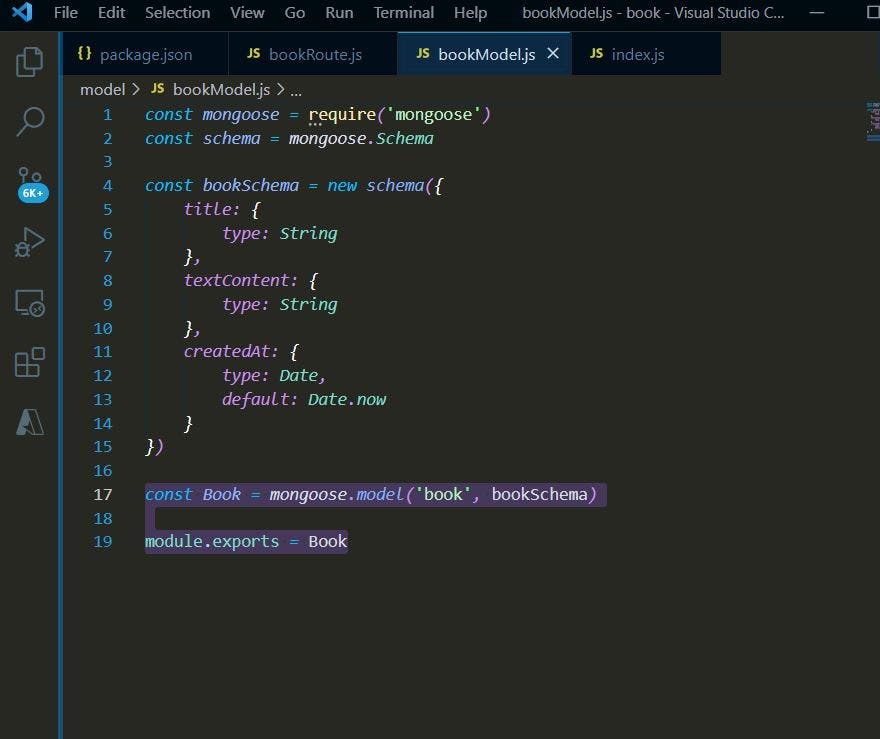
现在让我们创建我们的路线...
在您的项目文件夹中,创建另一个文件夹并将其命名为 routes... 在您的 routes 文件夹中,创建一个文件并将其命名为您想要的任何名称,但在我们的示例中,我将其命名为“bookRoute.js”。
const express = require('express')
const Book = require('../model/bookModel')
const router = express.Router()
router.get('/', (req, res) => {
res.status(200).render('book.ejs')
})
module.exports = router
这里我们需要我们的 express 包,但在这种情况下,我们将使用 express 包中的路由器对象,这基本上可以让我们创建路由。我们还需要 bookModel.js 文件中的 Book 模型。我们需要这个,因为这是我们保存书籍内容的方式。我们创建了我们的第一个路由'/',它基本上是我们项目的索引页面。除了路由,我们调用一个函数(通常称为或称为回调函数),它包含两个参数; req(请求的缩写),res(响应的缩写)。 req 对象用于从我们的客户端请求内容。例如,当我们填写表单(注册或登录表单)并单击提交或注册或任何按钮时,我们可以通过请求对象检索表单的内容或我们正在提交的任何内容在前端。另一方面,响应用于将内容从服务器发送回客户端。对于上面的代码,我们看到我们正在发送一个状态码 200(这意味着好的),我们也在渲染一个 ejs 文件;这样每次调用路由'/'时,服务器都会返回要在客户端显示的ejs文件。让我们创建这个文件。然后我们导出我们的路由器文件,就像我们为我们的模型文件所做的那样。这样,另一个文件也可以访问特定文件。
最后,为了能够在我们的前端看到一些东西,让我们创建一个视图。尽管如此,在同一个项目文件夹中,创建一个名为 'views' 的文件夹,并在 'views' 文件夹中创建一个文件 book.ejs,这个名称特别适合我们在路由文件中呈现的名称。由于我们不专注于客户端,我只是将代码粘贴给你们而不做解释。
<!doctype html>
<html>
<head>
<title>Story Books</title>
<link rel = "stylesheet"
href = "https://fonts.googleapis.com/icon?family=Material+Icons">
<link rel = "stylesheet"
href = "https://cdnjs.cloudflare.com/ajax/libs/materialize/0.97.3/css/materialize.min.css">
<script type = "text/javascript"
src = "https://code.jquery.com/jquery-2.1.1.min.js"></script>
<script src = "https://cdnjs.cloudflare.com/ajax/libs/materialize/0.97.3/js/materialize.min.js">
</script>
</head>
<body class = "container">
<div class = "row">
<form class = "col s12" action="/bookie" method="POST" enctype="multipart/form-data">
<div class = "row">
<div class = "file-field input-field">
<div class = "btn">
<span>Browse</span>
<input type = "file" name="file" />
</div>
<div class = "file-path-wrapper">
<input class = "file-path validate" type = "text"
placeholder = "Upload file" />
</div>
</div>
</div>
<div class="row">
<button class="btn waves-effect waves-light" style="font-size: 25px;" type="submit">Upload File
</button>
</div>
</form>
</div>
</body>
</html>
})
module.exports = router
接下来是包含在 index.js 文件中创建的路由。为此,请像这样导入并调用路由文件
const bookRoutes = require('./routes/bookRoute')
.
.
.
.
app.use(bookRoutes)
上面两行之间的点表示缺少的代码行,在这种情况下,缺少的代码行是您的中间件。正如你所知,我在声明我的端口之前放置了“app.use(bookRoutes)”行。
现在我们可以继续测试我们的应用程序了。打开控制台并在项目目录中输入以下行:
npm run dev
这应该运行您的应用程序。您可以转到运行应用程序的地址,您会看到您的应用程序如下所示:
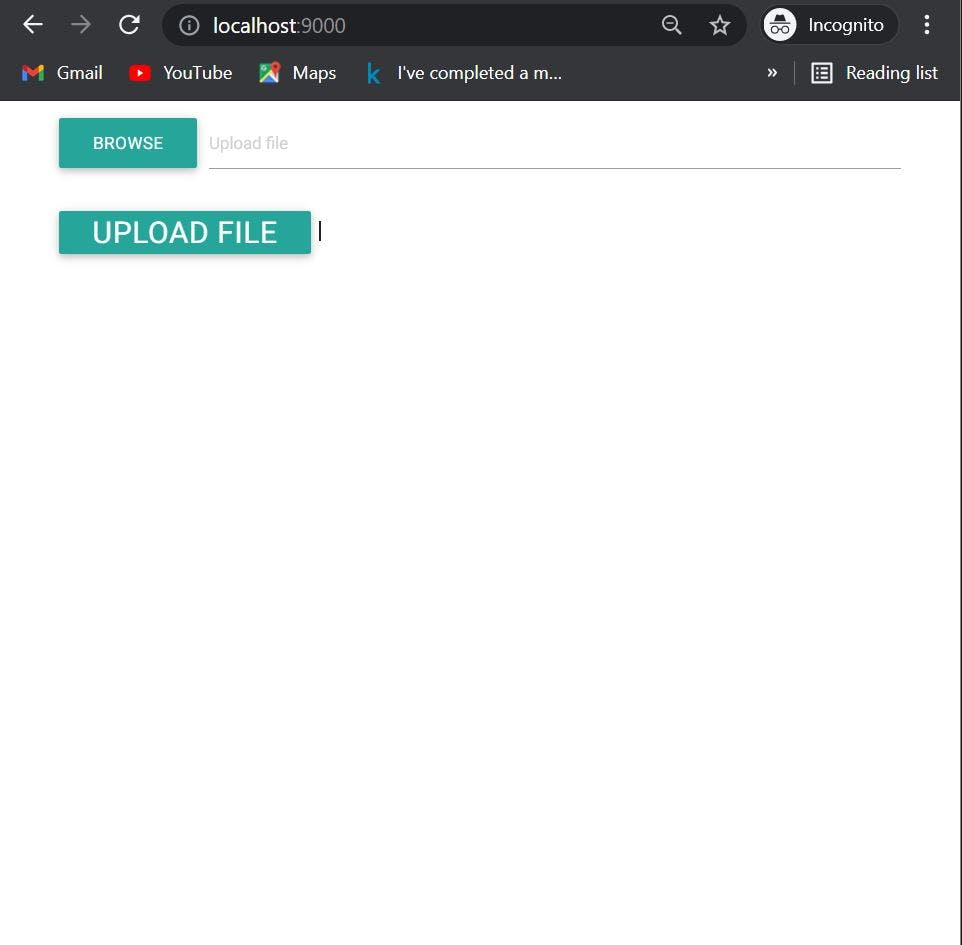
Yayyy...我们做得很好...您可以在这一点上休息一下..哈哈
现在,让我们使用上传来处理文件。在使用 Multer 处理上传之前,重要的是要了解文件永远不会存储在数据库中。尽管如此,我们还是会使用数据库来存储有关我们正在上传的文件的一些信息。这些文件总是存储在服务器的某个地方。在本教程中,我们会将上传的文件存储在公用文件夹中。我们还将学习如何在前端查看这些文件。
要开始配置 Multer,我们需要先配置磁盘存储和上传文件的命名。
Multer 有一个称为 diskstorage 的内置方法。此方法有几个选项。第一个选项是目的地,这个目的地选项是一个回调函数,它接受三个参数: req:哪个是传入的请求对象。文件:传入的文件对象。 cb:另一个回调函数。
我们调用接收两个参数的 cb 函数。第一个是“错误”,我们将在其中作为 null 传递。第二个参数是我们保存文件的目标文件夹。
diskstorage 方法采用的第二个选项是文件名。它与目标选项几乎相同,只是在这种情况下,内部回调函数将文件名作为第二个参数。
const multerStorage = multer.diskStorage({
destination: (req, file, cb) => {
cb(null, 'public/')
},
filename: (req, file, cb) => {
cb(null, file.originalname)
}
})
接下来,我们将制作一个过滤器,用于过滤掉不同类型的文件。如前所述,该项目仅关注 PDF,因此我们将制作一个过滤器以仅允许上传 PDF 文件。
const multerFilter = (req, file, cb) => {
if(file.mimetype.split("/")[1] === "pdf"){
cb(null, true)
}
else {
cb(new Error("Not a PDF file"), false)
}
}
我们配置的最后一步是调用 Multer 函数并将上述两个函数作为选项手动传递。
const upload = multer({
storage: multerStorage,
fileFilter: multerFilter
)}
现在,我们已经成功配置了 Multer。如果我们尝试上传 PDF 文件,您应该会在 public 目录下的 files 文件夹中看到上传的文件。如果您上传任何其他非 PDF 文件,则会显示错误。
我们越来越接近我们的应用程序的结束。在这里,我们将编写我们的代码,以便我们能够在前端和数据库中看到我们的书。
现在我们将提取 pdf 的内容并将其存储在我们的数据库中。为此,我们将使用 pdfparse 来提取内容。 pdfparse 的伟大之处在于它允许您从文档中获取大量信息。例如,除了提取文本内容之外,您还可以提取书中的页数。您还可以获得书名等。
对于这个项目,我们将提取 PDF 的标题和内容,并将信息存储在数据库中。这是执行此操作的代码。
router.post('/bookie', upload.single('file'), async (req, res) => {
// console.log(req.file)
const pdffile = fs.readFileSync(path.resolve(__dirname, `../public/${req.file.originalname}`))
pdfparse(pdffile)
.then((data) => {
console.log(data.numpages)
const book = new Book({
title: req.file.filename,
textContent: data.text
})
book.save()
.then((cho) => {
console.log(cho)
res.status(201).json({
message: "Book uploaded successfully",
uploadedBook: {
name: cho.title,
text: cho.textContent,
_id: cho._id
}
})
})
.catch((e) => {
// console.log(e)
res.status(500).json({
error: e
})
})
})
})
在这里,我们首先声明与我们为前端编写的表单相同的路由。在回调函数之前,我们通过了 Multer 配置并只允许一次上传。
然后我们读取保存在公共目录中的文件并将其存储在我们称为 pdffile 的变量中。然后我们在 pdffile 上调用了 pdfparse 方法。
如您所见,我们能够提取 PDF 的某些属性,例如页数、内容以及 PDF 的标题。
然后,我们创建了一个数据库模型实例并保存了该实例所需的内容。最后,我们将模型保存到我们的数据库(Mongo)中。
上面的代码只是一个以 req、file 和回调函数作为参数的函数。然后我们检查这些文件是否是 PDF,如果是,我们将在回调函数中传递 true。如果它不是 PDF,我们将在回调函数中传递 false 和错误。
这里出来了
现在,让我们测试我们的应用程序。在这里,我上传了一本书,这是输出。
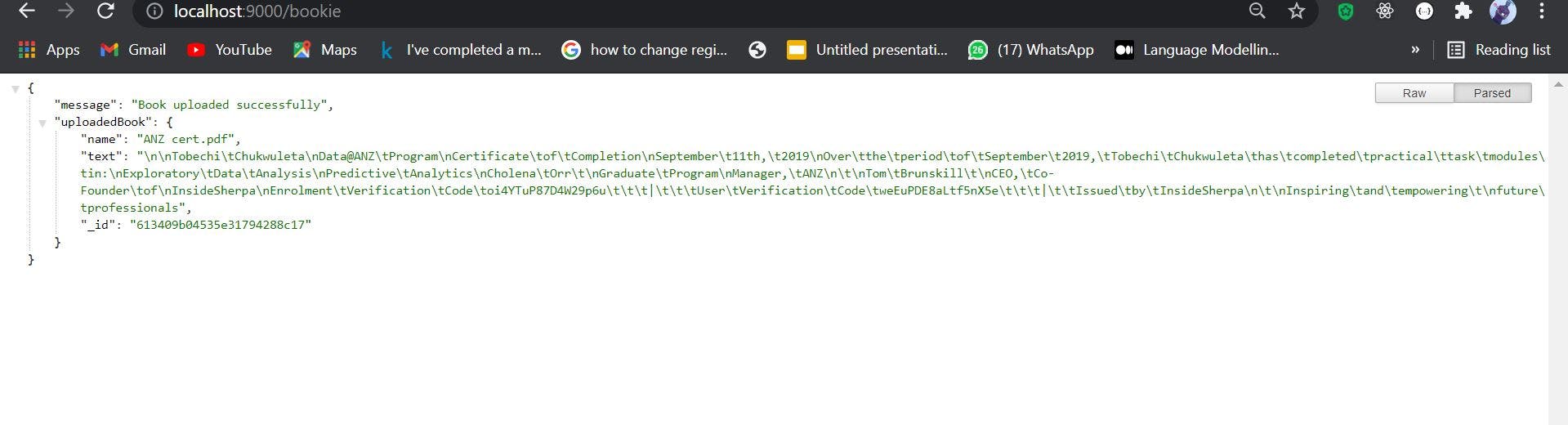
我可以继续使用数据的输出并执行我想要的任何分析,因为我现在将 PDF 的内容提取为纯文本。
这是我们整个 bookRoute.js 文件
const express = require('express')
const Book = require('../model/bookModel')
const pdfparse = require('pdf-parse')
const fs = require('fs')
const multer = require('multer')
const path = require('path')
const router = express.Router()
// Config for multer
// const upload = multer({ dest: "public/files "})
const multerStorage = multer.diskStorage({
destination: (req, file, cb) => {
cb(null, 'public/')
},
filename: (req, file, cb) => {
cb(null, file.originalname)
}
})
const multerFilter = (req, file, cb) => {
if(file.mimetype.split('/')[1] === 'pdf' || file.mimetype.split('/')[1] === 'docx'){
cb(null, true)
}
else {
cb(new Error('Not a document File'), false)
}
}
const upload = multer({
storage: multerStorage,
fileFilter: multerFilter
})
router.get('/', (req, res) => {
res.status(200).render('book.ejs')
})
router.post('/bookie', upload.single('file'), async (req, res) => {
// console.log(req.file)
const pdffile = fs.readFileSync(path.resolve(__dirname, `../public/${req.file.originalname}`))
pdfparse(pdffile)
.then((data) => {
console.log(data.numpages)
const book = new Book({
title: req.file.filename,
textContent: data.text
})
book.save()
.then((cho) => {
console.log(cho)
res.status(201).json({
message: "Book uploaded successfully",
uploadedBook: {
name: cho.title,
text: cho.textContent,
_id: cho._id
}
})
})
.catch((e) => {
// console.log(e)
res.status(500).json({
error: e
})
})
})
})
module.exports = router
还有一件事......我知道标题误导了 5 个简单的步骤(笑)......我知道人们急于完成任务;这就是这个目标。此外,我想确保我的读者不仅仅是在完成这些步骤之后,还要确保他们理解正在完成的所有事情。
非常感谢你们,伙计们......我很快就会放弃更多内容,所以请保持关注,伙计们。
同时,您可以通过Twitter或LinkedIn与我联系


MongoDB社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献32862条内容
已为社区贡献32862条内容

所有评论(0)