
Linux中关于API函数与系统调用
大家对 API并不陌生,对系统调用也不陌生,但是,对两者之间的区别于联系可能并不是十分清楚。
相信大家对 API并不陌生,对系统调用也不陌生,但是,对两者之间的区别于联系可能并不是十分清楚。
API
API(Application Programming Interface,应用程序编程接口),指的是我们用户程序编程调用的如read(),write(),malloc(),free()之类的调用的是glibc库提供的库函数。API直接提供给用户编程使用,运行在用户态。这里要另外提一下,POSIX针对API提出标准,即针对API的函数名,返回值,参数类型进行规范约束,但是并不管API具体如何实现。
系统调用
操作系统为用户态进程与硬件设备进行交互提供了一组接口——系统调用。
通过软中断或系统调用指令向内核发出一个明确的请求,内核将调用内核相关函数来实现(如sys_read(),sys_write())。用户程序不能直接调用这些Sys_read,sys_write等函数。这些函数运行在内核态。
系统调用的好处
- 把用户从底层的硬件编程中解放出来
- 极大的提高了系统的安全性
- 使用户程序具有可移植性
两者间的区别和联系
API 和系统调用是不同的
- API只是一个函数定义
- 系统调用通过软中断向内核发出一个明确的请求
Libc库定义的一些API引用了封装例程(wrapper routine,目的就是发布系统调用)
- 一般每个系统调用对应一个封装例程
- 库再用这些封装例程定义出给用户的API
通常API函数库中的函数(如read())会调用封装例程,封装例程负责发起系统调用(通过发软中断或系统调用指令),这些都运行在用户态。
内核开始接收系统调用后,cpu从用户态切换到内核态(cpu处于什么状态,程序就处于什么状态,所以很多地方也说程序从用户态切换到内核态,实际是cpu运行级别的切换,在Linux中cpu 运行在3级表示用户态,运行在0级表示内核态)。
内核调用相关的内核函数来处理再逐步返回给封装例程,cpu进行一次内核态到用户态的切换,API函数从封装例程拿到结果,再处理完后返回给用户。
但是API函数不一定都需要进行系统调用。
- API可能直接提供用户态的服务(如,一些数学函数)
- 一个单独的API可能调用几个系统调用
- 不同的API可能调用了同一个系统调用
返回值
- 大部分封装例程返回一个整数,其值的含义依赖于相应的系统调用
- -1在多数情况下表示内核不能满足进程的请求
- Libc中定义的errno变量包含特定的出错码
我们编写linux用户程序的时候,是不能直接调用内核里面的函数的,内核里面的函数位于进程虚拟地址空间里面的内核空间,用户空间函数及函数库都处于进程虚拟地址空间里面的用户空间。
用户空间调用内核空间的函数只有一个通道——系统调用指令,所以通常要调用glibc等库的接口函数。
glibc也是用户空间的,但glibc自己实现了调用特殊的宏汇编系统调用指令进行cpu运行状态的切换,把进程从用户空间切换到内核空间。
使用库函数API和使用系统调用号调用同一个系统调用
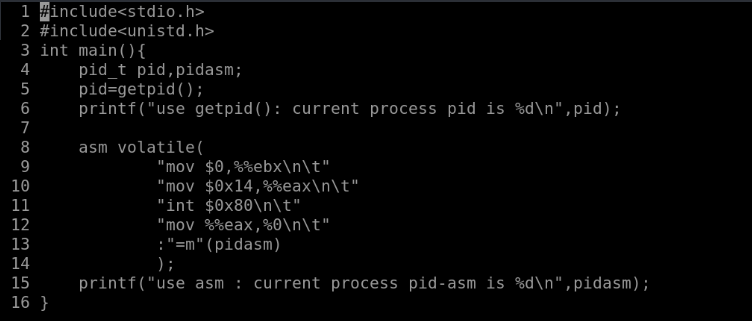
代码如下图所示
运行结果如图所示

现在来分析代码,第4行定义的两个变量,pid 用来保存使用API 函数getpid()返回的进程号,pid-asm保存嵌入式汇编代码使用系统调用号调用系统调用得到的进程号。
第5、6行通过系统调用getpid()输出pid。
第8-14行是一段嵌入式汇编代码。
“mov $0x14,%%eax\n\t”
将20(getpid系统调用号为20)传进eax寄存器
“int $0x80\n\t”
发出系统调用指令。
“mov %%eax,%0\n\t”
将eax寄存器的值(其中保存的是系统调用返回值)存入变量pid-asm。
系统调用号
一个系统调用号,对应一个函数入口地址,glibc和内核里面的这个系统调用号是一致的,所以glibc调用汇编之类把系统调用号传给内核的时候,内核找到这个具体的系统调用服务例程对应的函数入口地址,如sys_read。
参数传递
系统调用也需要输入输出参数,例如
- 实际的值
- 用户态进程地址空间的变量的地址
- 甚至是包含指向用户态函数的指针的数据结构的地址
system_call是linux中所有系统调用的入口点,每个系统调用至少有一个参数,即由eax传递的系统调用号
- 一个应用程序调用fork()封装例程,那么在执行int $0x80之前就把eax寄存器的值置为2(即__NR_fork)。
- 这个寄存器的设置是libc库中的封装例程进行的,因此用户一般不关心系统调用号
- 进入sys_call之后,立即将eax的值压入内核堆栈
寄存器传递参数具有如下限制:
- 每个参数的长度不能超过寄存器的长度,即32位
- 除系统调用号(eax)之外,参数的个数不能超过6个(ebx,ecx,edx,esi,edi,ebp)
对于第一点,POSIX标准规定,如果寄存器里面装不下那个长度的参数,那么必须改用参数的地址来传递。
对于第二点,有的系统调用参数大于6个,这种情况下,必须用一个单独的寄存器执行进程地址空间的这些参数所在的一个内存区。
普通c函数的参数传递是通过把参数值写入程序栈(用户态栈或者内核态栈)实现的。
因为系统调用是一种跨用户态和内核态的特殊函数,所以这两个栈都不能用。
在发出系统调用之前,系统调用的参数写入了cpu的寄存器(如glibc去写好这些寄存器),然后发出系统调用之后,而在内核调用服务例程(如fork()服务例程)之前,内核再把存放在cpu中的参数拷贝的内核态的堆栈中(因为fork()只是普通的c函数,前面说过普通c函数的参数传递是通过把参数值写入活动的程序栈(用户态栈或者内核态栈)实现的)。
内核为什么不直接把用户态的栈拷贝到内核态的栈而要去通过寄存器来传呢?首先,同事操作两个栈是比较复杂的,其次,寄存器的使用使得系统调用处理程序的结构与其它异常处理程序的结构类似。
进入退出系统调用
系统调用进入:
当用户态进程发出int $0x80指令时,cpu切换到内核态并开始从地址system_call处开始执行指令。System_call()函数首先把系统调用号和这个异常处理程序可以用到的所有cpu寄存器保存到相应的内核栈中,不包括由控制单元已自动保存的eflags,cs,eip,ss,exp寄存器。
系统调用退出:
用户态的寄存器刚进来到系统调用的时候被保存到了内核栈中,错误的返回值会被写到刚开始传递系统调用号的那个eax寄存器所在栈的位置。(那么将来当用户态恢复执行的时候,eax寄存器里面的内容就是系统调用的返回码了。)
总结
现在,不但对API和系统调用之间的关系十分了解,而且深刻理解了调用一个API函数底层工作过程,有了更深层次的认识!
注:本文部分类容参考自 Linux编程中关于API与系统调用之间的关系
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)