
【网络爬虫】【python】网络爬虫(四):scrapy爬虫框架(架构、win/linux安装、文件结构)
scrapy框架的学习,目前个人觉得比较详尽的资料主要有两个:1.官方教程文档、scrapy的github wiki;2.一个很好的scrapy中文文档:http://scrapy-chs.readthedocs.org/zh_CN/0.24/index.html; 剩下的就是网上其他的一些demo。 一、scrapy框架结构 还是先上个图吧,这
scrapy框架的学习,目前个人觉得比较详尽的资料主要有两个:
1.官方教程文档、scrapy的github wiki;
2.一个很好的scrapy中文文档:http://scrapy-chs.readthedocs.org/zh_CN/0.24/index.html;
剩下的就是网上其他的一些demo。
一、scrapy框架结构
还是先上个图吧,这个图几乎在网上一搜scrapy随处可见,其实它很好地反应了这个框架的运作流程及各个组件之间交互的过程。
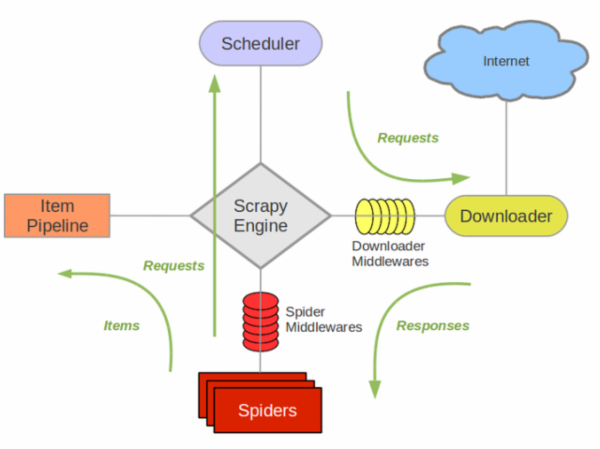
scrapy之所以能作为框架,是因为其抽取了普通爬虫的共同特征和基本原理并加以封装,有没有发现其实我们之前写的各种爬虫,原理其实都大同小异?什么抓页面、存储、解析页面、提取特征信息……爬虫就这么几个步骤,当然工业界的爬虫可能还要考虑更多比如爬虫效率、稳定性、分布式爬虫协调、兼容、信息清洗判重、数据结构化存储等等。一般程序员的习惯是在写过程序之后总想着重构一下,抽出一些公共的方法将其模板化,下次再用时就方便了。是的,你当然可以将自己写过的代码重构,但是这些工作早就有人帮做好了,直接拿来用甚至还比你自己写的要方便:“scrapy是一套基于Twisted的异步处理框架,是纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫”。并且其优秀的思想也是值得借鉴的——入门阶段:学会怎么使用scrapy,调用其接口能完成一个爬虫的功能;提高阶段:研究scrapy的源码也很有必要,看看一个优秀的爬虫框架是怎么写的。
scrapy的几个组件:
(1) Scrapy Engine(引擎):整体驱动数据流和控制流,触发事务处理。
(2) Scheduler(调度):维护一个引擎与其交互的请求队列,引擎发出请求后返还给它们。
(3) Downloader(下载器):下载网页,将网页给蜘蛛Spider.
(4) Spider(蜘蛛):这个是核心,一个蜘蛛能处理一个域名或一组域名,作用是定义特定网站的抓取和解析规则。定义对于不同网页结构,处理的方式也不一样,需要定义不同的蜘蛛。
蜘蛛抓取流程:
- step1:调用start_requests()获取第一个url请求,请求返回后调取回调函数parse。
- step2:回调函数中解析网页,返回项目对象、请求对象或两者的迭代。请求也包含一个回调,然后被scrapy下载,然后指定其他回调处理。
- step3:回调函数parse()中解析网页,方法:Xpath选择器(或者可以用BeautifulSoup, lxml等),生成解析的数据项。
- step4:蜘蛛spider返回项目给项目管道Item Pipeline。
(5) Item Pipeline(项目管道):处理蜘蛛解析过后的数据结果,清洗、验证、存储数据,存放给item字段field。
(6) Downloader middlewares(下载器中间件):引擎与下载器之间的钩子框架,处理引擎与下载器之间的请求/响应。可以自定义代码来扩展scrapy。
(7) Spider middlewares(蜘蛛中间件):引擎与蜘蛛之间的钩子框架,处理蜘蛛的响应输入/请求输出。可以自定义代码来扩展scrapy。
(8) Scheduler middlewares(调度中间件):引擎与调度之间的中间件,处理引擎与调度的请求/响应。可以自定义代码来扩展scrapy。
二、Scrapy安装(win/linux)
搭建scrapy框架需要的几个模块:python2.7.6, pywin32, twisted(zope.interface + pyOpenSSL + twisted),lxml, scrapy(安装之前要安装easytool)
1.windows安装
(1) 安装python 2.7:官网下载安装包,双击运行,最后需要将python安装目录添加到系统变量里,然后才能在控制台进入python shell。
(2) 安装pywin32:注意对应python版本,下载地址:http://sourceforge.net/projects/pywin32/files/,或者点击这里下载。
(3) 安装twisted
依赖几个包:
- zope.interface:https://pypi.python.org/pypi/zope.interface#download,或者点击这里下载,安装后在cmd进入python shell,如果”import zope.interface“没有问题说明安装成功。
- pyOpenSSL:(注意对应python版本)https://pypi.python.org/pypi/pyOpenSSL,或者点击这里下载,安装后在cmd进入python shell,如果”import OpenSSL”没有问题说明安装成功。
- twisted:(注意对应python版本)http://twistedmatrix.com/trac/wiki/Downloads,或者点击这里下载。安装后在cmd进入python shell,如果”import twisted”没有问题说明安装成功。
(4) 安装lxml:https://pypi.python.org/pypi/lxml/,或者点击这里下载,安装后在cmd进入python shell,如果”import lxml”没有问题说明安装成功。
(5) 安装scrapy:
- 通过easytool安装,easytool下载:http://pypi.python.org/packages/2.7/s/setuptools/setuptools-0.6c11.win32-py2.7.exe,或者点击这里下载,安装完后要将python安装目录下Scripts目录路径添加到系统变量中(就是Path变量D:\Python27\Scripts)。
- 下载scrapy:https://pypi.python.org/pypi/Scrapy,或者点击这里下载,下载完后,在D:\Python27,解压出来(有个dist文件夹,里面有Scrapy-0.24.2.tar文件),运行cmd,cd到该解压目录下,在cmd中输入”easy_install Scrapy”,完成scrapy的安装,然后在cmd中,cd D:\Python27,输入scrapy进行验证,如果下图,则安装成功。

2.linux安装
可以按照这里的方法安装:(转载http://www.cnblogs.com/HelloPython/)
第一步:为了安装这个packages,在ubuntu下运行lsb_release -cs,显示

第二步:现在需要做的就是用vi添加deb http://archive.scrapy.org/ubuntu precise main 到 /etc/apt/sources.list中去

第三步:然后运行 curl -s http://archive.scrapy.org/ubuntu/archive.key | sudo apt-key add-
第四步:再更新源sudo apt-get update
第五步:最后安装 sudo apt-get install scrapy-0.1X,可选择不同版本,我安装的是0.16

三、scrapy文件结构
1.新建scrapy项目
设定项目名称为mytest,cd到需要创建项目的目录:scrapy startproject mytest,会自动生成目录结构,如下:
mytest/
scrapy.cfg #-------------------项目配置文件
mytest/
__init__.py
items.py #-------项目数据字段文件
pipelines.py #-------项目管道文件
settings.py #---------项目配置文件
spiders/ #----------项目存放蜘蛛的目录
__init__.py
...
2.文件结构
(1) item.py:项目数据字段文件,定义需要的数据段,这些字段即为爬取下来数据中提取的,可以通过定义Item类实现。
from scrapy.item import Item, Field
class MyItem(Item):
userid = Field()
username = Field()
tweeted = Field()
time = Field()
(2) spider.py:用户自定义蜘蛛,其中:
- name:网络蜘蛛名称,要唯一。
- start_urls:是网络蜘蛛开始爬取第一个url,可以包括多个url。
- parse()函数: 网络蜘蛛爬取后response的对象。负责解析响应数据,是spider函数抓到第一个网页以后默认调用的callback,避免使用个这个名字来定义自己的方法。
from scrapy.spider import BaseSpider
class MySpider(BaseSpider):
name = "myspider"
allowed_domains = ["sina.com"]
start_urls = ["http://www.sina.com",
"http://www.sina.com/news"
]
def parse(self, response): #--------------------这就是callback回调函数
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
(3) pipeline.py:管道文件,接收item各字段对应数据,放到数据库mongodb或mysqldb
(4) setting.py:配置信息
3.spider的选择器Xpath(解析网页)
(1) 选择器的四个基本方法
xpath():返回一个选择器列表,每个代表xpath选择的,当于正则解析。
css():返回一选择器列表,每个代表css选择的。
extract():返回一个unicode字符串。
re():返回一个unicode字符串从正则表达式中选出的。
(2) 几个xpath例子
/html/head/title: 选择所有<head>标签内部的<title>标签内容
/html/head/title/text(): 选择所有的位于<title>标签内部的<text>标签(文本)内容
//td: 选择所有的<td>元素
//div[@class="mine"]: 选择所有包含class=”mine“属性的div标签元素
(3) xpath路径表达式:
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
关于选择器,这个再下一篇python系列五当中会提到具体实例应用,这里暂且先写到这里。
原创文章,转载请注明出处http://blog.csdn.net/dianacody/article/details/39743379
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)