
使用 Grafana 监控 Linux 性能
更多 Linux 资源 Linux 命令备忘单 高级 Linux 命令备忘单 免费在线课程:RHEL 技术概述 Linux 网络备忘单 SELinux 备忘单 Linux常用命令备忘单 什么是 Linux 容器? 我们最新的 Linux 文章 由于对市场上可用的家用路由器感到失望,我花了一些时间将 Linux(在我的情况下为CentOS)设置为家用路由器。这既是一个很好的练习,也是我早期使用 Li
更多 Linux 资源
-
Linux 命令备忘单
-
高级 Linux 命令备忘单
-
免费在线课程:RHEL 技术概述
-
Linux 网络备忘单
-
SELinux 备忘单
-
Linux常用命令备忘单
-
什么是 Linux 容器?
-
我们最新的 Linux 文章
由于对市场上可用的家用路由器感到失望,我花了一些时间将 Linux(在我的情况下为CentOS)设置为家用路由器。这既是一个很好的练习,也是我早期使用 Linux 时的一点怀旧之情。完成基础设置后,我想要一种方法来跟踪各种统计信息,例如网络流量、磁盘使用情况等。古老的Cacti无疑是一个选择,但现在感觉有点过时了。我更喜欢使用具有更现代感的更新工具。这就是导致我Grafana的原因。这是我如何设置的基本演练。这是一个基本安装,在同一主机上合并了 collectd、InfluxDB 和 Grafana。
图片来源:
开源网站
收藏
什么,你以为我会直接跳进Grafana?我们首先需要收集数据,而在 CentOS 上做到这一点的最好方法是通过collectd。
在 CentOS 上收集的最简单方法是通过EPEL 存储库。如果你是 CentOS 的新手或者不熟悉 Fedora 的 EPEL repo,那么你只需要这个命令就可以开始了:
yum install epel-release
现在启用了 EPEL 存储库,以相同的方式安装 collectd 很容易:
yum install collectd
EPEL 中还有其他可用的 collectd 插件,但基础足以满足我们的目的。如果基本插件不能满足您的需求,我会鼓励您探索可用的插件。
现在 collectd 已安装,我们需要对其进行配置以发送数据。 Collectd 生成统计信息,但我们需要将它放在 Grafana 可以使用的地方。
在 /etc/collectd.conf 中有一些我们需要配置的东西。在 Global 部分,取消注释 Hostname、BaseDir、PIDFile、PluginDir 和 TypesDB 的行。您需要修改 Hostname,但其他默认值应该没问题。它应该看起来像这样:
主机名 “YourHostNameHere”
#FQDNLookup 真
BaseDir "/var/lib/collectd"
PIDFile “/var/run/collectd.pid”
PluginDir “/usr/lib64/collectd”
TypesDB “/usr/share/collectd/types.db”
现在我们已经设置了基本的应用程序信息,我们需要启用我们想要使用的插件。例如,我有 syslog、cpu、disk、interface、load、memory 和 network 未注释。其中,默认值适用于除 network 之外的所有内容。网络插件用于向我们的收集器发送数据,在本例中为InfluxDB。网络插件需要指向你的 InfluxDB 服务器。因为在本例中我们在本地进行所有操作,所以我们指向 localhost。它应该如下所示:
<插件网络>
服务器“127.0.0.1”“8096”
</插件>
InfluxDB
现在我们已经完成了 collectd,我们必须配置 InfluxDB 以提取 collectd 正在生成的数据。由于 InfluxDB 不在 EPEL 中,我们必须从它的存储库中提取它。下面的命令很容易:
cat <<EOF > /etc/yum.repos.d/influxdb.repo
[涌入数据库]
名称 u003d InfluxDB 存储库 - RHEL $releasever
baseurl u003d https://repos.influxdata.com/centos/$releasever/$basearch/stable
启用 u003d 1
gpg检查 u003d 1
gpgkey u003d https://repos.influxdata.com/influxdb.key
EOF
完成后,使用 yum install influxdb 安装软件包,然后就可以进行配置了。在 /etc/influxdb/influxdb.conf 配置文件中只需要做几件事。
在 /etc/influxdb/influxdb.conf 的 [http] 部分中,设置 enabled u003d true 和 bind-address u003d ":8096"。它应该如下所示:
[http]
# 确定是否启用 HTTP 端点。
启用 u003d 真
# HTTP 服务使用的绑定地址。
绑定地址u003d“:8086”
然后向下滚动到 [[collectd]] 部分并像这样配置它:
[[已收集]]
启用 u003d 真
绑定地址u003d“:8096”
数据库u003d“收集”
typesdb u003d "/usr/share/collectd"
此时,我们可以继续启动这两个服务以确保它们正常工作。首先,我们将启用 collectd 并确保它正在发送数据。与其他服务一样,我们将为此使用 system。在下面的示例中,您将看到使用的命令和正在运行的 collectd 守护程序的输出。
[jperrin@monitor ~]$ sudo systemctl enable collectd
[jperrin@monitor ~]$ sudo systemctl start collectd
[jperrin@monitor ~]$ sudo systemctl status collectd
● collectd.service - Collectd 统计信息守护进程
已加载:已加载(/usr/lib/systemd/system/collectd.service;已启用;供应商预设:已禁用)
活跃:自 2017 年星期六-08-02 11:22:18 PDT 以来活跃(运行); 6分钟前
文档:man:collectd(1)
人:collectd.conf(5)
主PID:18366(收集)
CGroup:/system.slice/collectd.service
└─18366 /usr/sbin/collectd
8 月 2 日 11:22:18 monitor collectd[18366]: plugin_load: 插件“磁盘”成功加载。
8 月 2 日 11:22:18 monitor collectd[18366]: plugin_load: 插件“接口”成功加载。
8 月 2 日 11:22:18 monitor collectd[18366]: plugin_load: 插件“加载”成功加载。
8 月 2 日 11:22:18 monitor collectd[18366]: plugin_load: 插件“内存”成功加载。
8 月 2 日 11:22:18 monitor collectd[18366]: plugin_load: 插件“network”成功加载。
8 月 2 日 11:22:18 monitor collectd[18366]:检测到 Systemd,试图发出准备就绪信号。
8 月 2 日 11:22:18 monitor collectd[18366]:初始化完成,进入读取循环。
8 月 2 日 11:22:18 监控 systemd[1]:启动 Collectd 统计信息守护程序。
现在 collectd 正在工作,启动 InfluxDB 并确保它正在从 collectd 收集数据。
[jperrin@monitor ~]$ sudo systemctl enable influxdb
[jperrin@monitor ~]$ sudo systemctl start influxdb
[jperrin@monitor ~]$ sudo systemctl status influxdb
● influxdb.service - InfluxDB 是一个开源、分布式、时间序列数据库
已加载:已加载(/usr/lib/systemd/system/influxdb.service;已启用;供应商预设:已禁用)
活跃:自 2017 年星期六-07-29 18:28:20 PDT 以来活跃(运行); 1 周 6 天前
文档:https://docs.influxdata.com/influxdb/
主PID:23459(流入)
CGroup:/system.slice/influxdb.service
└─23459 /usr/bin/influxd -config /etc/influxdb/influxdb.conf
8 月 2 日 10:35:10 monitor influxd[23459]: [I] 2017-08-12T17:35:10Z 从 collectd.autogen.cpu_value 中选择平均值(值)主机 u003d~ /^monitor $/ AND type_instance u003d 'interrupt' AND time > 417367h GR...) service\u003dquery
8 月 2 日 10:35:10 监视器涌入[23459]:[httpd] 172.20.1.40, 172.20.1.40,::1 - - [12/Aug/2017:10:35:10 -0700] "GET /query?dbu003dcollectd&epochu003dms&qu003dSELECT+mean%28%22value%22%29+FROM+%22load_shortte...ean%28%22value%
8 月 2 日 10:35:10 monitor influxd[23459]: [I] 2017-08-02T17:35:10Z 从 collectd.autogen.cpu_value 中选择平均值(值)主机 u003d~ /^monitor$ / AND type_instance u003d 'nice' AND time > 417367h GROUP B...) serviceu003dquery
正如我们在上面的输出中看到的,服务正在运行,并且正在收集数据。从这里开始,唯一要做的就是通过 Grafana 呈现它。
格拉法纳
要安装 Grafana,我们将像使用 InfluxDB 一样创建另一个存储库。不幸的是,Grafana 的人并没有在 repo 中单独保留发布版本,所以看起来我们正在使用 EL6 repo,即使我们在 EL7 上进行这项工作。
cat <<EOF > /etc/yum.repos.d/grafana.repo
[格拉法纳]
房子\u003d格拉法纳
baseurl\u003dhttps://packagecloud.io/grafana/stable/el/6/$basearch
repo_gpgcheck\u003d1
启用\u003d1
gpgcheck\u003d1
gpgkey\u003dhttps://packagecloud.io/gpg.key https://grafanarel.s3.amazonaws.com/RPM-GPG-KEY-grafana
ssl验证\u003d1
sslcacert\u003d/etc/pki/tls/certs/ca-bundle.crt
EOF
现在存储库已就位并启用,我们可以安装 Grafana,就像我们对其他存储库所做的那样:yum install grafana。完成后,我们就可以开始进行配置了。对于本教程,我们将设置管理员用户名和密码,因为我们正在为教程和单个用户实例执行此操作。如果您想开始更多地使用 Grafana,我绝对鼓励您阅读文档。
要完成这个相当基本的配置,只需取消注释 /etc/grafana/grafana.ini 的 [security] 部分中的 admin_user 和 admin_password 行,并设置您自己的值。在这种情况下,我使用 admin/admin,因为这就是您在示例中所做的,对吧?
[安全]
# 默认管理员用户,在启动时创建
管理员_用户 u003d 管理员
# 默认管理员密码,可以在首次启动 grafana 之前更改,或在配置文件设置中更改
管理员_密码u003d管理员
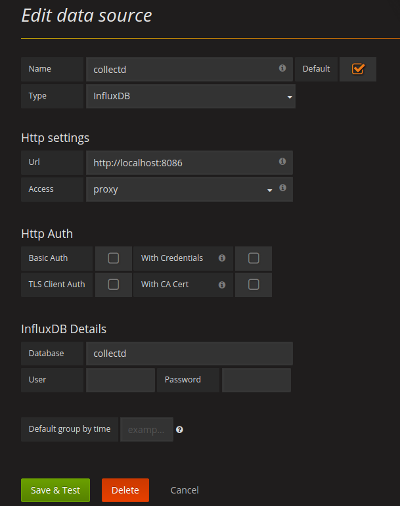 现在您可以使用 systemctl start grafana-server 启动 Grafana 并通过 Web 界面进行配置。首次登录后,系统会提示您配置一些东西,包括数据源和仪表板。因为我们都是在本地主机上进行的,所以您可以作弊并使用屏幕截图中的数据源设置。别担心,我们就快到了,只剩下一点事情要做了。
现在您可以使用 systemctl start grafana-server 启动 Grafana 并通过 Web 界面进行配置。首次登录后,系统会提示您配置一些东西,包括数据源和仪表板。因为我们都是在本地主机上进行的,所以您可以作弊并使用屏幕截图中的数据源设置。别担心,我们就快到了,只剩下一点事情要做了。
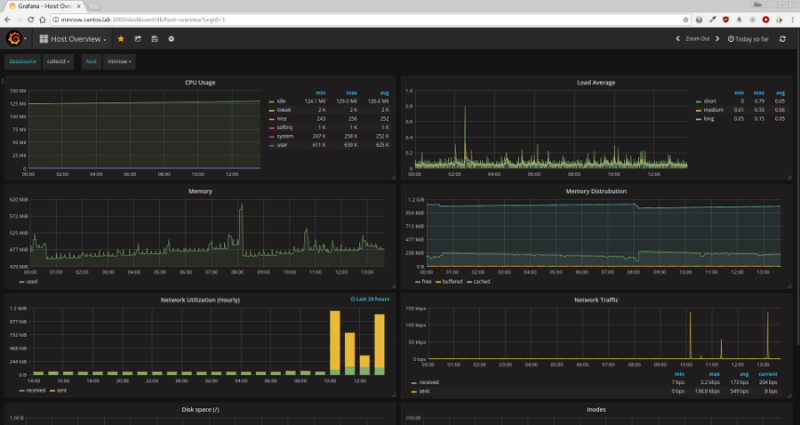
配置好数据源后,系统会提示您创建第一个仪表板。虽然你当然可以做到这一点,但对于 Grafana 的第一次运行来说有点吓人。一个简单的解决方案是导入 Grafana 网站上的模板之一。我使用了主机概述。它提供了一组很好的指标和图表作为使用和构建的基础。
设置好所有内容后,现在取决于您的个人喜好和进一步的修补。我再次推荐阅读文档,因为这里没有描述大量的选项和更改。
本文最初发表在Jim Perrin的博客上,经许可重新发布。
更多推荐
 0
0 0
0- 0



 已为社区贡献12897条内容
已为社区贡献12897条内容

所有评论(0)