k8s笔记资源限制,亲和和性 污点和容忍
可用于基于服务类型干预Pod调度结果,如对磁盘I/O要求高的pod调度到SSD节点,对内存要求比较高的pod调度的内存较高的节点对服务器打标签,调度到指定标签yaml。
镜像下载失败
当宿主机资源不足时,会把pod kill ,在其他node 重建
在宿主机放可能多的资源
requests(请求) limits(限制) 超出百分比
容器
pod
namespace级别
pod使用资源过多,导致宿主机资源不足,会导致重建pod
cpu 内存限制
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
kind: Deployment
metadata:
name: limit-test-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels: #rs or deployment
app: limit-test-pod
# matchExpressions:
# - {key: app, operator: In, values: [ng-deploy-80,ng-rs-81]}
template:
metadata:
labels:
app: limit-test-pod
spec:
containers:
- name: limit-test-container
image: lorel/docker-stress-ng
resources:
limits:
cpu: "2"
memory: "512Mi"
requests:
memory: "512M"
cpu: "2"
#command: ["stress"]
args: ["--vm", "3", "--vm-bytes", "256M"]
#nodeSelector:
# env: group1
资源限制
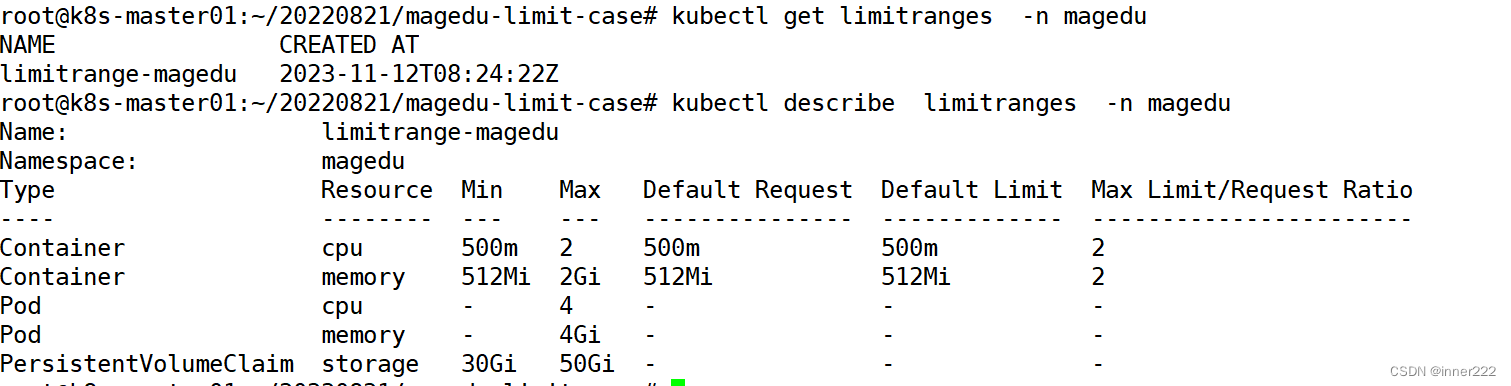
apiVersion: v1
kind: LimitRange
metadata:
name: limitrange-magedu
namespace: magedu #限制那个命名空间
spec:
limits:
- type: Container #限制的资源类型
max:
cpu: "2" #限制单个容器的最大CPU
memory: "2Gi" #限制单个容器的最大内存
min:
cpu: "500m" #限制单个容器的最小CPU
memory: "512Mi" #限制单个容器的最小内存
default:
cpu: "500m" #默认单个容器的CPU限制
memory: "512Mi" #默认单个容器的内存限制
defaultRequest:
cpu: "500m" #默认单个容器的CPU创建请求
memory: "512Mi" #默认单个容器的内存创建请求
maxLimitRequestRatio:
cpu: 2 #限制CPU limit/request比值最大为2
memory: 2 #限制内存limit/request比值最大为1.5
- type: Pod
max:
cpu: "4" #限制单个Pod的最大CPU
memory: "4Gi" #限制单个Pod最大内存
- type: PersistentVolumeClaim #限制pvc
max:
storage: 50Gi #限制PVC最大的requests.storage
min:
storage: 30Gi #限制PVC最小的requests.storage

cpu limit/request 限制
限制超出
运行yaml成功但是不会创建pod
但是有deployment
查看kubectl get deployment -n magedu -oyaml
命名空间级别的限制
亲和性和反亲和性
pod调度流程
通过命令行或者dashboard,创建pod或者调用k8s api,请求发送到apiserver,apiserver 把pod 放到etcd里,scheduler 从etcd获取事件,执行调度,调度成功后,把结果返回给apiserver, 给pod 选择一个node,把调度结果返回给apiserver,这个过程叫创建绑定(pod 分配给那个node?),apiserver 把这个事件写入etcd, scheduler获取绑定事件,kubelet调用运行时( ),创建容器并运行,拉取镜像kubelet执行初始化, rootfs 调度时会过滤不符合的节点,对节点打分,选择最合适的节点,评分一致,scheduler会随机选择一个。
调度到
node
sshd 大内存 , gpu服务器
nodeSelector简介
可用于基于服务类型干预Pod调度结果,如对磁盘I/O要求高的pod调度到SSD节点,对内存要求比较高的
pod调度的内存较高的节点
对服务器打标签,调度到指定标签
root@k8s-master02:~# kubectl label node 192.168.1.27 project=magedu
yaml
nodeSelector:
project: magedu
disktype: ssd
nodeName案例
指定pod调度到那个目的主机
数据库就运行到指定节点

node affinity:
Selector
requiredDuringSchedulingIgnoredDuringExecution #必须满足pod调度匹配条件,如果不满足则不进行调度
preferredDuringSchedulingIgnoredDuringExecution #倾向满足pod调度匹配条件,不满足的情况下会调度的不符合条件的Node上
IgnoreDuringExecution表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,也会继续运行当前的Pod。
Affinity与anti-affinity的目的也是控制pod的调度结果,但是相对于nodeSelector,Affinity(亲和)与anti-affinity(反亲和)的功能更加强大:
affinity与nodeSelector对比:
1、亲和与反亲和对目的标签的选择匹配不仅仅支持and,还支持In、NotIn、Exists、DoesNotExist、Gt、Lt。
In:标签的值存在匹配列表中(匹配成功就调度到目的node,实现node亲和)
NotIn:标签的值不存在指定的匹配列表中(不会调度到目的node,实现反亲和)
Gt:标签的值大于某个值(字符串)
Lt:标签的值小于某个值(字符串)
Exists:指定的标签存在
2、可以设置软匹配和硬匹配,在软匹配下,如果调度器无法匹配节点,仍然将pod调度到其它不符合条件的节点。
3、还可以对pod定义亲和策略,比如允许哪些pod可以或者不可以被调度至同一台node。
硬亲和 :必须调度到那个节点,不匹配就失败
软亲和:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #匹配条件1,同一个key的多个value只有有一个匹配成功就认为当前key匹配成功
- key: disktype
operator: In
values:
- ssd
- hddx
- key: project #匹配条件2,当前key也要匹配成功一个value,即条件1和条件2必须同时每个key匹配成功一个value,否则不调度
operator: In
values:
- magedu
pod 亲和和反亲和
Pod亲和性与反亲和性可以基于已经在node节点上运行的Pod的标签来约束新创建的Pod可以调度到的
目的节点,注意不是基于node上的标签而是使用的已经运行在node上的pod标签匹配。
其规则的格式为如果 node节点 A已经运行了一个或多个满足调度新创建的Pod B的规则,那么新的
Pod B在亲和的条件下会调度到A节点之上,而在反亲和性的情况下则不会调度到A节点至上。
其中规则表示一个具有可选的关联命名空间列表的LabelSelector,只所以Pod亲和与反亲和需可以通
过LabelSelector选择namespace,是因为Pod是命名空间限定的而node不属于任何nemespace所以
node的亲和与反亲和不需要namespace,因此作用于Pod标签的标签选择算符必须指定选择算符应用
在哪个命名空间。
从概念上讲,node节点是一个拓扑域(具有拓扑结构的域),比如k8s集群中的单台node节点、一个机架、
云供应商可用区、云供应商地理区域等,可以使用topologyKey来定义亲和或者反亲和的颗粒度是
node级别还是可用区级别,以便kubernetes调度系统用来识别并选择正确的目的拓扑域。
pod 与pod是否调度到同一个node节点
pod硬亲和: pod和pod必须在同一个node,必须匹配成功
pod硬反亲和: pod必须不在同一个node
pod软反亲和:pod 能不在同一个node就不在一个node
污点和容忍:
master 只负责集群管理,不负责容器运行
污点(taints),用于node节点排斥 Pod调度,与亲和的作用是完全相反的,即taint的node和pod是排斥调度关系。
容忍(toleration),用于Pod容忍node节点的污点信息,即node有污点信息也会将新的pod调度到node
kubectl uncordon 192.168.1.24 #取消污点
污点的三种类型:
NoSchedule: 表示k8s将不会将Pod调度到具有该污点的Node上
# kubectl taint nodes 172.31.7.111 key1=value1:NoSchedule #设置污点
node/172.31.7.111 tainted
# kubectl describe node 172.31.7.111 #查看污点
Taints: key1=value1:NoSchedule
# kubectl taint node 172.31.7.111 key1:NoSchedule- #取消污点
node/172.31.7.111 untainted
PreferNoSchedule: 表示k8s将尽量避免将Pod调度到具有该污点的Node上
NoExecute: 表示k8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod强制驱逐出去
# kubectl taint nodes 172.31.7.111 key1=value1:NoExecute #key 和value 可以自定义
kubectl cordon: 不会调度新的pod,不会驱逐
NoExecute :不会调度新的pod,会驱逐
驱逐(eviction,节点驱逐),用于当node节点资源不足的时候自动将pod进行强制驱逐,以保证当前node节点的正常运行。
Kubernetes基于是QoS(服务质量等级)驱逐Pod , Qos等级包括目前包括以下三个:

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)