
elk收集k8s微服务日志_微服务日志elk,2024年最新Linux运维学习的三个终极问题及学习路线规划
stdout{#该项为测试模式,将收集的日志内容输出到logstash的日志中。hosts => “elasticsearch:9200”#这里的索引名称使用日志中包含的变量自动命名。grok {#这里使用grok将java日志分割为json格式。(img-KsmXuO8O-1713130770147)]取:vip1024b (备注运维)**
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
multiline.match: after #将匹配到不是以时间开头的行就合并到上一个事件中
- condition: #通过标签、命名空间筛选需要的pod日志,这里是匹配前端服务的日志,这里是因为前端的日志格式和后端的日志格式不一样,所以分开收集
and:
- or:
- equals:
kubernetes.labels:
app: nodejs
- equals:
kubernetes.namespace: nodejs
config:
- type: container
symlinks: true
paths:
- /var/log/containers/${data.kubernetes.pod.name}_${data.kubernetes.namespace}_${data.kubernetes.container.name}-*.log
processors: #配置filebeat识别收集的日志格式为json,这里前端的日志已经配置为了json格式,所以在filebeat收集的时候需要将日志识别为json格式的日志,不配置的话收集出来的是一整串日志,和普通日志一样
- decode_json_fields:
fields: ["message"]
target: ""
overwrite_keys: true
add_error_key: true
output.logstash: #将收集的日志输出到logstash
hosts: ['logstash.elk:5044']
**logstash配置**
vi logstash-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-configmap
namespace: elk
labels:
app: logstash
data:
logstash.conf: |
input {
beats {
port => 5044
# codec => “json”
}
}
filter {
grok { #这里使用grok将java日志分割为json格式
match => {
“message” => “%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:level}\s+%{NUMBER:thread}\s±–\s+[%{DATA:thread_name}]\s+%{JAVACLASS:java_class}\s+:\s+%{GREEDYDATA:log_message}”
}
}
}
output {
# stdout{ #该项为测试模式,将收集的日志内容输出到logstash的日志中
# codec => rubydebug
# }
elasticsearch {
hosts => “elasticsearch:9200” #这里的索引名称使用日志中包含的变量自动命名
index => “%{[kubernetes][container][name]}-%{+YYYY.MM.dd}”
}
}
这里对java日志进行一下说明,java日志都是特定的日期格式开头,基本上都是单行的,除了报错日志,报错日志会换行,因为报错栈非常多,filebeat收集日志是一行一行收集的,在收集java报错日志的时候就会出现问题,错误日志的报错栈也被分开很多行去收集了,这是有问题的,所以会在filebeat收集java日志的时候加入multiline,进行事务的一个合并,下面来看一下java的日志
正常日志
可以看到都是以特定的时间格式开头

错误日志
其实错误日志的结构和正常日志是一样的,只是后面的报错栈被分行了,所以在filebeat使用multiline将这些不是以时间开头的行合并到上一个事件中即可

可以使用kibana试验一下对java日志的分割是否能生效
%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:level}\s+%{NUMBER:thread}\s±–\s+[%{DATA:thread_name}]\s+%{JAVACLASS:java_class}\s+:\s+%{GREEDYDATA:log_message}
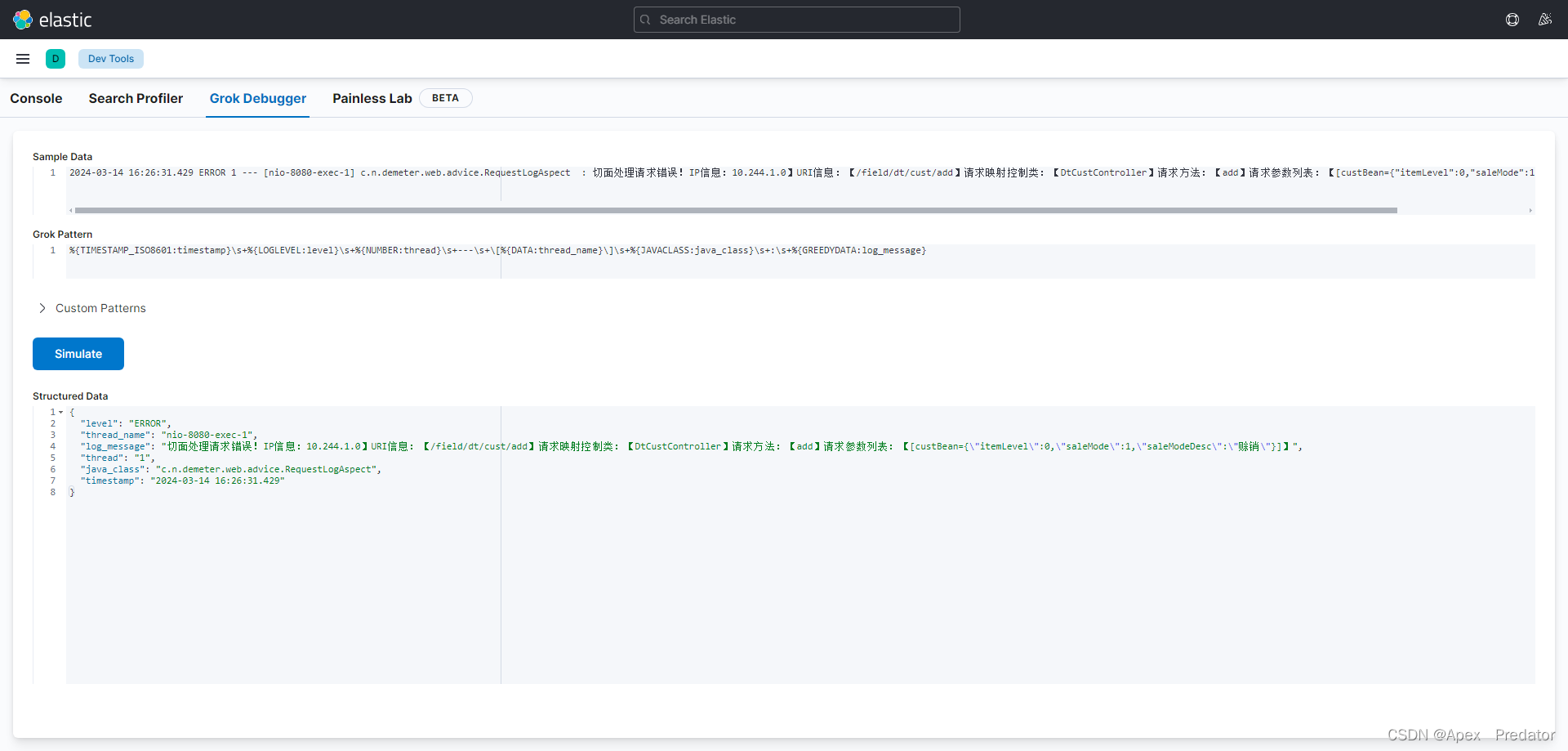
前端日志对于nginx的配置也做一下说明,需要在nginx配置文件中提前定义nginx的日志格式
vi nginx-public.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: public-config
namespace: nodejs
data:
nginx.conf: |
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format access '{"timestamp":"$time_iso8601",' #定义json格式的日志
'"remote_addr":"$remote_addr",'
'"remote_user":"$remote_user",'
'"body_bytes_sent":$body_bytes_sent,'
'"request_time":$request_time,'
'"status": "$status",'
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
取:vip1024b (备注运维)**
[外链图片转存中…(img-KsmXuO8O-1713130770147)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)