第七篇:k8s集群使用helm3安装Prometheus Operator
本文主要介绍如何基于helm3安装prometheus oprator. 全文包括values.yaml文件的配置,以及安装过程中遇到的问题修复
安装Prometheus Operator
目前网上主要有两种安装方式,分别为:1. 使用kubectl基于manifest进行安装 2. 基于helm3进行安装。第一种方式比较繁琐,需要手动配置yaml文件,特别是需要配置pvc相关内容时,涉及到的yaml文件太多,故本文选用第二种基于helm安装的方式。
下面开始重点介绍安装流程,其实安装过程可以概括为以下几点:
- 配置服务类型,主要是altermanager/prometheus/grafana这三个服务,如果想在浏览器访问,就需要进行服务类型的配置,默认情况使用的是ClusterIP,这样无法在浏览器中访问,这里我们使用LoadBalancer和ingress的方式配置服务,这样我们就可以使用域名和IP:Port进行访问。关于ingress与LoadBalaner的部署可以参考 第二篇:k8s之ingress-nginx-controller与metallb部署
- 持久化存储的使用,默认安装没有配置持久化存储,默认情况是安装到部署的节点本地,这里会有数据丢失的风险,生产环境下需要配置自己的持久化存储,我这里使用的是ceph rbd作为storageclass,如果没有安装ceph csi, 可以参考我之前的文章 第三篇:k8s之容器存储接口(CSI)ceph-csi-rbd部署
配置altermanager/prometheus/grafana三个服务
服务类型配置
将这个服务的类型由ClusterIP改成LoadBalancer
分别在这三个服务对应的session下找到service项进行如下配置
prometheus:
...
service:
...
type: LoadBalancer
将grafana的服务开启并配置ingress,公司内部通过域名访问
修改grafana配置下的ingress选项,开启功能,并配置hosts
grafana:
...
ingress:
enable: true
...
hosts: [monitor.prod.wuyacapital.com]
所有Pod绑定到master节点 (可选项,没有这方面的需求可以跳过)
为方便管理应用服务,将应用服务与每日作业计算任务进行区分,所有Pod均绑定到master类型的节点上,这里通过使用affinity进行配置对应的Pod.
所涉及的Pod主要包括:grafana, kube-state-metrics, prometheusOperator, prometheus, alertmanager。其中 grafana, kube-state-metrics, prometheusOperator由于没有Spec配置,所以直接放在其声明下即可,例如
grafana: # prometheusOperator/kube-state-metrics 类似
...
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- master01
- master02
- master03
...
对于 prometheus, alertmanager由于有Spec配置,所以放在各自的session下即可,例如:
prometheus: # alertmanager 对应 alertmanagerSpec, 配置类似,添加下面affinity的内容即可
...
prometheusSpec:
...
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- master01
- master02
- master03
...
storage配置
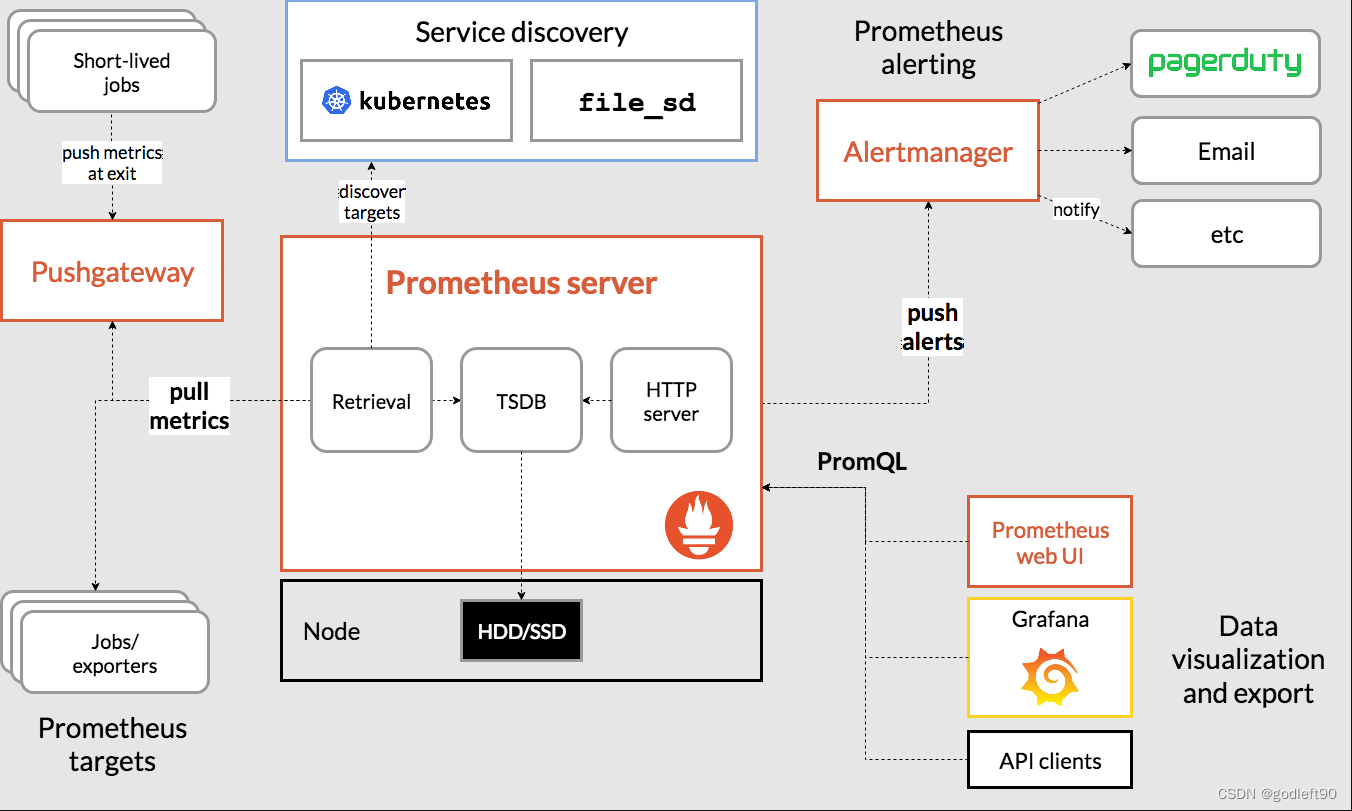
Prometheus在使用过程中会涉及到指标数据的存储问题,下面是Prometheus的架构图

这里我们可以看到我们需要存储指标数据以方便监控系统Grafana进行读取并展示。
我们使用的持久化存储为ceph rbd存储,对应的storageclass为csi-rbd-sc, 这是我之前创建的存储类,现在可以在这直接调用,涉及到存储的部分主要有以下2处:
(1) alertmanager—>alertmanagerSpec—>storage
(2) prometheus—>prometheusSpec—>storageSpec
内容如下:
volumeClaimTemplate:
spec:
storageClassName: csi-rbd-sc
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 100Gi #根据实际情况设置
配置完成后,查看完整的配置文件
启动部署脚本
helm upgrade --install prometheus --namespace monitoring --create-namespace prometheus-community/kube-prometheus-stack -f prometheus.yaml --debug
查看所有Pod的资源信息
master01 ➜ helm git:(master) ✗ kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Running 1 (3h47m ago) 3h49m
prometheus-grafana-bc859db95-s2pzh 3/3 Running 0 172m
prometheus-kube-prometheus-operator-8995df666-d7wl5 1/1 Running 0 3h49m
prometheus-kube-state-metrics-6855494647-njsc5 1/1 Running 0 166m
prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 0 3h49m
prometheus-prometheus-node-exporter-56m49 1/1 Running 0 3h49m
prometheus-prometheus-node-exporter-5b5cx 1/1 Running 0 3h49m
prometheus-prometheus-node-exporter-khzzn 1/1 Running 0 3h49m
prometheus-prometheus-node-exporter-nfj5m 1/1 Running 0 3h49m
prometheus-prometheus-node-exporter-pcjgz 1/1 Running 0 3h49m
prometheus-prometheus-node-exporter-r6r82 1/1 Running 0 3h49m
prometheus-prometheus-node-exporter-t8dsh 1/1 Running 0 3h49m
说明部署成功。
可以查看service信息,并打开浏览器查看prometheus服务http://192.168.1.192:9090, 查看所有的target是否监控成功
master01 ➜ helm git:(master) ✗ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3h50m
prometheus-grafana ClusterIP 10.101.246.163 <none> 80/TCP 3h50m
prometheus-kube-prometheus-alertmanager LoadBalancer 10.102.35.159 192.168.1.194 9093:30033/TCP 3h50m
prometheus-kube-prometheus-operator LoadBalancer 10.101.1.10 192.168.1.193 443:30001/TCP 3h50m
prometheus-kube-prometheus-prometheus LoadBalancer 10.106.88.156 192.168.1.192 9090:31242/TCP 3h50m
prometheus-kube-state-metrics ClusterIP 10.109.156.237 <none> 8080/TCP 3h50m
prometheus-operated ClusterIP None <none> 9090/TCP 3h50m
prometheus-prometheus-node-exporter ClusterIP 10.105.10.206 <none> 9100/TCP 3h50m
这里可以看到所有服务均可监控。
targets无法监控的问题
注意:这里经常会遇到这样的问题,kube-controller-manager与kube-scheduler的target是Down的状态,原因是因为这两个服务无法访问,为什么无法访问?原因是因为在k8s集群创建时,这两个服务的的bind-address绑定的是127.0.0.1,所以无法通过其他服务器访问。
解决方案:分别在这三台服务器上打开 /etc/kubernetes/manifests/kube-controller-manager.yaml与 /etc/kubernetes/manifests/kube-scheduler.yaml,然后找到bind-address这个字段,将后面的127.0.0.1替换成0.0.0.0即可。这里无需重启对应的服务,k8s会自动读取最新的配置。改完之后过一会,就可以看到这2哥监控正常了。
参考文档:解决controller与scheduler无法访问的问题
卸载流程
helm uninstall prometheus -n monitoring
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd probes.monitoring.coreos.com
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd thanosrulers.monitoring.coreos.com
查看pvc是否需要手动删除

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)