
快速排序并行实现MPI
简介常规的快速排序,先在数组中选取一个基准点,将数组分区为小于基准点和大于基准点(相同的数可以到任一边),对分区的子数组递归的执行分区的操作,当子数组长度为1时退出递归。此时数组就完成了排序过程。对快排的过程分析可以发现,分区以及对子数组排序的过程均可以并发执行,这里首先对数组进行分区,生成分区数组,为了保证不同分区不受到影响需要先完成分区再进行排序。处理器个数:4数组长度:1000具体...
·
简介
常规的快速排序,先在数组中选取一个基准点,将数组分区为小于基准点和大于基准点(相同的数可以到任一边),对分区的子数组递归的执行分区的操作,当子数组长度为1时退出递归。此时数组就完成了排序过程。
对快排的过程分析可以发现,分区以及对子数组排序的过程均可以并发执行,这里首先对数组进行分区,生成分区数组,为了保证不同分区不受到影响需要先完成分区再进行排序。
处理器个数:4
数组长度:1000
具体过程为:先在0号处理器创建一个1000维的数组,将数组广播道所有处理器,在0处理器对数组进行partition,将根据pivot值划分为两个子数组,左边的数组仍然留在0号进程,右边子数组分配给1号处理器,然后对0号和1号处理器中的数组分别进行递归操作,将0处理器中数组分给2号处理器,将1号处理器数据分给3号处理器,当没有可用的处理器时,数据划分完毕,开始各自进行快速排序,排序结束后,逐级向上返回,最后数据全部返回0处理器,排序结束。
代码
#include "StdAfx.h"
#include "stdafx.h"
#include"mpi.h"
#include<time.h>
#include<iostream>
#include <stdlib.h>
#include <stdio.h>
using namespace std;
#define TRUE 1
#define SIZE 10000
double wht_start_time,wht_end_time, end_time, start_time;
int Partition(int *wht_data,int wht_start,int wht_end)
{
int wht_pivo;
int wht_i, wht_j;
int wht_tmp;
wht_pivo=wht_data[wht_end];
wht_i=wht_start-1; /*wht_i(活动指针)*/
for(wht_j=wht_start;wht_j<wht_end;wht_j++)
if(wht_data[wht_j]<=wht_pivo)
{
wht_i++; /*wht_i表示比wht_pivo小的元素的个数*/
wht_tmp=wht_data[wht_i];
wht_data[wht_i]=wht_data[wht_j];
wht_data[wht_j]=wht_tmp;
}
wht_tmp=wht_data[wht_i+1];
wht_data[wht_i+1]=wht_data[wht_end];
wht_data[wht_end]=wht_tmp; /*以wht_pivo为分界,wht_data[wht_i+1]=wht_pivo*/
return wht_i+1;
}
void QuickSort(int *wht_data,int wht_start,int wht_end)
{
int wht_r;
int wht_i;
if(wht_start<wht_end)
{
wht_r=Partition(wht_data,wht_start,wht_end);
QuickSort(wht_data,wht_start,wht_r-1);
QuickSort(wht_data,wht_r+1,wht_end);
}
}
/*功能:求2的wht_num次幂*/
int exp2(int wht_num)
{
int wht_i;
wht_i=1;
while(wht_num>0)
{
wht_num--;
wht_i=wht_i*2;
}
return wht_i;
}
/*功能:求以2为底的wht_num的对数*/
int log2(int wht_num)
{
int wht_i, wht_j;
wht_i=1;
wht_j=2;
while(wht_j<wht_num)
{
wht_j=wht_j*2;
wht_i++;
}
if(wht_j>wht_num)
wht_i--;
return wht_i;
}
/*
* 函数名: para_QuickSort
* 功能:并行快速排序,对起止位置为wht_start和wht_end的序列,使用2的wht_m次幂个处理器进行排序
* 输入:无序数组wht_data[1,n],使用的处理器个数2^wht_m
* 输出:有序数组wht_data[1,n]
*/
void para_QuickSort(int *wht_data,int wht_start,int wht_end,int wht_m,int id,int MyID)
{
int wht_i, wht_j;
int wht_r;
int MyLength;
int *wht_tmp;
MPI_Status status;
MyLength=-1;
/*如果可供选择的处理器只有一个,那么由处理器id调用串行排序*/
if(wht_m==0)
{
wht_start_time=MPI_Wtime();
if(MyID==id)
QuickSort(wht_data,wht_start,wht_end);
return;
}
wht_start_time=MPI_Wtime();
/*由第id号处理器划分数据,并将后一部分数据发送到处理器id+exp2(wht_m-1),对应于算法步骤(1.2,1.3)*/
if(MyID==id)
{
/*将当前的无序区R[1,n]划分成左右两个无序的子区R[1,wht_i-1]和R[wht_i,n](1≤wht_i≤n)*/
/*(1.2) Pid: wht_r=patrition(wht_data,wht_i,wht_j)*/
wht_r=Partition(wht_data,wht_start,wht_end);
MyLength=wht_end-wht_r;
/*(1.3) Pid swht_end wht_data[wht_r+1,wht_m-1] to P(id+2m-1) */
/* {MyLength表示发送缓冲区地址;*/
/* 发送元素数目为1; */
/* MyID是消息标签 } */
MPI_Send(&MyLength,1,MPI_INT,id+exp2(wht_m-1),MyID,MPI_COMM_WORLD);
/*若缓冲区不空,则第id+2m-1号处理器取数据的首址是wht_data[wht_r+1]*/
if(MyLength!=0)
MPI_Send(wht_data+wht_r+1,MyLength,MPI_INT,id+exp2(wht_m-1),MyID,MPI_COMM_WORLD);
}
/*处理器idex+p2(wht_m-1)接受处理器id发送的消息*/
if(MyID==id+exp2(wht_m-1))
{
MPI_Recv(&MyLength,1,MPI_INT,id,id,MPI_COMM_WORLD,&status);
if(MyLength!=0)
{
wht_tmp=(int *)malloc(MyLength*sizeof(int));
if(wht_tmp==0) printf("Malloc memory error!");
MPI_Recv(wht_tmp,MyLength,MPI_INT,id,id,MPI_COMM_WORLD,&status);
}
}
/*递归调用并行排序,对应于算法(1.4,1.5)*/
/*用2^wht_m-1个处理器对wht_start--(wht_r-1)的数据进行递归排序*/
wht_j=wht_r-1-wht_start;
MPI_Bcast(&wht_j,1,MPI_INT,id,MPI_COMM_WORLD);
/*(1.4) para_quicksort(wht_data,wht_i,wht_r-1,wht_m-1,id)*/
if(wht_j>0)
para_QuickSort(wht_data,wht_start,wht_r-1,wht_m-1,id,MyID);
/*用2^wht_m-1个处理器对(wht_r+1)--wht_end的数据进行递归排序*/
wht_j=MyLength;
MPI_Bcast(&wht_j,1,MPI_INT,id,MPI_COMM_WORLD);
/*(1.5) para_quicksort(wht_data,wht_r+1,wht_j,wht_m-1,id+2m-1)*/
if(wht_j>0)
para_QuickSort(wht_tmp,0,MyLength-1,wht_m-1,id+exp2(wht_m-1),MyID);
/*将排序好的数据由处理器id+exp2(wht_m-1)发回id号处理器,对应于算法/
/*(1.6) P(id+2m-1) swht_end wht_data[wht_r+1,wht_m-1] back to Pid */
if((MyID==id+exp2(wht_m-1)) && (MyLength!=0))
MPI_Send(wht_tmp,MyLength,MPI_INT,id,id+exp2(wht_m-1),MPI_COMM_WORLD);
if((MyID==id) && (MyLength!=0))
MPI_Recv(wht_data+wht_r+1,MyLength,MPI_INT,id+exp2(wht_m-1),id+exp2(wht_m-1),MPI_COMM_WORLD,&status);
}
/*串行快速排序*/
int partition(int *array,int p,int r){
int x=array[r]; //以最后一个作为主元(pivot element)
int i=p-1;
for(int j=p;j<r;++j){
if(array[j]<x){
i++;
swap(array[i],array[j]);
}
}
swap(array[r],array[i+1]);
return i+1;
}
void quicksort(int *array,int p,int r){
if(p<r){
int q=partition(array,p,r);
quicksort(array,p,q-1);
quicksort(array,q+1,r);
}
}
/*
* 函数名: main
* 功能:实现快速排序的主程序
* 输入:argc为命令行参数个数;
* argv为每个命令行参数组成的字符串数组。
* 输出:返回0代表程序正常结束
*/
int main(int argc,char *argv[])
{
double wht_dataSize;
int *wht_data;
int *wht_data1;
/*MyID表示进程标志符;SumID表示组内进程数*/
int MyID, SumID;
int wht_i, wht_j;
int wht_m, wht_r;
MPI_Status status;
/*启动MPI计算*/
MPI_Init(&argc,&argv);
/*MPI_COMM_WORLD是通信子*/
/*确定自己的进程标志符MyID*/
MPI_Comm_rank(MPI_COMM_WORLD,&MyID);
/*组内进程数是SumID*/
MPI_Comm_size(MPI_COMM_WORLD,&SumID);
/*根处理机(MyID=0)获取必要信息,并分配各处理机进行工作*/
if(MyID==0)
{
/*获取待排序数组的长度*/
wht_dataSize=SIZE;
wht_data=(int *)malloc(wht_dataSize*sizeof(int));
wht_data1=(int *)malloc(wht_dataSize*sizeof(int));
/*动态生成待排序序列*/
srand(396);
printf("排序前的随机数组为 :\n");
for(wht_i=0;wht_i<wht_dataSize;wht_i++)
{
wht_data[wht_i]=(int)rand();
wht_data1[wht_i]=wht_data[wht_i];
if(wht_i<100)
printf("%d ",wht_data[wht_i]);
}
printf("... ...\n");
}
wht_m=log2(SumID);
/* 从根处理器将数据序列广播到其他处理器*/
/*{"1"表示传送的输入缓冲中的元素的个数, */
/* "MPI_INT"表示输入元素的类型, */
/* "0"表示root processor的ID } */
MPI_Bcast(&wht_dataSize,1,MPI_INT,0,MPI_COMM_WORLD);
/*ID号为0的处理器调度执行排序*/
para_QuickSort(wht_data,0,wht_dataSize-1,wht_m,0,MyID);
wht_end_time=MPI_Wtime();
/*ID号为0的处理器打印排序完的有序序列*/
if(MyID==0)
{
printf("排序后的有序数组为 :\n");
for(wht_i=0;wht_i<wht_dataSize;wht_i++)
if(wht_i<100)
printf("%d ",wht_data[wht_i]);
printf("... ...\n");
/*计算串行时间*/
start_time=MPI_Wtime();
quicksort(wht_data1,0,SIZE-1);
end_time=MPI_Wtime();
printf("并行时间 = %fs\n",wht_end_time-wht_start_time);
printf("串行时间 = %fs\n",end_time-start_time);
printf("加速比为:%f \n", (end_time-start_time)/(wht_end_time-wht_start_time));
}
MPI_Finalize(); //结束计算
}
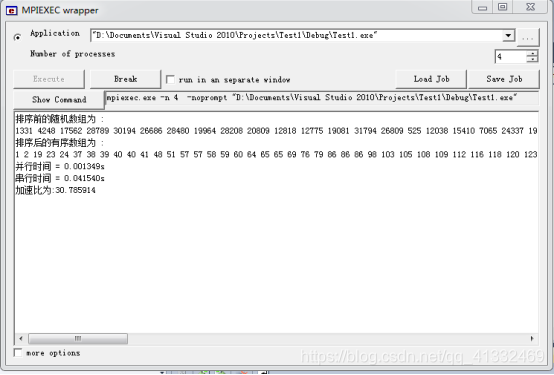
执行结果

汇聚原天河团队并行计算工程师、中科院计算所专家以及头部AI名企HPC专家,助力解决“卡脖子”问题
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)