
Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
相较于推理适配,训练对精度要求更高,且流程更复杂,涉及到前向反向等多个环节,而训练涉及到的算力资源更多,资源调度与通信操作复杂性提升,让训练适配变得难上加难。某头部股份制银行AI Infra团队率先基于Twinkle+昇腾Atlas 800 A3风冷超节点在FSDP2后端上完成了DeepSeek-V4的SFT/LoRA训练适配,实现了一套与FSDP2深度集成的Expert Parallelism(
2026年4月24日,DeepSeek-V4发布。284B到1.6T参数的MoE 模型,混合注意力 CSA/HCA、流形约束超连接 mHC、Hash-MoE 静态路由——DeepSeek-V4不是一个渐进式升级,而是一次架构重构。相较于推理适配,训练对精度要求更高,且流程更复杂,涉及到前向反向等多个环节,而训练涉及到的算力资源更多,资源调度与通信操作复杂性提升,让训练适配变得难上加难。
对于金融等行业的AI Infra团队来说,这个差异尤其关键。监管要求数据不出域,API调用的路走不通。要在自有集群上微调DeepSeek-V4,就必须完整解决MoE分布式训练的一系列工程问题。
某头部股份制银行AI Infra团队率先基于Twinkle+昇腾Atlas 800 A3风冷超节点在FSDP2后端上完成了DeepSeek-V4的SFT/LoRA训练适配,实现了一套与FSDP2深度集成的Expert Parallelism(EP)方案,并启用高效的昇腾NPU融合算子,和针对DeepSeek-V4开发的专属融合算子提升训练吞吐。
一、DeepSeek-V4模型结构适配
DeepSeek-V4 使用了完全自研的 chat template,无法复用 HF 的 apply_chat_template。我们参考官方 encoding_dsv4.py,在 Twinkle 中实现了完整的编码模版。具体的,我们实现了如下的功能:
完整支持三种模式:chat、thinking(标签)、tools(DSML 格式);
DeepSeek-V4特有Tool Calling调用格式支持:解析 DSML 格式的 <|dsml|invoke> 标签;
不同Thinking Mode 支持:包括 reasoning_effort 控制、drop_thinking 策略;
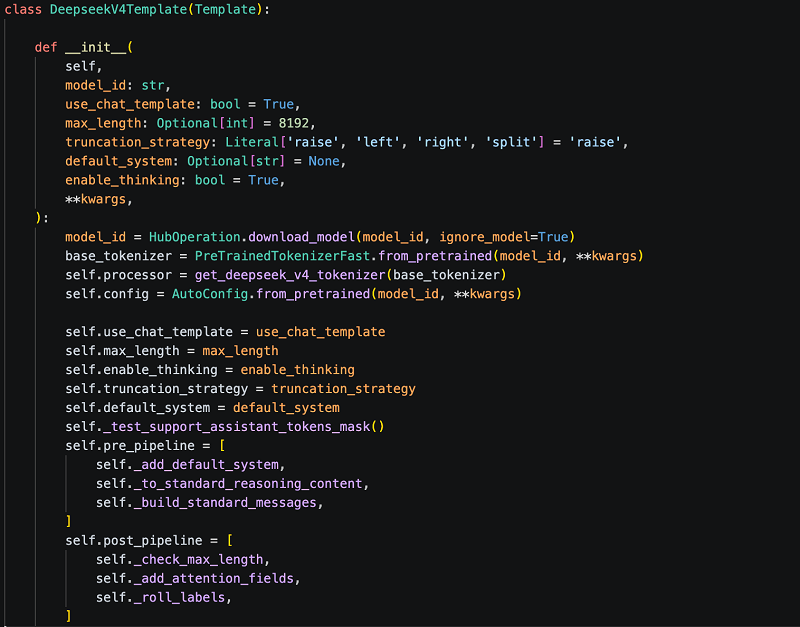
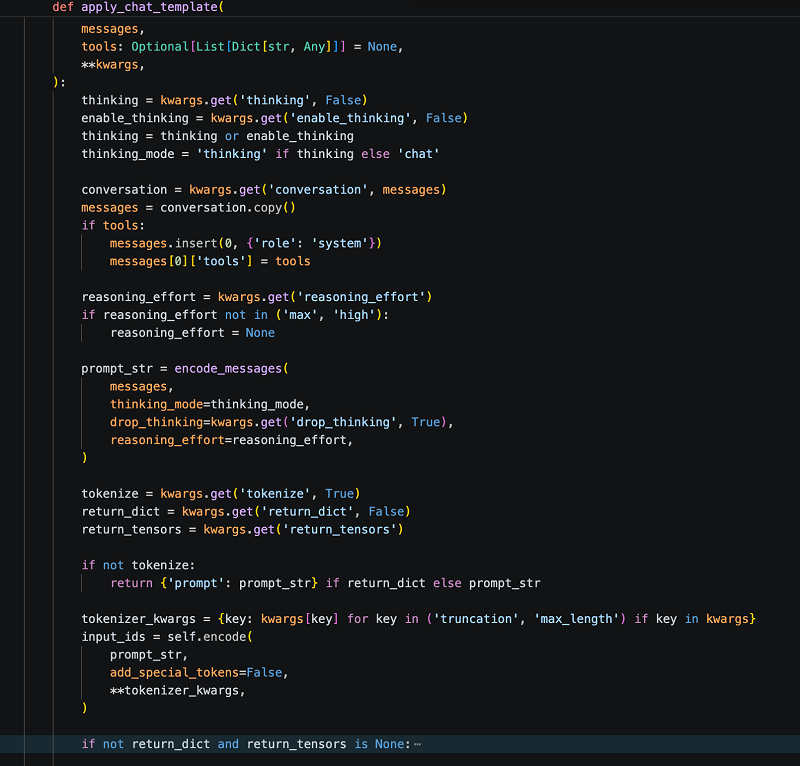
在DeepSeek-V4上做 Agent训练的团队不需要自己处理tool call的编码解码,Twinkle框架通过适配好的模版直接提供。
二、FSDP2-4D并行引擎适配
DeepSeek-V4-Flash的完整模型加载需要超过500GB 显存,单卡无法容纳。分布式训练是唯一的路径。FSDP2(Fully Sharded Data Parallel v2)是 PyTorch 原生的分布式训练方案,通过将模型参数、梯度、优化器状态分片到多张 GPU 上来降低单卡显存占用。
此前我们已经在Twinkle中实现了EP,专家并行(Expert Parallel, EP)的核心思路是:不让每张卡都持有全部专家,而是把专家参数按 EP rank 切分;前向时 router 仍然为每个 token 选择全局 expert id,然后通过 all-to-all 把 token 分发到对应专家所在 rank,本地专家计算完成后再 all-to-all 回收并按 routing weight 合并结果。
本次我们主要在之前FSDP2-4D并行引擎基础上兼容Deepseek-V4 的HashRouter。在 DeepSeek-V4 中,MoE router 有两种形式:普通 TopKRouter 和 HashRouter。当前 EP 适配没有为两者写两套 dispatch 逻辑,而是在 router 接入层做兼容:
对 TopKRouter:router 根据 hidden states 计算 logits,再选择 top-k experts,返回 router_logits / routing_weights / selected_experts 。
对 HashRouter:expert 选择不是动态 top-k,而是通过 tid2eid[input_ids] 查表得到固定 expert id;同时仍然用 gate logits 计算这些专家的 routing weights 。
Twinkle 的 EP patch 会保留 DeepSeek-V4 原生 router 的输出。如果 router 的 forward 支持 input_ids,就把上层传入的 input_ids 透传给 router,因此 HashRouter 可以正常执行 tid2eid[input_ids]。随后,无论 selected experts 来自普通 top-k 还是 hash table,都会被当作全局 expert id 构造 expert_mask,进入统一的 token dispatch 流程。
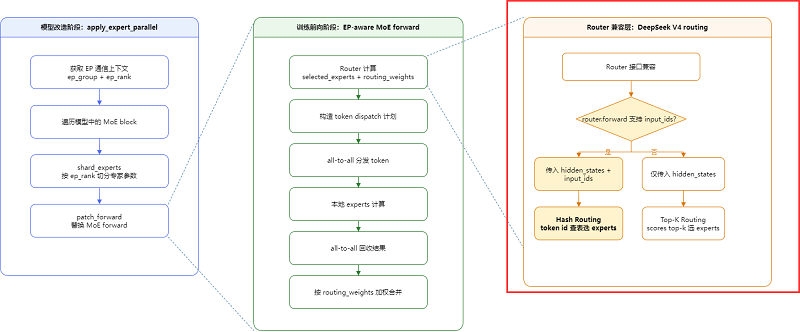
实测在开启ep_fsdp并行策略后,可进一步提升40%的训练效率。
三、显存、内存优化
284B模型的训练,显存是贯穿所有环节的硬约束。Twinkle在显存、内存等多方面展开了优化。
FSDP2 原本的模型初始化假设所有rank执行同样的`from_pretrained`加载。对于 284B 的模型,每张卡如果加载完整的模型权重,那么加载的权重会在占用284*2Gi*world_sized的内存,假设使用16路fsdp2,即8.875TB的内存。
为解决超大模型在 FSDP2 场景下的初始化内存问题,Twinkle 实现了 rank-aware 的模型初始化机制。具体流程如下:

训练启动时,Rank0 负责加载完整预训练权重,其他 Rank 仅基于 config 构建空模型,从而避免所有设备重复加载整份权重带来的巨大内存开销。随后,Twinkle 在 FSDP2 包裹和模型切分完成后,利用 rank0 广播机制将分片权重分发到各个 Rank,并进一步同步非 persistent buffer。最终,每个 Rank 仅持有自身所需的本地模型分片,在显著降低初始化内存占用的同时,完成训练前的模型恢复与对齐。
四、昇腾算力深度适配
为保障Twinkle框架在昇腾平台高效稳定训练DeepSeek-V4,我们联合华为小巧灵团队,基于昇腾Atlas 800 A3风冷超节点完成多维度深度工程适配与性能优化。
1.通用NPU融合算子适配
在NPU算子适配工作中,我们针对昇腾AI处理器的硬件架构特性,重点实现了GEMM(通用矩阵乘法)、RMSNorm(均方根归一化)、RoPE(旋转位置编码)等核心算子的高效迁移与深度优化。通过充分挖掘NPU的并行计算能力与融合指令集,确保计算精度无损的同时实现高效率训练。经过实测,开启NPU融合算子后,整网训练吞吐提升13%+。
2.DeepSeek-V4专属高性能NPU融合算子适配
针对DeepSeek-V4-Flash的Attention核心结构,昇腾CANN设计并实现了4个在训练场景下使用的高性能Ascend C算子,提升核心计算模块的性能并优化显存,Twinkle训练框架深度适配了这4个高性能融合算子。
● LightningIndexer(LI)算子基于一系列操作得到每一个token对应的Top-k个位置,输出Top-k位置的索引,供SparseAttnSharedkv作为输入完成计算。
● SparseAttnSharedKV(SAS)算子旨在完成Attention计算,根据输入cmp_ratio不同支持3种Attention计算,分别为Sliding Window Attention(SWA)、Compressed Attention(CFA)以及Sparse Compressed Attention(SCFA)。
● SparseAttnSharedkvGrad(SASG)是SAS的反向算子,计算过程分为3个阶段。阶段一根据不同cmp_ratio场景,对输入ori_kv与cmp_kv进行选择,阶段二计算P、dP、dS,阶段三计算dQ, dKV, dSinks。
● SparseLightningIndexerGradKLLoss算子,由于LI模块进行Loss计算时存在巨大显存开销(序列的平方级别,需要计算Main Attention score)。SparseLightningIndexerGradKLLoss算子将Main Atttion score计算、LI的反向、以及Loss计算过程融合,减少中间显存占用,优化显存和性能。
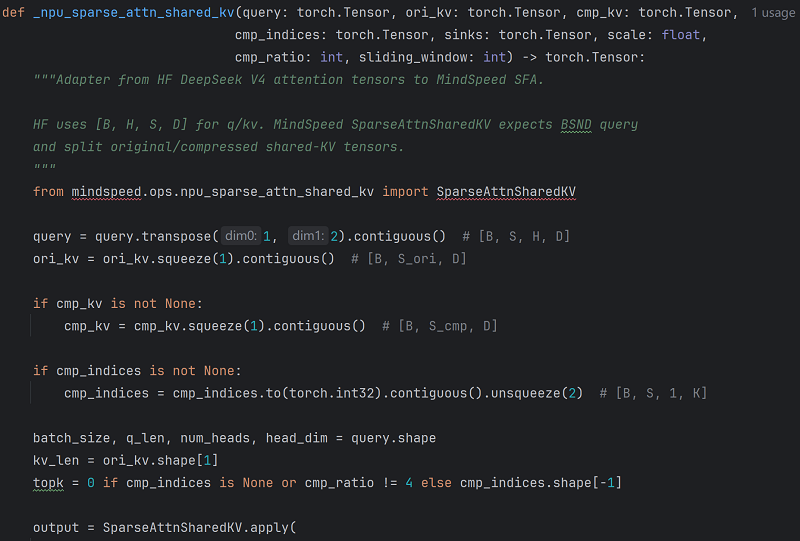
高性能融合算子具体原理和实现可查阅 cann-recipes-train开源仓介绍,预计训练效率提升收益在60%。
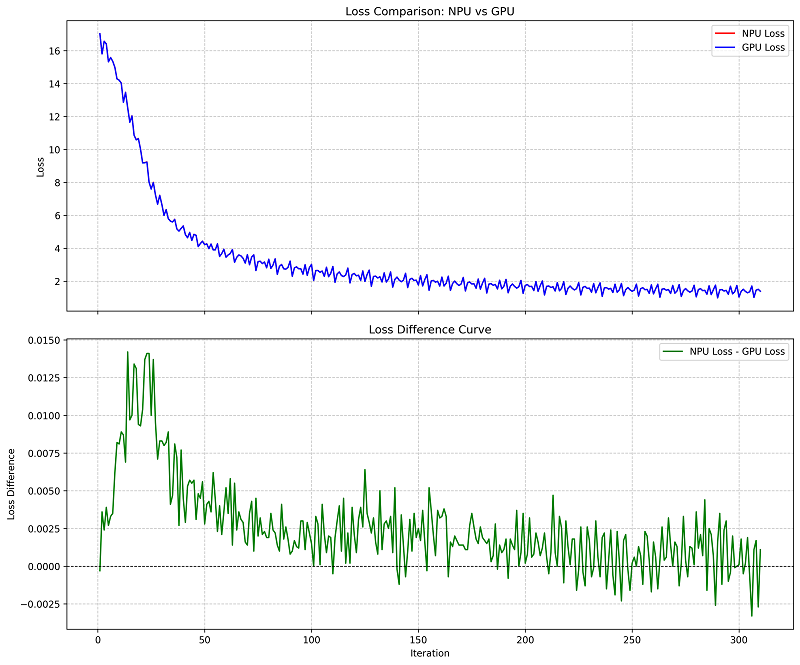
3.适配验证:训练精度对标Loss曲线高度对齐
同时我们还在昇腾上验证了训练适配的正确性和精度。通过与GPU训练的Loss曲线对比,可以看到趋势完全吻合,逐Step Loss差异在千分之一以内,训练可正常收敛。
通过以上适配工作,用户需要4机32卡Atlas 800 A3风冷超节点,使用cookbook中的训练脚本,即可启动DeepSeek-V4系列模型的微调。
五、快速开始
# 环境准备
## 使用构建的镜像
docker pull swr.cn-southwest-2.myhuaweicloud.com/ascend-sact/twinkle-npu:v3
## 从源码安装
git clone https://github.com/modelscope/twinkle.git
cd twinkle
pip install -e .
# 转换 DeepSeek-V4-Flash FP4/FP8 权重为BF16训练格式
git clone https://gitcode.com/cann/cann-recipes-train.git
cd cann-recipes-train/llm_pretrain/deepseekv4/utils
python3 convert_model.py \
--input_fp8_hf_path /data/models/DeepSeek-V4-Flash \
--output_hf_path /data/models/DeepSeek-V4-Flash-BF16 \
--quant_type bfloat16
#A3节点4机32卡训练
ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 \
torchrun --nnodes=4 \
--nproc_per_node=16 \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
cookbook/transformers/deepseek_v4_flash.py
训练过程截图:
参考链接:
https://github.com/modelscope/twinkle
https://gitcode.com/cann/cann-recipes-train
「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
更多推荐

 0
0 0
0- 0



 已为社区贡献3884条内容
已为社区贡献3884条内容

所有评论(0)