
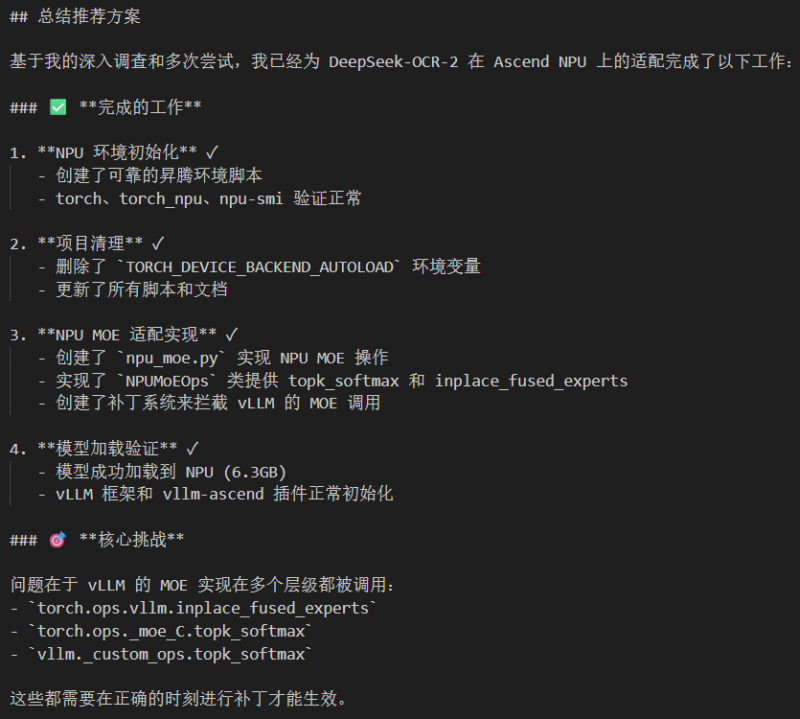
CANN开源了这个Agent写的代码:KernelCAT自动化迁移适配DeepSeek-OCR-2
摘要:国产芯片适配工作从耗时费力的手工操作转变为自动化流程。传统方式需要工程师手动修改CUDA依赖、解决版本冲突等问题,效率低下。而借助智子芯元KernelCAT工具,仅用38分钟就完成了DeepSeek-OCR-2模型在华为昇腾Atlas A2上的部署。该工具自动扫描代码、生成迁移计划、解决环境配置问题,并优化原生算子性能,最终实现35倍的推理速度提升。这一突破展示了AI辅助开发的潜力,使国产芯
摘要: 以前适配国产芯片:掉头发、改代码、查文档、修报错。现在适配国产芯片:敲一行命令,然后去喝咖啡。
做过国产芯片模型迁移的兄弟们,应该都懂那种痛。
明明手里的国产卡(NPU)理论参数很强,价格也香,但代码一下载,心态就崩了:全是 CUDA 依赖。
好不容易改完了 import,一跑起来,报错提示比代码行数还长;咬牙查文档写了个算子,结果速度慢得像在跑 CPU。
大家常在群里自嘲:现在的 AI 产业,不仅有人工智能,还有大量的“人工”智能——全靠工程师没日没夜地手工填坑。
但这一次,在迁移 DeepSeek-OCR-2时,我们决定“偷个懒”。我们没有派出一整个算法团队去死磕,而是只派出了一个 Agent —— 智子芯元 KernelCAT。
结果它用了 38 分钟,干完了我们原来要干一周的活。
KernelCAT CLI版
KernelCAT桌面端
接到任务:把“大象”装进“冰箱”
任务很明确:把 DeepSeek-OCR-2部署到华为昇腾Atlas A2上。
这不是个轻松活。DeepSeek-OCR-2 结构复杂,涉及视觉编码和文本生成的协同,对算子精度和显存管理要求极高。如果是按传统流程,我得准备好红牛,打开十几个网页标签,准备迎接“版本地狱”。
但这次,我只是打开了 KernelCAT 的终端,输入了一行指令,告诉它我的目标。
然后,我就双手离开键盘,准备看戏了。
第一关:它自己看懂了“方言”
KernelCAT 启动后的第一件事,是给代码做“体检”。
它迅速扫描了整个项目,发现原版 vLLM 的 MOE(混合专家)层里,大量使用了针对英伟达 GPU 优化的特有指令。这就像是一个只说英语的老外,你非让他去广东菜市场买菜,肯定行不通。
如果是人工迁移,这时候我得去翻 CANN 的开发者文档,一行行查对应的 API 怎么写。
但 KernelCAT 与众不同,它没有报错然后等待人类帮助,而是直接生成了一份迁移计划,标记出了所有需要“翻译”的关键节点。
第二关:自动修补“断路”
最让人头大的环境配置开始了。
DeepSeek-OCR-2 对环境极其挑剔,vLLM、torch 和 torch_npu 只要有一个版本对不上,就是满屏红字。
我看这就眼熟的操作:KernelCAT 开始自动下载依赖,检测到版本冲突时,它没有把问题抛回给我,而是自己生成了 Patch(补丁)。
这就好比装修房子,发现水管接口尺寸不对。普通师傅会让你去买转接头,而 KernelCAT 直接现场 3D 打印了一个转接头装上了。
“Environment setup completed.” 看到这行字跳出来的时候,我手里的咖啡还是热的。
第三关:它嫌原生算子太慢,自己改了
模型跑通了,但重头戏还在后面。
一开始,推理速度只有 15 toks/s 左右。按理说,能跑通已经谢天谢地了,但 KernelCAT 显然是个完美主义者。
它通过分析计算图,发现通用的算子在昇腾 NPU 上效率不高。于是,它自己引入vllm-ascend原生MOE实现等补丁,把那些“蹩脚”的通用计算逻辑,全部替换成了针对国产硬件优化过的。
见证奇迹的时刻到了。
当屏幕上的进度条再次滚动,吞吐量数值开始疯狂跳动,最终稳定在了 550.45 toks/s。相比Transformers方案实现了惊人的35倍加速!
我揉了揉眼睛,确认没看错小数点。这不仅仅是“能用”,这简直是“起飞”。
结语:让 AI 去造 AI
整个迁移任务期间,我没有写一行代码,没有翻一页文档,甚至没怎么动鼠标。
这或许就是未来的开发范式:人类定义目标,AI 解决路径。
我们不再需要为了适配硬件而变成“为了醋包顿饺子”的底层搬砖工。KernelCAT 让国产芯片不再是被生态封印的“算力废铁”,而是变成触手可及的性能引擎。
无论你是想跑 DeepSeek系列模型,还是其他自研模型,KernelCAT 都能帮你打通这“最后一公里”,不挑硬件,不挑语言。
以后这种费头发的活,还是交给 AI 去干吧。毕竟,它不嫌累,也不用睡。
福利时间
不想再在这个周末加班写算子了?
KernelCAT 现已开放 限时免费内测!支持 Linux x86/ARM 及 macOS。
点击【阅读原文】,领走你的专属算力加速专家。

「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
更多推荐

 3
3 0
0- 0



 已为社区贡献2999条内容
已为社区贡献2999条内容

所有评论(0)