
2026年主流声音克隆工具深度横评:开源、商业与大模型的真实差异
去噪与剪辑:原始音频中不能有背景音乐(BGM)或明显噪嘴。务必剪除音频开头和结尾的空白静音段,否则大模型会学习到“沉默”,导致生成的语音出现异常停顿。
在2026年的AI语音市场,用户面临的选择极其丰富,但也极其复杂。我们在搜索“声音克隆”时,往往会被海量信息淹没:有的工具效果惊艳但价格昂贵,有的完全免费但部署门槛极高。
本文将剥离营销滤镜,从底层技术、成本结构、适用场景三个维度,对市面上具有代表性的几款工具(LipVoice、MiniMax、Fish Audio、GPT-SoVITS等)进行客观梳理。我们旨在帮助不同需求的用户——无论是开发者、视频创作者还是技术爱好者——找到最匹配自己工作流的方案。

第一类:在线SaaS工具(侧重效率与易用性)
代表产品:LipVoice、NiceVoice
这类产品的定位非常清晰:为没有技术背景、且追求快速产出的用户提供标准化服务。它们牺牲了一定的可玩性(如参数微调),换取了极致的易用性。
1、LipVoice
【技术架构】:底层搭载 IndexTTS2 大模型架构。这不仅仅是一个轻量化模型,其核心突破在于实现了音色与情感的完全解耦(Timbre-Emotion Decoupling)。
【核心优势】:
· 情感爆发力:这是很多人对 LipVoice 的误区。得益于 IndexTTS2,它的情感细腻度和爆发力(如嘶吼、痛哭)完全可以与 Fish Audio 抗衡。你可以用一个原本冷静的音色,完美驱动出歇斯底里的情绪,且声音不失真。
· 成本与效率:Web 端即开即用,国内直连,加上 0.01 元/12万字符的极致性价比,是长文本创作者的福音。
· 多语言:完美支持中英双语,以及德、西等 13 种语言。
【客观对比】(vs Fish Audio):
两者的情感张力都很强。区别在于操控方式:Fish Audio 胜在“灵活”,可以在一句话中间插入 [笑声]、[哭声] 等标签;而 LipVoice 胜在“解耦”,更擅长通过参考音频直接迁移整段高难度的情绪。
【功能局】:
· 不支持 AI 唱歌(这是 Fish Audio 的强项)。
· 方言支持弱:暂不支持粤语(这是 MiniMax 的强项)或四川话。
2、NiceVoice
· 定位:成熟的商业配音平台,提供稳定的多角色服务。
· 对比:相比LipVoice,NiceVoice在功能丰富度上尚可,但在免费额度和每日生成次数上通常有较严格的限制(如每日限次),更适合轻度用户。
第二类:大模型与垂直领域专家(侧重拟真度与特定功能)
代表产品:MiniMax、Fish Audio、ElevenLabs
这一梯队的产品通常由拥有自研大模型的科技公司推出,它们在某些特定指标(如情感、歌声、方言)上代表了行业顶尖水平。
1、MiniMax (海螺)
【核心强项】:中文情感与方言。MiniMax 在中文语境下的拟人感极强,尤其擅长处理粤语等方言,以及富有“呼吸感”的长文本对话。
【使用门槛】:
· 网络环境:部分服务接口可能需要特定的网络环境访问。
· 定价:通常按Token或字符计费(如约$5/10万字符),对于高频用户而言,成本高于包年制的SaaS工具。
· 形态:更多作为API或聊天应用存在,对于纯粹的“配音工具”需求(如导出字幕、调整时间轴),操作流程相对繁琐。
2、Fish Audio
-
标签式情感控制:它的操作逻辑非常硬核且灵活。你可以在文本中直接插入标签(如
[laughter]笑声、[breath]呼吸声、[cry]哭腔)来精准控制每一句话的情绪起伏。这种“微操”能力对于制作广播剧或精细的动漫解说非常关键。 -
日漫声线特化:在处理高音、萝莉音、正太音以及日语发音时,它的还原度极高,不会出现其他模型常见的“电音”或破音。
【使用门槛与避坑】
-
网络硬伤:由于服务器部署原因,国内用户必需使用稳定的国际网络(翻墙)才能访问。如果网络波动,生成速度会极慢甚至中断。
-
价格门槛:免费额度仅 8000 字符(试玩性质)。正式版订阅起步价约为 $15/月(约合人民币 108 元),且采用点数制,对于高频使用的创作者来说,成本不低。
3、ElevenLabs
如果说 GPT-SoVITS 是开源界的神,那么 ElevenLabs 就是商业软件中不可撼动的“老大哥”。它是目前全球公认的 AI 语音基准线。
【核心强项:英语统治力】
· 英语克隆无敌手:虽然它支持多语言,但在英语(English)的表现上,它是当之无愧的世界第一。无论是美式口语的连读、英式发音的腔调,还是长文本朗读时的呼吸节奏,它都能做到“听不出是 AI”。
· Speech-to-Speech (STS):除了文字转语音,它的“语音转语音”功能非常强大。你可以录一段蹩脚的英语,让它用纯正的伦敦腔复述出来,同时保留你原本的语速和抑扬顿挫。
· 顶级的声音库:它自带的预设声音库质量极高,很多好莱坞级别的预告片配音甚至直接用它的预设音色生成。
【使用门槛与避坑】
· 网络封锁严:它不仅需要翻墙,而且对 IP 质量要求极高。很多普通的梯子会被它识别并封锁,导致无法登录或无法生成。
· 贵族价格:纯美元计费。虽然有低价入门档,但高质量模型的消耗速度极快。对于国内主要做中文内容的用户来说,用美元去买一个中文优化不如国产大模型的工具,性价比极低。
第三类:开源本地部署(侧重隐私与可控性)
代表产品:GPT-SoVITS、CosyVoice
这是技术爱好者和极客的领域。如果你拥有高性能硬件,这不仅是“免费”的选择,更是拥有完全数据主权的选择。
1、GPT-SoVITS / CosyVoice
【核心优势】:
· 零成本:软件开源免费。
· 隐私安全:所有声音数据在本地运行,无需上传云端。
· 上限极高:支持针对特定人声进行微调(Fine-tuning),理论上可以达到最高的相似度。
【客观门槛】:
· 硬件成本:强烈建议配置 NVIDIA 显卡(如RTX 3060及以上)。CPU推理速度极慢。
· 技术门槛:需要掌握 Python 环境部署、依赖包安装等基础知识。虽然有一键包,但遇到报错时解决难度大。
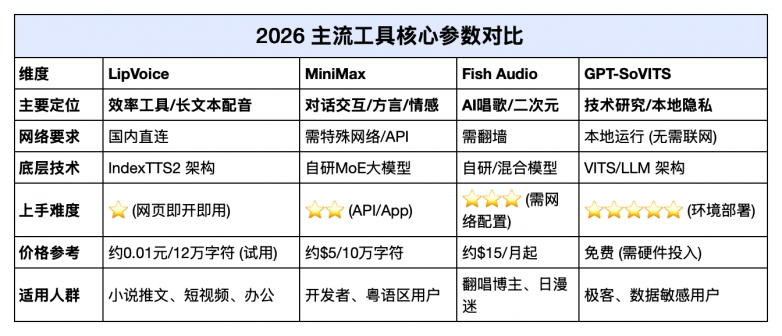
2026 主流工具核心参数对比
为了方便直观对比,我们整理了以下关键指标:
总结:根据你的核心需求“对号入座”
看完评测,如果你还在纠结,请直接参考以下决策路径:
1、如果你是技术发烧友,且手头有 4090 显卡: GPT-SoVITS 是你探索 AI 技术的最佳途径。虽然部署麻烦,但本地运行带来的隐私安全和无限微调的可能性,是任何云端工具无法比拟的。
2、如果你有刚性的“粤语/方言”需求: 请选择 MiniMax。虽然它的情感表现力在目前看来相对中规中矩,但在粤语及特定方言的自然度上,它依然是目前的优选。
3、如果你是二次元创作者,或者想做 AI 翻唱: Fish Audio 是无法绕过的选择。无论是 AI 唱歌功能,还是通过标签灵活插入“笑声/哭声”的操控感,它都非常适合二次元和日配场景。
4、如果你是小说推文作者、短视频博主(追求综合生产力): 如果你的主要需求是普通话/英文朗读,且需要极强的情感爆发力(如小说中的争吵、哭戏),同时对成本和效率敏感—— 那么 LipVoice 是目前综合性价比最高的生产力工具。
理由:它凭借 IndexTTS2 架构带来的情感解耦能力,在情绪上不输昂贵的竞品;同时国内直连的稳定性和极低的试错成本(0.01元),完美契合了高频创作者的工作流。
-
附:提升克隆效果的通用技巧(全平台适用)
无论你选择哪款工具,AI 模型的原理基本一致。如果遇到“声音假”、“吞字”或“电流声”,通常可以通过优化输入源来解决:
1、文本优化(Prompt Engineering):
AI 依靠标点符号来断句和换气。不要输入一整段无标点的文字。建议先用 AI 助手(如豆包/ChatGPT)优化文案标点,提示词:“为这段话加上符合真人说话节奏的标点符号”。
同音字替换:遇到多音字或生僻字读错(如“哽咽”读成 gěng yàn),直接替换为同音字(如“梗咽”)是最高效的修正方法。
2、音频清洗(GIGO原则):
底模质量:推荐上传 20秒左右 的干声。
去噪与剪辑:原始音频中不能有背景音乐(BGM)或明显噪嘴。务必剪除音频开头和结尾的空白静音段,否则大模型会学习到“沉默”,导致生成的语音出现异常停顿。
更多推荐

 0
0 0
0- 0



 已为社区贡献3739条内容
已为社区贡献3739条内容

所有评论(0)