
Windows 10下Docker使用经验谈
最近一直在开发Apworks框架的案例代码,同时也在一起修复Apworks框架中的Bug和一些设计上的不足。遇到的一个普遍问题是,代码的调试过程需要依赖很多外部系统,比如MongoDB、PostgreSQL、RabbitMQ等。当然可以在本机逐一安装这些服务,然后对服务进行配置,使其满足自己开发调试的需要。这样做当然是没有问题的,只是比较麻烦。于是,我寻求docker的帮助,将服务全都运行在doc
最近一直在开发Apworks框架的案例代码,同时也在一起修复Apworks框架中的Bug和一些设计上的不足。遇到的一个普遍问题是,代码的调试过程需要依赖很多外部系统,比如MongoDB、PostgreSQL、RabbitMQ等。当然可以在本机逐一安装这些服务,然后对服务进行配置,使其满足自己开发调试的需要。这样做当然是没有问题的,只是比较麻烦。于是,我寻求docker的帮助,将服务全都运行在docker容器中,需要的时候一条简单的docker命令即可启动,不需要的时候,将docker容器停掉即可,非常方便,而且不会对主机环境造成干扰。当然,实践过程也不是那么顺利的,也踩了一些坑,现在就跟大家分享一下。
Docker for Windows 10
在Windows 10系统下的首选就是Docker for Windows 10。Docker对Windows 10的支持现在已经做得非常好了,无论在Windows Command下还是在Windows Powershell下都可以执行Docker命令,也可以像在Linux系统下一样,运行所有的Docker容器。对Docker架构了解的读者一定能够更好地了解Docker for Windows 10运作的基本原理,即在Hyper-V的支持下,将Docker容器运行在Linux的虚拟机里。因此,在Docker for Windows的工具中,可以设置这台虚拟机的CPU个数,以及内存的大小。
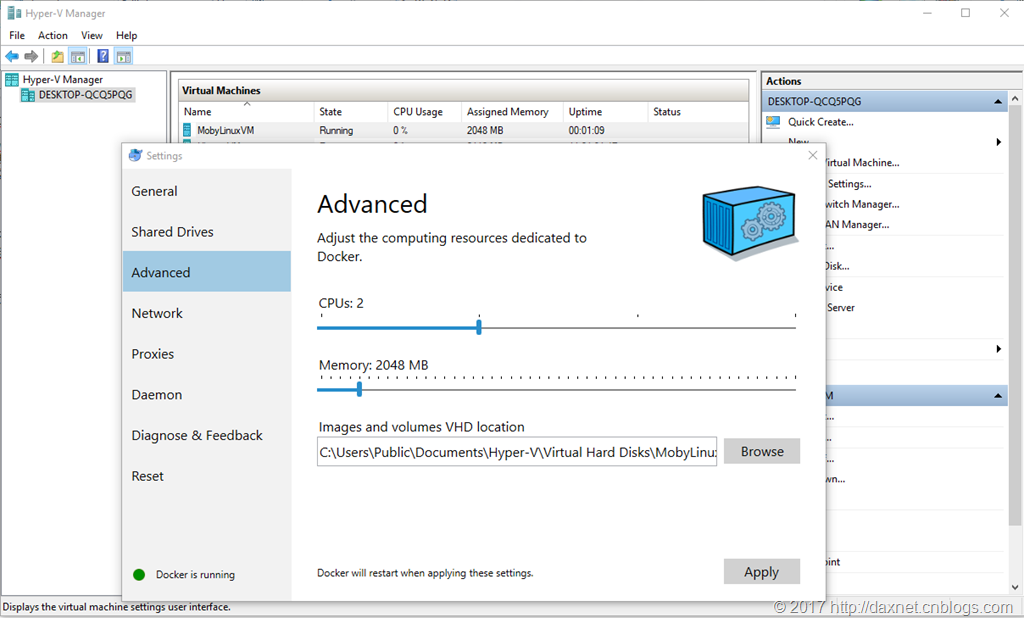
然而,一个比较麻烦的问题是,如果你需要使用-v参数来加载(mount)一个磁盘目录(volume)的时候,就会出现问题,至少我在MongoDB中使用-v参数来将MongoDB的数据文件映射到主机目录时,就会导致MongoDB无法正常启动。这个问题在Hyper-V出现之前,在Virtual Box时代就有,而且根据社区的讨论,似乎在Hyper-V的版本中也还是没有解决。详细信息可以参考这里:https://stackoverflow.com/questions/42756776/how-do-i-configure-mongo-to-run-in-docker-to-using-an-external-drive-on-windows。
由于这样的原因,我没有在自己的开发环境中使用Docker for Windows 10,因为无法将MongoDB的数据库文件映射存储到主机(Host Machine)上,也就意味着每次启动容器执行我的一些冒烟测试(Smoke Test),我都需要重建数据,非常麻烦。我选择了在Hyper-V中搭建自己的Linux虚拟机来构建自己的开发和测试环境。
使用Hyper-V的Linux虚拟机来运行Docker容器
以前,只有服务器版本的Windows才支持Hyper-V,记得最早支持Hyper-V的Windows是Windows Server 2008。说起Hyper-V的历史,也是有一定渊源的。最早有一家公司,名叫Connectix,它有一款产品就是大家熟悉的Connectix Virtual PC,一款硬件虚拟化产品,后来Connectix把Virtual PC产品卖给了微软,成为了Microsoft Virtual PC,之后Connectix于2003年宣布解体,微软把Virtual PC精神发扬光大,成就了现在的Hyper-V。从Windows 10开始,Professional/Enterprise版本的Windows 10都能够支持Hyper-V了。大家可以直接在Windows 10中创建虚拟机,而不需要额外安装vmware player、Oracle VirtualBox等这些第三方的虚拟机服务。
启用Hyper-V的方法非常简单,在Windows 10中,点击开始菜单,或者按下键盘上的WIN键,然后输入关键字windows features,这时会出现“Turn windows features on or off”菜单项(我的系统是英文版,中文版稍作修改):

点击这个菜单项,然后会打开大家熟悉的控制面板界面,直接选中其中的Hyper-V就行了:
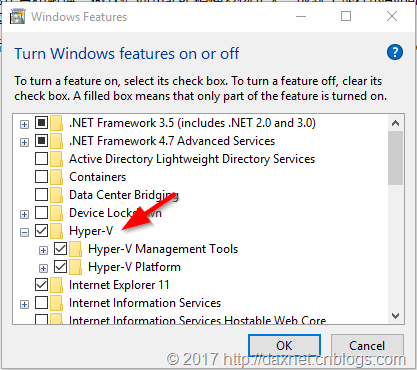
应用更改并重新启动后,Hyper-V就已经装好了。需要注意的是,如果你已经在控制面板中启用了Hyper-V,那么假如你再安装Oracle VirtualBox的话,这样Oracle VirtualBox仅可创建32位的虚拟机。当然原因我们也没必要深究了。
Hyper-V成功安装后,同样,在开始菜单中输入Hyper-V作为关键字,Hyper-V Manager菜单项就会显示出来,点击Hyper-V Manager的菜单项,即可打开Hyper-V的管理界面。在Hyper-V Manager中,可以非常方便地创建并管理虚拟机,虚拟机的操作系统可以是Windows的,也可以是Linux的,用户只需要下载所需操作系统的ISO镜像即可完成安装,非常方便。这部分内容本文就不多说了,可以参考微软官网Hyper-V的教程。
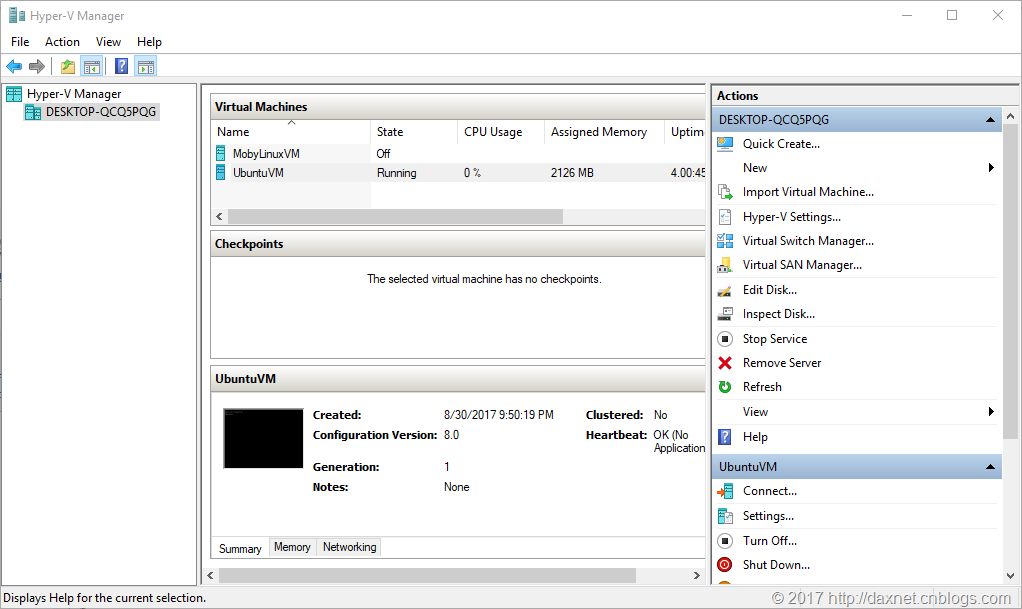
比较有趣的事情是,Hyper-V对虚拟机的内存分配可以是动态的。比如我在创建Ubuntu Linux虚拟机的时候,选择的是8GB的内存,但从上图可以看出,目前系统仅分配了2GB多一点的内存给我的虚拟机,因为当时它只需要使用这么多。这样也能兼顾到主机的性能。在我创建的这个Ubuntu Linux虚拟机中,我配置使用了静态IP地址,这是为了方便程序的开发测试。在我的测试数据中,我不需要因为虚拟机IP地址的改变而总是去修改数据库的连接字符串。配置静态IP的另一个好处就是,你可以很方便地使用Putty这样的SSH工具来远程连接到Hyper-V虚拟机,而不需要每次都打开Hyper-V Manager并登录到虚拟机控制台。Putty这套工具使用非常方便,并且绿色轻量,在此强烈推荐。
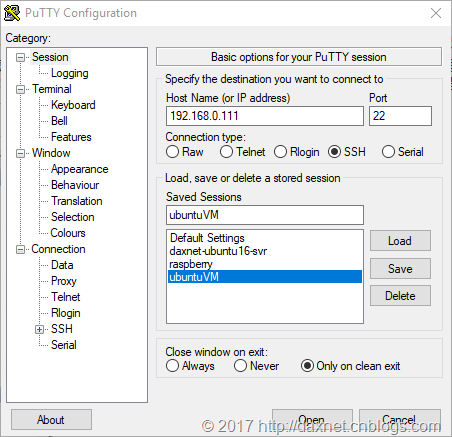
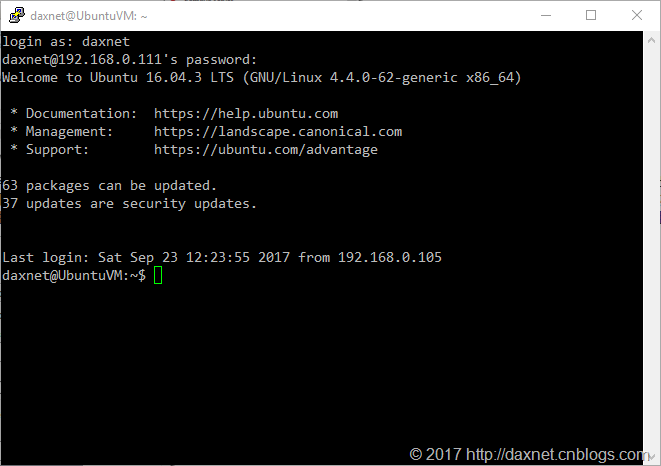
根据不同的Linux环境,静态IP地址的配置方式也会不同,这里也不多解释了,网上相关的文章还是很多的。
另一个比较头疼的问题就是,在国内通过Docker Hub下载Docker镜像是非常慢的,慢到你无法忍受,其中原因大家都心知肚明。一个解决方案是在Docker CE的配置文件中设定本地的Docker Registry镜像链接,比如可以使用阿里云提供的链接地址。此时,需要登录阿里云并创建一个个人账号,然后按照https://yq.aliyun.com/articles/29941一文中的介绍,登录容器Hub服务的控制台,然后点击“Docker Hub镜像站点”,拷贝专属加速器地址然后配置到/etc/docker/daemon.json文件中即可。具体方法可以按照上面的链接做。
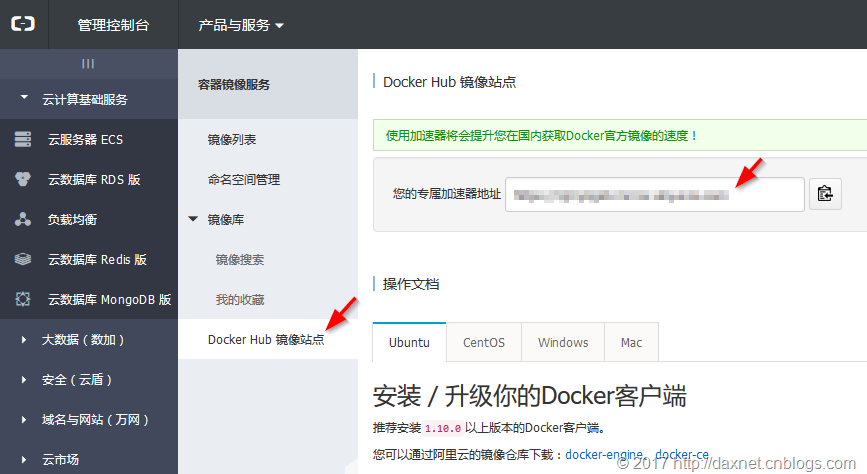
在配置好镜像地址并重启之后,使用docker pull、docker run等命令就会非常快了,大家不妨一试。对于Docker for Windows,你需要打开设置界面,然后在Daemon页中的Registry mirrors部分,填入镜像链接地址即可。
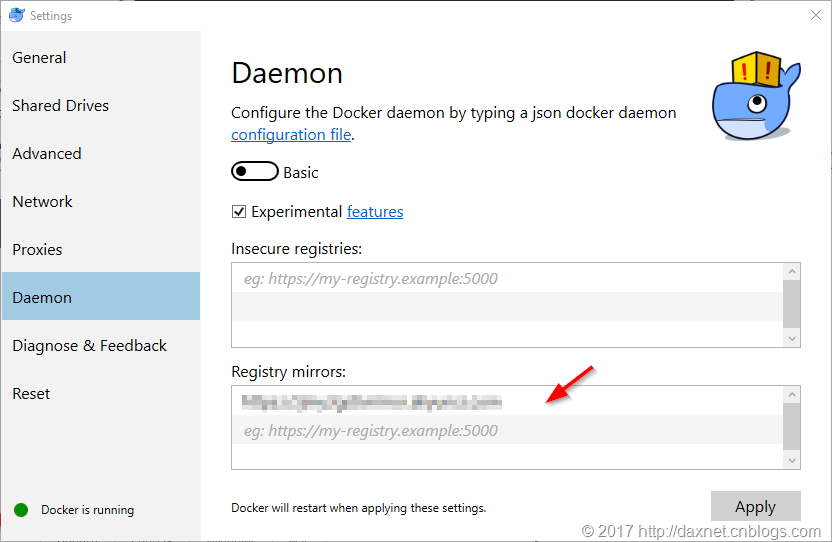
或许你会问,安装和配置Docker用于搭建自己的开发和测试环境并不容易,我为何不自己在本机装我所需的数据库、消息队列、缓存等服务,而去弄个Docker来运行这些基础服务呢?我想,驱使我这么做的原因大概是如下几点吧:
- 如果我的应用程序所依赖的基础服务比较多的话,在开发机器上逐一安装这些服务是比较耗时的,而且我很难针对不同版本的服务进行测试。使用Docker可以很方便地在基础服务版本之间进行切换,比如可以使用Docker镜像的tag来指定我所需要的MongoDB的版本
- 使用Docker,使得基础服务环境搭建可以被复制。例如我可以使用一个批处理脚本(或者Shell脚本)将运行Docker容器的命令写入,那么无论我在哪台机器上,只要能够运行这个批处理脚本,都可以一键搭建基础服务环境,无需更多操作。由docker-compose支持的部署方式使得基础服务的部署变得更加简单,也就是当我的应用程序准备上线时,我只需要将我的docker-compose YAML文件上传到Docker Orchestrator上,由其负责管理和运行相关的容器即可
- 在Hyper-V托管的虚拟机中运行Docker容器,可以更好地利用和分配主机资源,在不需要的时候可以将主机性能损耗降到最低。目前硬件价格都不算昂贵,运行一个4GB内存的虚拟机并不是那么吃力。此外,Hyper-V的关机选项允许在主机关闭的时候,让虚拟机处于休眠待机状态,而在主机运行时又按需唤醒虚拟机,因此,每次开机,基础服务都是正常运行状态,你只需要直接运行你的应用程序即可
下面我简单介绍一下docker-compose工具。
Docker-compose简介
Docker-compose听起来像是一个由YAML语法定义的文本文件,通过docker-compose命令行解释执行。在docker-compose.yml文件中,你可以编辑你需要运行的Docker容器(称之为服务),以及这些服务之间的依赖关系。Docker-compose可以很好地帮你维护这些服务的生命周期。在Docker for Windows中,docker-compose是被默认安装的,你可以通过--version参数来查看安装的版本:
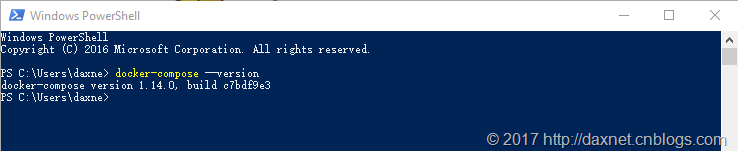
而对于运行于Hyper-V托管的Linux中,docker-compose需要单独安装。安装方法请参考:https://docs.docker.com/compose/install/。推荐使用1.13.0以上的版本,新版本对Compose file 3.0的支持会比较好。
举个例子,在我自己开发的Apworks框架中,我使用如下docker-compose.yml来定义我的基础服务运行容器:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
这个docker-compose.yml文件中指定启动三个容器:MongoDB、PostgreSQL以及RabbitMQ,分别定义成了三个服务(service)。这个compose文件还是比较简单的,没有牵涉到容器之间的依赖关系。我只需要在这个文件所在目录中,执行下面这条命令,即可同时启动这三个服务:
sudo docker-compose up非常方便。启动结果如下:
还可以在docker-compose命令中加入-d参数,使得所有服务在后台运行。有关Compose文件的格式定义,请参考:https://docs.docker.com/compose/compose-file/。在工作中我们也使用了docker-compose帮助用户搭建他们自己的微服务环境,我们分发给用户的仅仅是一个docker-compose.yml文本文件,一旦运行,所有的基础服务容器都会运行起来,用以为前台的数据分析系统提供服务保障。
总结
本文介绍了我在Windows 10系统下使用Docker来帮助开发和测试的一些经验和感受。Docker是一个非常好的东西,对于系统的部署和运维有很大的帮助,并且它是云友好的,有着全球各大云服务供应商的支持,能够很方便地部署并运行在云环境中。今后我还会介绍一下Azure下Docker容器的支持和使用,欢迎大家各抒己见,分享自己的使用经验。
博客链接,侵联删ttp://sunnycoding.cn

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)