ache Kafka 的# 事件排序
关于代理
代表是一个数字平台,通过向企业扩展网络和融资来促进支付。当您通过 Behalf 进行销售时,可增加收入并在下一个工作日获得报酬*。
在一系列文章中,我们揭示了我们的事件驱动微服务之旅。
排序问题
走出单体应用的舒适区,进入事件驱动微服务的荒野,你会意识到我们认为有多少事情是理所当然的。例如,事物的自然秩序。
在 Monolith 中,我们不必考虑订购那么多。现在跨越多个微服务的许多操作可以在一种方法中完成,其中语句的顺序决定了执行的顺序。或者我们可以使用锁定 - 悲观或乐观(甚至是单个实例单体中的 JVM 锁定)。微服务上的全局锁定是一个糟糕的想法,因为它会产生我们试图避免的那种紧密耦合。
部分订购
在Set Theory中,我们区分了总顺序(所有元素都有前后关系)和部分顺序(只有元素的子集有关系)。当查看我们系统中所有事件的集合时,如果我们可以识别我们的事件之间的部分顺序,我们只需要注意这些事件之间的排序。
[ <br>
<br>
l 订购](https://res.cloudinary.com/practicaldev/image/fetch/s--X5ZQyEL7--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads.s3.amazonaws .com/uploads/articles/6kkjxi4j52m4hq6eby68.jpeg)](https://res.cloudinary.com/practicaldev/image/fetch/s--X5ZQyEL7--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/uploads/articles/6kkjxi4j52m4hq6eby68.jpeg)
例如,与客户 A 相关的事件必须在它们之间按顺序排列——我们不能允许客户在客户注册之前提交交易,并且我们不希望在处理 CustomerChangedBank 事件之前处理 TransactionSubmitted 事件。但是,这些事件都与客户 B 上的事件无关。
使用 Apache Kafka 的订购保证
我们选择 Kafka 作为我们的事件总线的原因有很多——它耐用、可靠、可扩展、拥有强大的生态系统以及对 Java 和 Spring Boot 的支持。它带有订购保证。它在Confluent Kafka Definitive Guide中有描述:
“Apache Kafka 保留分区内消息的顺序。这意味着如果消息以特定顺序从生产者发送,代理将按该顺序将它们写入分区,所有消费者将按该顺序读取它们。”
因此,使用 Kafka,我们可以获得部分排序 - 在单个主题中的单个分区上。我们需要选择一个主题拓扑来表示我们在系统中识别的部分订单。
注意 - 要获得严格的排序,需要禁用生产者重试(不推荐)或将属性max.in.flight.requests.per.connection设置为 1。这在文档中进行了解释。
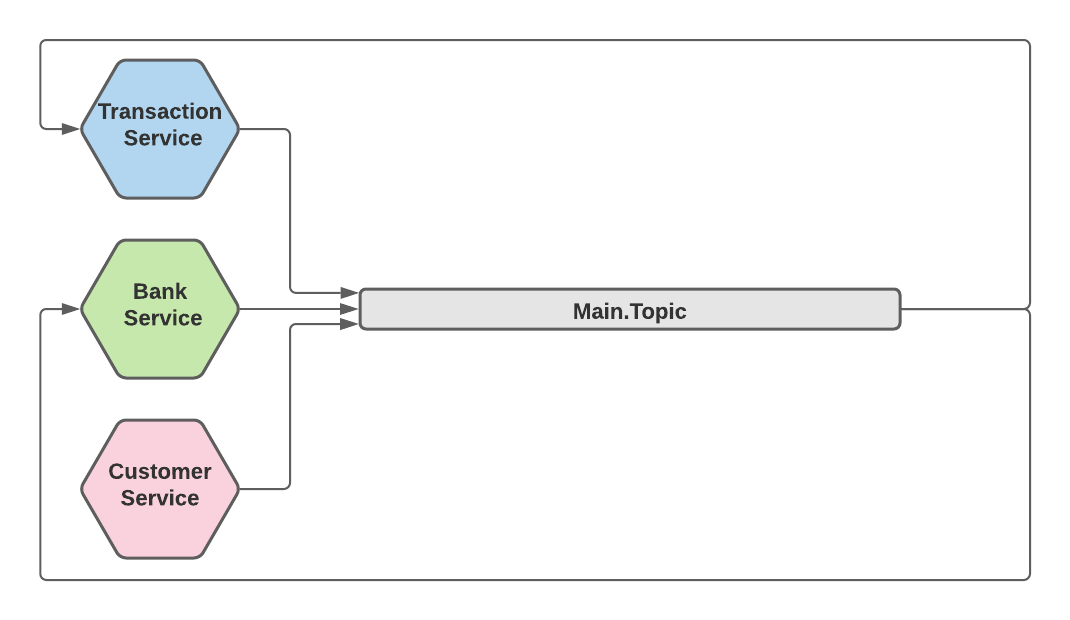
每个事件类型的主题
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--3NS8svi---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https: //dev-to-uploads.s3.amazonaws.com/uploads/articles/6apvrqh0k8ey1ptz1req.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--3NS8svi---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https: //dev-to-uploads.s3.amazonaws.com/uploads/articles/6apvrqh0k8ey1ptz1req.png)
使用此拓扑,我们将为每种事件类型创建一个主题。这是一种非常常见的拓扑结构,通过阅读各种教程和指南,您可能会得出错误的结论,即这是 Kafka 的“最佳实践”。事实上,这种拓扑结构有很多好处:
-
消费者可以根据需要处理的事件选择订阅哪个主题。这减少了不需要的事件的“噪音”。
-
它使得强制事件模式变得容易,因为一个主题中的所有事件都具有相同的模式。从历史上看,Confluent Schema Registry 要求每个主题有一个模式。随着 Conluent 5.5 版中Schema Reference的引入,这种情况发生了变化。
-
结合日志压缩,这是在 Kafka 中存储价值的好方法,类似于 DB 记录。 Kafka 每个实体 id 只会保存一条记录,这样可以节省存储空间并减少访问时间。这在我们的案例中不是很有帮助,因为业务事件不受修改。
但是,在排序方面,这种拓扑不是很有帮助,至少在我们的用例中没有。它只会让我们对特定的事件类型进行排序,这不是我们需要的。
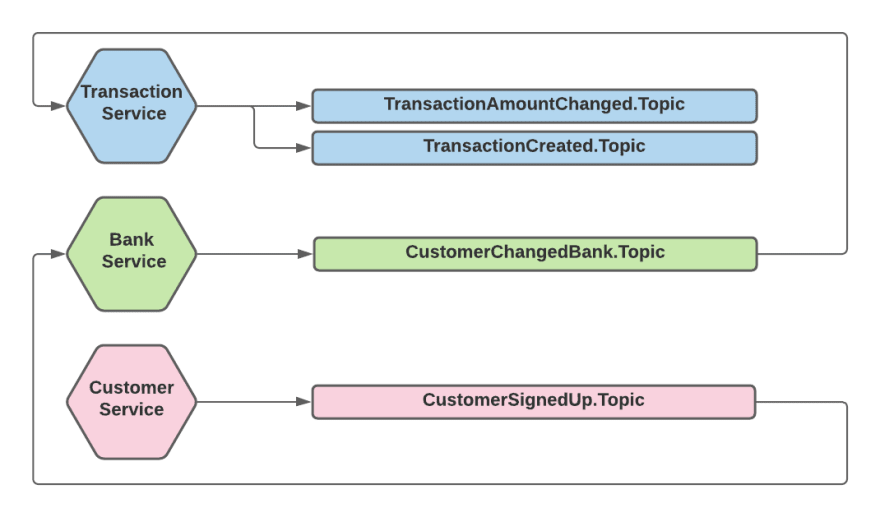
主题作为提要
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--lyunRGkd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/uploads/articles/33dd3rminec0ppbuiaru.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--lyunRGkd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/uploads/articles/33dd3rminec0ppbuiaru.png)
我们考虑的下一个拓扑是让每个服务将其所有事件发布到一个主题 - 服务“订阅源” - 以便订阅者可以订阅以便从该服务获取“最新消息”。这与Atom 提要,但使用 Kafka 实现。这种拓扑的好处:
-
生产者服务运营成本更低——只需要管理单个主题,引入新事件类型时无需创建新主题。
-
虽然与“Topic Per Event Type”拓扑相比,我们这里的噪音更大,但至少订阅者可以选择收听哪个服务,并且他们不会从他们不关心的服务中获取事件。
就排序而言,这在许多情况下可能就足够了,但它对我们的用例没有帮助,在这种用例中,同一流的一系列事件可以跨越微服务。
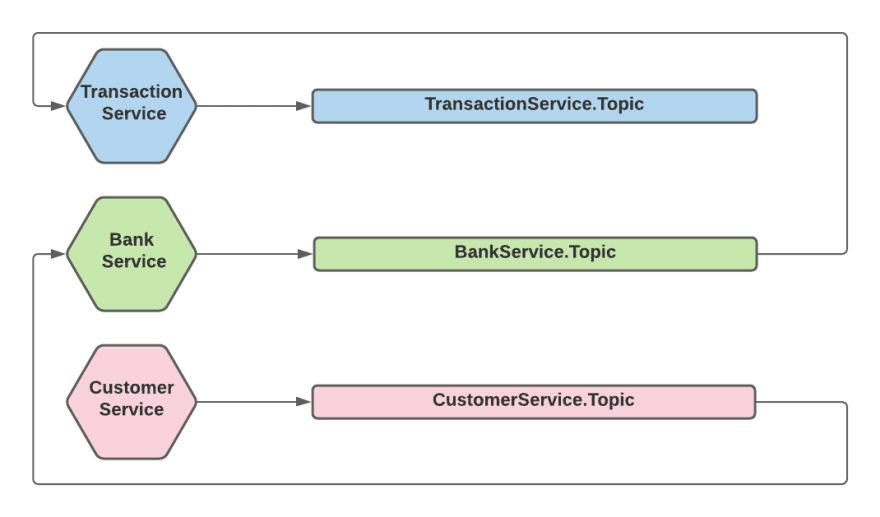
话题如流
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--qgXpAokd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/uploads/articles/la06d2sxivkh6j5rvqcx.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--qgXpAokd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/uploads/articles/la06d2sxivkh6j5rvqcx.png)
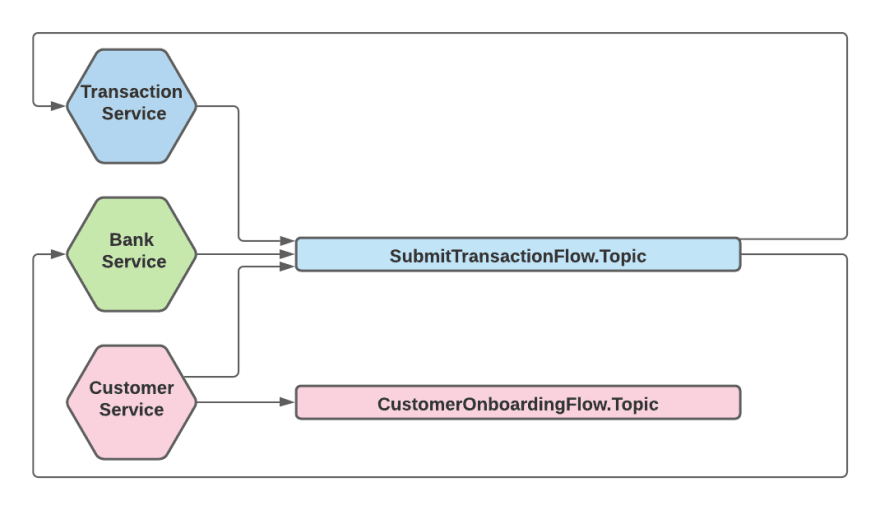
更细粒度的方法是创建几个代表已知流的主题。例如,在我们的案例中,我们会将事件发送到“SubmitTransactionFlow”主题,但其他事件可以发送到“CustomerOnboardingFlow”主题。让我们比较一下这种方法:
-
它显然比“Topic Per Event Type”方法更嘈杂,但不一定比“Topic As Feed”方法更嘈杂。这取决于流的粒度以及订阅者对流的参与程度——订阅者可能只关心该流中的单个事件,但必须监听所有事件。
-
运营成本——我们不需要为每个事件创建一个主题,但我们确实需要为每个流创建一个主题,因此除非我们有少量且一致的流,否则不会有太大的改进。
在我们的特定用例中,它将解决排序问题。
当系统变得越来越复杂时,问题就开始了——因为系统往往会变得如此复杂。这给开发人员增加了额外的负担,以准确了解新事件属于哪个流或确定何时需要创建新流。事件跨流的案例越来越多,使得生产者和消费者的发展更加耦合。
例如,CustomerSignedUp 事件在概念上可能是 CustomerOnboarding 流程以及 SubmitTransaction 流程的一部分,但我们只能将其发布到一个主题,在该主题中将对其进行排序。
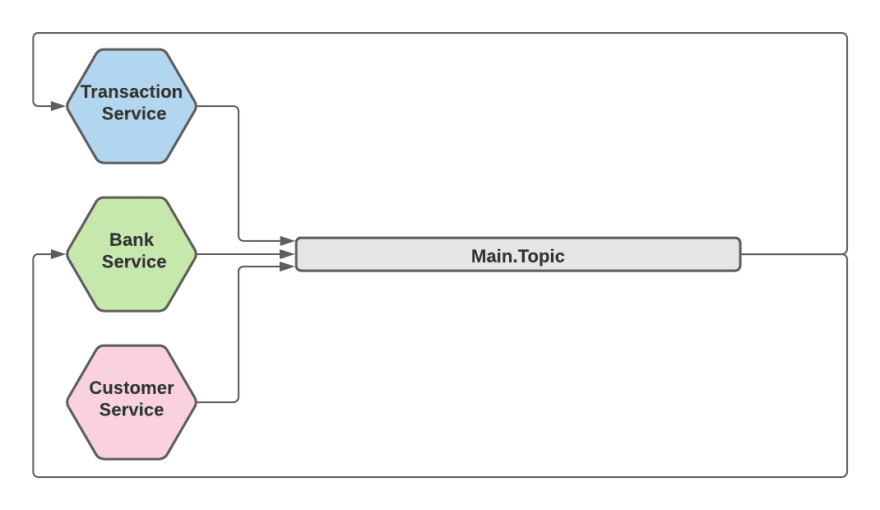
主题作为事件存储(单个主题)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--gUnl4YGw--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/ https://dev-to-uploads.s3.amazonaws.com/uploads/articles/1j45g7v6g7ov49u8mlh8.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--gUnl4YGw--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/ https://dev-to-uploads.s3.amazonaws.com/uploads/articles/1j45g7v6g7ov49u8mlh8.png)
在Event Sourcing架构中,有一个单独的 Event Store 保存系统中的所有事件。事件作为系统状态的单一事实点。您可以在 Kafka 中使用一个“主”主题来实现这一点,该主题包含构成系统状态的所有事件。
事实上,这是“主题即流”方法的一个私人案例,您认为系统中的所有事件都属于单个流。
-
这是最嘈杂的方法 - 订阅者必须监听来自所有生产者的所有事件。如果您有大量事件 - 例如用户点击 - 这可能无法很好地扩展。
-
就运营成本而言最好——配置一次你的框架应该很容易,你不需要再去碰它。代表我们使用 Spring Boot Data Stream 和 Spring Cloud Config,它允许我们在配置所有服务的单个文件中配置主题。
-
它加速了开发过程——一旦模式被协商,生产者和消费者团队可以在解决方案上并行工作。消费者与生产者解耦,理论上生产者甚至不需要知道谁是生产服务。
当然,由于所有事件都进入同一个队列,我们得到系统中所有事件的总顺序(更准确地说 - 每个分区的部分排序 - 稍后会详细介绍)。
Topic As Event Store 是我们为主要产品采用的架构。它使我们能够显着加快开发过程,同时订购保证为我们提供了金融产品所需的数据完整性。它使更快速、更安全地将代码从单体架构迁移到微服务变得更加容易。
噪音呢?
一个优化的 Kafka 消费者每秒可以消耗数百甚至数千条消息,假设您需要做的就是反序列化消息以从中提取事件名称,如果您对该事件不感兴趣,则将其丢弃。因此,要了解噪音问题是否是一个真正的障碍,您需要回答以下问题:
-
什么是噪声/信号比?您的消费者关心事件的 1% 还是 50%?
-
处理事件的可接受延迟是多少?任何事件驱动的系统最终都是一致的,并且预计会有一些延迟。尽管如此,如果每个事件都需要几秒钟或几分钟的时间来处理,您可能会遇到麻烦,特别是如果您有很长的事件链。
-
预期体积是多少?
-
您是否为 CPU/RAM 付费?例如,当使用基于使用的定价的无服务器云框架时。在这种情况下,处理不需要的事件的开销可能会很昂贵。
在代表处,我们发现噪声比不是问题,即使是对一小部分消息感兴趣的服务。我们还将事件类型填充为 Kafka 标头,因此消费者可以丢弃此类消息而无需反序列化它们。但是,当然,随着系统的扩展,这应该被仔细监控。
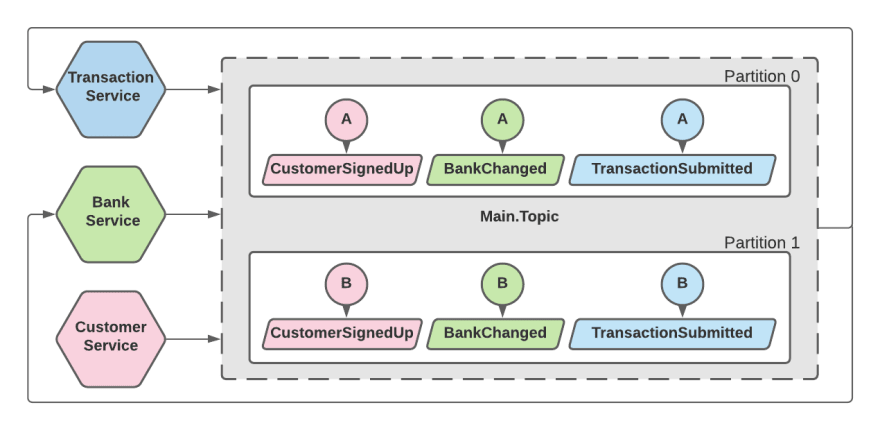
分区
使用单主题方法,我们的事件都排成一行。然而,我们的客户却没有。他们并行访问我们的系统,这意味着如果我们不希望我们的系统停止运行,我们的状态更改流也应该并行运行。
Kafka 允许我们对主题进行分区,以便一组中的多个消费者并行使用它。保证在单个分区上进行排序。默认情况下,分区是使用消息键上的哈希函数确定的,这意味着我们需要属于相同偏序的所有事件都具有相同的消息键。在我们的例子中,消息键可以是客户 ID,因为与同一客户相关的所有消息都应该按顺序使用。不同客户的相同流程可以并行进行。我们必须选择一个可以将大多数事件关联到的一致消息键,例如客户 ID、用户 ID、会话 ID 等(但是,在选择会话 ID 时需要考虑每个用户的多个会话的含义)。如果没有出现,则可能意味着单主题拓扑不是一个好的选择。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--S0iRWGG7--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:/ /dev-to-uploads.s3.amazonaws.com/uploads/articles/txwmnc9nbjm7veaqyw2u.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--S0iRWGG7--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:/ /dev-to-uploads.s3.amazonaws.com/uploads/articles/txwmnc9nbjm7veaqyw2u.png)
我们在选择分区数量时也需要小心。如果不破坏主题,就不可能减少分区数量。每个分区都会带来很小的开销——生产者内存和重新平衡时间,所以不要急于求成。根据您需要支持的并行会话数明智地选择。增加分区的数量是可能的,但它可能会导致排序问题,因为在转换期间可以在不同的分区中找到具有相同键的消息。因此,最好提前计划并从足够大的数量开始。根据经验,您可能需要对 10,000 个分区进行特殊优化,而任何低于 100 个的分区都可能不值得以后再进行扩展。
关于分区数量的最后一个注意事项是消费者线程的数量应该小于分区数量,否则你会有空闲的消费者没有得到任何分配。当分区多于消费者时,Kafka 会重新平衡分区,以便每个消费者都能获得一些分区。当消费者离开并加入群组时,也会发生这种重新平衡。因此,虽然分区的数量大部分是固定的,但服务仍然可以根据流量和负载进行扩展和缩减。但是在为自动横向扩展设计服务时,请记住,您受到分区数量的限制。
结论
在分布式系统中对事件进行排序并不是一件容易的事。 Apache Kafka 的排序保证可以解决这个问题,只要你选择正确的主题拓扑和分区。
在接下来的文章中,我们将深入探讨我们自己对事件溯源的看法以及我们系统中业务和数据事件之间的差异。
*受承保和批准标准的约束。批准发生在事务检查点。如果通过虚拟卡,商家通常在同一天获得付款,如果通过 ACH,商家通常在下一个工作日获得付款(ACH 以太平洋标准时间星期四下午 4:45 的截止时间为准)。处理延迟可能会发生或由于不可预见的情况,例如当需要更多信息时。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35526条内容
已为社区贡献35526条内容

所有评论(0)