从零开始构建无服务器谷歌分析
从工程的角度来看,Google Analytics 背后的技术在创建时非常复杂。为事件收集、采样、聚合和存储输出以用于报告目的实施了定制的、量身定制的算法。那时,发布这样一个软件需要数年的工程时间。从那时起,大数据格局发生了翻天覆地的变化。在本教程中,我们将重建整个 Google Analytics 管道。我们将从数据收集和报告开始。通过使用可用的最新大数据技术,我们将看到如今重现此类软件是多么简单。
TL;DR
这是一个带有嵌入式跟踪代码的分析仪表板,它收集有关其访问者的数据,同时将其可视化。
查看GitHub 上的源代码。喜欢的话给个star吧!
谷歌分析的工作原理
如果您熟悉 Google Analytics,您可能已经知道 GA 跟踪的每个网页都包含一个GA 跟踪代码。它会加载一个异步脚本,如果尚未设置跟踪 cookie,则该脚本会将其分配给用户。它还为每次用户交互发送 XHR,例如页面加载。然后处理这些 XHR 请求,存储原始事件数据并安排用于聚合处理。根据传入请求的总量,还将对数据进行采样。
尽管这是对 Google Analytics 基本要素的高级概述,但足以重现大部分功能。让我告诉你怎么做。
您自己的 GA 架构概览
有多种实现后端的方法。我们将采用无服务器路线,因为 Web 分析最重要的是可扩展性。在这种情况下,您的事件处理管道与负载成比例。就像谷歌分析一样。
在本教程中,我们将坚持使用 Amazon Web Services。谷歌云平台也可以使用,因为它们有非常相似的产品。这是我们将要构建的 Web 分析后端的示例架构。
[
为了简单起见,我们只收集页面浏览事件。页面查看事件的旅程开始于访问者的浏览器,在此发起对 API 网关的 XHR 请求。然后将请求事件传递给 Lambda,在其中处理事件数据并将其写入 Kinesis Data Stream。 Kinesis Firehose 使用 Kinesis Data Stream 作为输入,并将处理过的 parquet 文件写入 S3。 Athena 用于直接从 S3 查询 parquet 文件。 Cube.js 将生成 SQL 分析查询并提供用于在浏览器中查看分析的 API。
乍一看这似乎很复杂,但组件分解是关键。它使我们能够构建可扩展且可靠的系统。让我们开始实现数据收集。
使用 AWS Lambda 构建事件集合
要部署数据收集后端,我们将使用Serverless Application Framework。它使您可以开发对云提供商的代码依赖最少的无服务器应用程序。在我们开始之前,请确保您的机器上安装了 Node.js。此外,如果您还没有 AWS 账户,则需要免费注册和安装和配置 AWS CLI。
要安装无服务器框架 CLI,让我们运行:
# Step 1. Install serverless globally
$ npm install serverless -g
# Step 2. Login to your serverless account
$ serverless login
进入全屏模式 退出全屏模式
现在从 Node.js 模板创建事件收集服务:
$ serverless create -t aws-nodejs -n event-collection
进入全屏模式 退出全屏模式
这将搭建整个目录结构。让我们cd到创建的目录并添加aws-sdk依赖项:
$ yarn add aws-sdk
进入全屏模式 退出全屏模式
如果没有,请安装 yarn 包管理器:
$ npm i -g yarn
进入全屏模式 退出全屏模式
我们需要使用以下代码段更新handler.js:
const AWS = require('aws-sdk');
const { promisify } = require('util');
const kinesis = new AWS.Kinesis();
const putRecord = promisify(kinesis.putRecord.bind(kinesis));
const response = (body, status) => {
return {
statusCode: status || 200,
body: body && JSON.stringify(body),
headers: {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Credentials': true,
'Content-Type': 'application/json'
}
}
}
module.exports.collect = async (event, context) => {
const body = JSON.parse(event.body);
if (!body.anonymousId || !body.url || !body.eventType) {
return response({
error: 'anonymousId, url and eventType required'
}, 400);
}
await putRecord({
Data: JSON.stringify({
anonymous_id: body.anonymousId,
url: body.url,
event_type: body.eventType,
referrer: body.referrer,
timestamp: (new Date()).toISOString(),
source_ip: event.requestContext.identity.sourceIp,
user_agent: event.requestContext.identity.userAgent
}) + '\n',
PartitionKey: body.anonymousId,
StreamName: 'event-collection'
});
return response();
};
进入全屏模式 退出全屏模式
如您所见,这个简单函数所做的唯一事情就是将记录写入名为event-collection的 Kinesis Data Stream。请注意,我们正在以换行符分隔的 JSON 格式写入数据,以便 Athena 和 Kinesis Firehose 能够理解它。
此外,我们需要修改serverless.yml以部署所有内容。将此粘贴到您的serverless.yml文件中。
service: event-collection
provider:
name: aws
runtime: nodejs8.10
iamRoleStatements:
- Effect: "Allow"
Action:
- "kinesis:PutRecord"
Resource:
- "*"
functions:
collect:
handler: handler.collect
events:
- http:
path: collect
method: post
cors: true
进入全屏模式 退出全屏模式
此配置将部署collect函数并为其分配 API Gateway 事件触发器。它还将向该函数分配 AWS Kinesis Data Stream 权限。
这样,我们就完成了编写自制 GA 所需的所有后端代码。它将能够每秒处理数千个传入事件。 2018年太多了,不是吗? :)
让我们将其部署到 AWS:
$ serverless deploy -v
进入全屏模式 退出全屏模式
如果一切正常,您将获得一个 URL 端点。让我们用 CURL 测试一下:
curl -d '{}' https://<your_endpoint_url_here>/dev/collect
进入全屏模式 退出全屏模式
它应该返回400状态代码和如下所示的错误消息:
{"error":"anonymousId, url and eventType required"}
进入全屏模式 退出全屏模式
如果是这种情况,让我们继续进行 Kinesis 设置。
AWS Kinesis 设置
首先,我们需要创建一个名为event-collection的 Kinesis Data Stream。首先,在console.aws.amazon.com登录您的 AWS 账户,然后从菜单中选择 Kinesis 服务。默认情况下,无服务器框架将资源部署到us-east-1区域,因此我们假设在此处创建 AWS Lambda 函数,并在创建流之前根据需要切换区域。
要创建数据流,我们需要将名称设置为event-collection并设置分片数。现在可以设置为 1。分片的数量定义了您的事件收集吞吐量。您可以在此处找到更多信息。
完成数据流后,创建 Kinesis Firehose 传输流。
步骤1
您应该选择event-collectionKinesis 流作为源。
[
第二步
目前,为了使本教程保持简单,我们不需要处理任何数据。在生产中,您需要将其转换为 ORC 或 Parquet 以确保最佳性能。您还可以将此步骤用于事件数据填充,例如 IP 到位置。
[
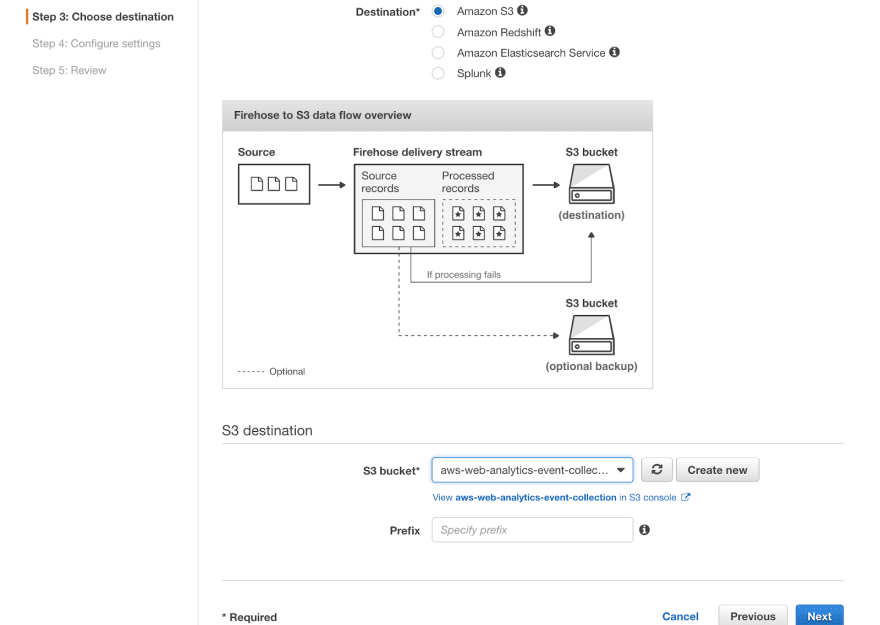
第三步
我们将使用 S3 作为目的地。您需要创建一个新的 S3 存储桶。请选择您喜欢的名称,但添加events后缀,因为它将包含事件。
[
第4步
在这里您可以选择 Gzip 压缩以节省一些费用。系统还会提示您为此传输流创建 IAM 角色。只需按照说明进行操作。
[
而已。如果您做的一切正确,请尝试使用真实有效负载再次运行您的 AWS Lambda 函数。
curl -d '{"anonymousId": "123", "url": "-", "eventType": "pageView"}' https://<your_endpoint_url_here>/dev/collect
进入全屏模式 退出全屏模式
事件应在五分钟内开始流入您的 S3 存储桶。至此,事件收集完成。让我们为分析设置查询。
设置 AWS Athena 以查询分析
随着数据开始流向 S3,我们需要使用元数据来支持它。 Athena 使用它来了解在哪里可以找到数据以及它具有什么结构。这是一个繁琐的过程,但可以使用 AWS Glue 轻松完成。 Glue 是 AWS 的元数据管理器和 ETL。它还有一个爬虫概念,它充当一个 cron 作业,分析 S3 数据以从中提取元数据。
从服务菜单导航到 Glue,然后选择数据库。添加一个新数据库并将其命名为aws_web_analytics。然后转到爬虫并选择“添加爬虫”。
将其命名为events-crawler并选择刚刚创建的 S3 存储桶作为数据存储:
[
根据说明创建一个 IAM 角色并设置为每小时运行一次:
[
作为输出,选择之前创建的数据库:
[
创建完成后,让我们手动运行它。如果成功,您应该会在aws_web_analytics数据库中看到一个表。让我们尝试查询它。
从服务菜单转到 Athena。选择aws_web_analytics数据库并编写一些简单的查询,例如select * from aws_web_analytics_event_collection。您应该得到如下结果:
[
如果一切正常,我们可以继续构建分析 UI。
设置 Cube.js 为最终用户提供分析
AWS Athena 是一个出色的分析后端,适合查询 PB 级数据,但与任何大数据后端一样,它不适合最终用户直接查询。为了提供可接受的性能与成本平衡,您应该在其之上使用缓存和预聚合层以及用于查询分析的 API。这正是 Cube.js 所做的!
首先,我们需要创建一个 IAM 用户来从 Cube.js 访问 Athena。从 AWS 服务菜单中选择 IAM。选择用户并单击添加用户按钮。将用户名设置为cubejs并启用编程访问:
[
在第 2 步,选择直接附加现有策略,然后选择 AmazonAthenaFullAccess 和 AmazonS3FullAccess:
[
继续并创建一个用户。创建完成后,复制访问密钥 ID 和秘密访问密钥并保存。请注意,您只会看到一次秘密,所以不要忘记将其存储在某个地方。
如果您还没有 Cube.js 帐户,现在让我们免费注册。注册后,连接 Athena 作为数据源:
[
您还应该创建一个新的或找到现有的 S3 存储桶,以将 Athena 结果输出存储在 us-east-1 区域内。设置应如下所示:
[
如果 Athena 连接成功,您将被转发到 Cube.js 架构。让我们创建一个新的PageViews文件并将其粘贴到:
cube(`PageViews`, {
sql: `select * from aws_web_analytics.aws_web_analytics_event_collection`,
measures: {
count: {
type: `count`
},
userCount: {
sql: `anonymous_id`,
type: `countDistinct`,
}
},
dimensions: {
url: {
sql: `url`,
type: `string`
},
anonymousid: {
sql: `anonymous_id`,
type: `string`
},
eventType: {
sql: `event_type`,
type: `string`
},
referrer: {
sql: `referrer`,
type: `string`
},
timestamp: {
sql: `from_iso8601_timestamp(timestamp)`,
type: `time`
}
}
});
进入全屏模式 退出全屏模式
请用您自己的替换事件表名称。保存文件并转到资源管理器。您可以在此处的文档中了解有关 Cube.js 架构的更多信息。如果一切正常,您将看到本周的页面浏览量
[
一旦成功,我们就可以启用 Cube.js API 访问了。为此,请转到数据源并编辑 Athena 数据源。在 Cube.js API 选项卡中启用 Cube.js API 访问并复制全局令牌:
[
我们现在准备创建一个 React 应用程序来可视化我们的分析。
构建 React 分析仪表板
让我们使用create-react-app脚手架为我们的应用程序创建目录结构:
$ yarn create react-app analytics-dashboard
进入全屏模式 退出全屏模式
然后cd进入创建的目录并添加所需的依赖项:
$ yarn add @cubejs-client/core @cubejs-client/react antd bizcharts component-cookie uuid whatwg-fetch moment
进入全屏模式 退出全屏模式
@cubejs-client/core和@cubejs-client/react模块用于方便地访问 Cube.js API。而antd和bizcharts用于创建布局和可视化结果。后三个component-cookie、uuid、whatwg-fetch用于实现track page功能,收集用户的事件数据。
让我们从跟踪功能开始。在analytics-dashboard目录中创建一个track.js文件并将其粘贴到:
import { fetch } from 'whatwg-fetch';
import cookie from 'component-cookie';
import uuidv4 from 'uuid/v4';
export const trackPageView = () => {
if (!cookie('aws_web_uid')) {
cookie('aws_web_uid', uuidv4());
}
fetch(
'https://<your_endpoint_url>/dev/collect',
{
method: 'POST',
body: JSON.stringify({
url: window.location.href,
referrer: document.referrer,
anonymousId: cookie('aws_web_uid'),
eventType: 'pageView'
}),
headers: {
'Content-Type': 'application/json'
}
}
)
}
进入全屏模式 退出全屏模式
请将 URL 替换为您自己的收集功能端点。这是我们在客户端跟踪用户页面浏览量所需的所有代码。加载页面时应调用此代码。
让我们用两个简单的图表创建主 App 页面。为此,请将 App.js 内容替换为以下代码段:
import React, { Component } from 'react';
import "antd/dist/antd.css";
import "./index.css";
import { Row, Col, Card, Layout } from "antd";
import cubejs from '@cubejs-client/core';
import { QueryRenderer } from '@cubejs-client/react';
import { Spin } from 'antd';
import { Chart, Axis, Tooltip, Geom, Coord, Legend } from 'bizcharts';
import moment from 'moment';
import { trackPageView } from './track';
const dateRange = [
moment().subtract(14,'d').format('YYYY-MM-DD'),
moment().format('YYYY-MM-DD'),
];
const { Header, Footer, Sider, Content } = Layout;
const renderChart = (resultSet) => (
<Chart scale={{ category: { tickCount: 8 } }} height={400} data={resultSet.chartPivot()} forceFit>
<Axis name="category" label={{ formatter: val => moment(val).format("MMM DD") }} />
{resultSet.seriesNames().map(s => (<Axis name={s.key} />))}
<Tooltip crosshairs={{type : 'y'}} />
{resultSet.seriesNames().map(s => (<Geom type="line" position={`category*${s.key}`} size={2} />))}
</Chart>
);
const API_KEY = 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpIjo0MDY3OH0.Vd-Qu4dZ95rVy9pKkyzy6Uxc5D-VOdTidCWYUVhKpYU';
class App extends Component {
componentDidMount() {
trackPageView();
}
render() {
return (
<Layout>
<Header>
<h2 style={{ color: '#fff' }}>AWS Web Analytics Dashboard</h2>
</Header>
<Content style={{ padding: '25px', margin: '25px' }}>
<Row type="flex" justify="space-around" align="middle" gutter={24}>
<Col lg={12} md={24}>
<Card title="Page Views" style={{ marginBottom: '24px' }}>
<QueryRenderer
query={{
"measures": [
"PageViews.count"
],
"timeDimensions": [
{
"dimension": "PageViews.timestamp",
"dateRange": dateRange,
"granularity": "day"
}
]
}}
cubejsApi={cubejs(API_KEY)}
render={({ resultSet }) => (
resultSet && renderChart(resultSet) || (<Spin />)
)}
/>
</Card>
</Col>
<Col lg={12} md={24}>
<Card title="Unique Visitors" style={{ marginBottom: '24px' }}>
<QueryRenderer
query={{
"measures": [
"PageViews.userCount"
],
"timeDimensions": [
{
"dimension": "PageViews.timestamp",
"dateRange": dateRange,
"granularity": "day"
}
]
}}
cubejsApi={cubejs(API_KEY)}
render={({ resultSet }) => (
resultSet && renderChart(resultSet) || (<Spin />)
)}
/>
</Card>
</Col>
</Row>
</Content>
</Layout>
);
}
}
export default App;
进入全屏模式 退出全屏模式
确保将API_KEY常量替换为您自己的 Cube.js 全局令牌。您应该能够看到带有两个图表的仪表板:
[
再一次,这里是仪表板的部署版本,如果您想查看的话。
要部署您自己的,请创建一个启用静态站点服务的公共 S3 存储桶,构建应用程序并将其同步到存储桶:
$ yarn build
$ aws s3 sync build/ s3://<your_public_s3_bucket_name>
进入全屏模式 退出全屏模式
您还可以使用Netlify之类的服务来托管您的网站。它们使部署和托管网站变得异常简单。
结论
本教程向您展示了如何构建与 Google Analytics 功能集相比的概念证明。该架构的可扩展性足以每秒处理数千个事件,并且可以分析数万亿个数据点而不会费力。 Cube.js 适用于实现您希望在 GA 中看到的所有指标,例如跳出率、会话花费的时间等。您可以在此处阅读更多信息。如果没有数据的预先聚合,就无法构建大规模分析。 GA 做了很多,Cube.js 有一个的内置解决方案。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献35528条内容
已为社区贡献35528条内容

所有评论(0)