S Lambda 上的# 个 AWS SQS 事件
2018 年,AWS 宣布在 AWS Lambda 上支持 SQS 触发事件。对于采用无服务器架构的公司而言,这为事件驱动架构、简化批处理基础架构等开辟了新的可能性。
在该功能推出之前,如果您是一家需要处理 SQS 消息的无服务器商店,唯一的选择是使用 CloudWatch 触发一个 Lambda 函数,该函数轮询消息,然后扇出工作人员或咀嚼成批的 SQS 消息。虽然这行得通,但它很容易出错。一个 Lambda 函数只能存在 5 分钟,此时它可以启动另一个 Lambda 函数并传递火炬,或者只是等待 CloudWatch 触发另一个 Lambda 函数。根据 Lambda 函数运行的时间长短,您要么浪费时间等待下一个 CloudWatch 触发器,要么由于 Lambda 函数超时而收到大量消息并多次接收。
在 Edelman Financial Engines,我们致力于支持两件事:事件驱动架构和无服务器架构。这两种设计使我们能够创建更具可扩展性的应用程序,并专注于对我们很重要并对我们的客户产生直接影响的事情。随着最近的 Lambda 和 SQS 公告,我们现在有了一个以无服务器方式处理队列的新选项:只需在 Lambda 函数上为队列配置事件源映射。
事件驱动架构
当客户或规划师在我们的网站上做某事时,会运行一系列决策和流程。事件驱动的架构使我们能够在合理的时间内完成这项工作。以客户登录为例。当客户按下登录按钮时,我们必须做一系列事情;从提供商处获取客户的最新资产,验证客户的信息,生成客户进度的快照,运行蒙特卡洛模拟,等等。
使用事件驱动架构,一旦登录发生,事件就会被发送到事件总线,消费者等待处理某些事件。在我们的用例中,分析消费者可以处理登录事件并触发客户参与度指标进行报告。不久之后,发布了另一个事件,称客户的最新资产已更新。然后,该事件的多个消费者可以预先计算客户端的当前进度并同时运行蒙特卡罗模拟并缓存结果。现在,当客户导航到我们的网站登录页面时,他们的结果几乎立即显示出来,而不是如果我们按顺序执行所有操作通常需要 10 多秒。
拥有像 SNS 和 SQS 这样的服务极大地促进了这种架构模型。我们可以将消费者(AWS Lambda、SQS 队列、HTTP 端点等)设置为 SNS 主题的端点,对输入进行异步繁重的处理。对于 SQS,队列可以由消费者(以前只有 EC2 实例,但现在也可以使用 Lambda 函数)以批处理方式处理消息。
无服务器架构
在 Financial Engines,我们接受了 DevOps 文化,将决策转移到功能开发团队级别,提供更多的工具和技术选择来解决手头的各种问题。但是,我们不希望开发团队陷入操作系统修补、自动扩展服务器等任务的困境。为此,我们为团队制定了尽可能使用托管服务的标准。
团队可以使用 AWS Lambda、DynamoDB、S3 等启动完整的微服务,而无需预置或管理任何服务器和操作系统补丁,并且仍然可以获得他们需要的功能。除了易于使用之外,我们还通过切换到无服务器计算显着节省了成本。 (查看此金融引擎 AWS 案例研究以了解更多详细信息。)
使用 SQS 和 AWS Lambda 预先计算进度
对于这个新功能/架构的示例,我将深入探讨上述场景之一。当客户的馆藏更新时,无论是客户端触发更新还是运行作业以更新所有客户馆藏,都会发布一个事件,其中包含有关该客户及其馆藏的一些详细信息。然后,我们让该事件的消费者预先计算客户端的当前进度并缓存结果。
我们需要考虑几个因素。
-
如果客户端触发了更新(例如客户端登录),那么进度分数很可能很快就会被消耗掉,需要尽快进行预计算。
-
如果运行一个作业来更新所有客户持有量,那么该进度分数很快被消耗的可能性相当低,因此我们可以花时间进行预计算。
为了满足这些要求,我们创建了以下架构。
[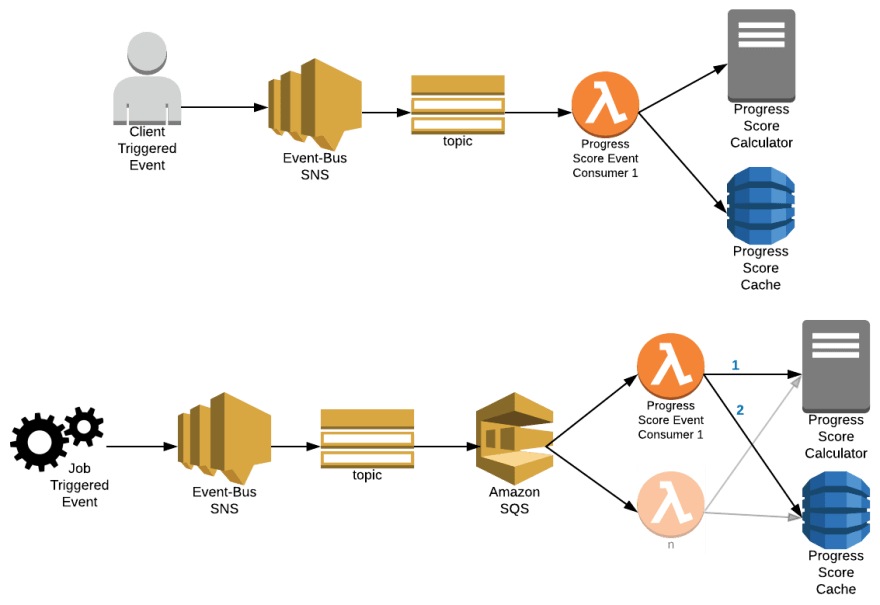 ](https://res.cloudinary.com/practicaldev/image/fetch/s--Lb4LEe4U--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/buui0n2tdexa2kza8bvv.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Lb4LEe4U--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/buui0n2tdexa2kza8bvv.png)
我们的事件总线将事件发布到 SNS 主题。从那里,消费者决定如何处理消息。对于客户端触发的更新,我们将 AWS Lambda 函数设置为馆藏更新主题的端点。我们还配置了消息属性过滤,以便此 Lambda 函数仅接收客户端触发的事件。对于我们的作业触发事件,我们使用 SQS 队列来使用过滤后的事件。然后,我们使用 AWS lambda 上新创建的 SQS 事件来处理该队列。
接下来,我将引导您了解如何配置 SQS-to-AWS Lambda 连接。
第一步:
您需要的第一件事是接受 SQS 事件的 lambda
对于我们的 Lambda 函数,我们需要通过 gradle 获得以下依赖项:
compile 'com.amazonaws:aws-java-sdk-lambda:1.11.321'
compile 'com.amazonaws:aws-java-sdk-sqs:1.11.321'
进入全屏模式 退出全屏模式
在最基本的层面上,Java 8 中的处理程序代码是这样配置的:
package com.fngn.samples;
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import com.amazonaws.services.lambda.runtime.events.SQSEvent;
import com.fngn.samples.api.dto.EventDto;
import com.fngn.samples.api.dto.ResponseDto;
import com.fngn.samples.application.service.EventConsumer;
public class QueueConsumerLambda implements RequestHandler<SQSEvent, Void> {
@Override
public Void handleRequest(SQSEvent event, Context context) {
try {
for (SQSEvent.SQSMessage message : event.getRecords()) {
EventDto eventDto = null;
ResponseDto responseDto = null;
String input = message.getBody();
eventDto = unmarshalEventBody(input);
responseDto = eventConsumer.processEvent(eventDto);
handleFailures(responseDto, message);
}
} catch (Exception ex) {
logger.error("Exception handling batch seed request.", ex);
throw ex;
}
return null;
}
...
}
进入全屏模式 退出全屏模式
最后,我们将其与 Lambda 函数和执行角色的以下 CloudFormation 定义结合在一起(对于奖励积分,我们添加了死信队列配置):
queueConsumerLambda:
Type: 'AWS::Lambda::Function'
Properties:
Handler: 'com.fngn.samples.QueueConsumerLambda::handleRequest'
Role: !Sub "arn:aws:iam::*:role/${queueConsumerExecutionRole}"
Description: !Sub "Cloud formation lambda for ${projectName}"
FunctionName: !Sub "${projectName}-queue-consumer"
MemorySize: 512
Timeout: 30
Code:
S3Bucket: "com.fngn.samples"
S3Key: !Sub "${projectName}/${lambdaCode}"
Runtime: java8
TracingConfig:
Mode: Active
Environment:
Variables:
REGION: !Ref "AWS::Region"
APP_ID: !Sub ${projectName}-event-consumer
ENV_REALM: !Sub ${accountType}
DependsOn:
- queueConsumerExecutionRole
queueConsumerExecutionRole:
Type: 'AWS::IAM::Role'
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Action: 'sts:AssumeRole'
Principal:
Service: lambda.amazonaws.com
Effect: Allow
Sid: ''
Policies:
- PolicyName: !Sub "${projectName}-queue-consumer-policy"
PolicyDocument:
Version: '2008-10-17'
Statement:
...
- Action:
- sqs:ChangeMessageVisibility
- sqs:DeleteMessage
- sqs:GetQueueAttributes
- sqs:ReceiveMessage
- sqs:SendMessage
Effect: Allow
Resource:
- !GetAtt sqsQueue.Arn
- !GetAtt sqsQueueDLQ.Arn
Sid: 'SQSPermissions'
进入全屏模式 退出全屏模式
第二步:
我们现在可以通过订阅我们的 SNS 主题的 CloudFormation 创建一个 SQS 队列。
sqsQueue:
Type: 'AWS::SQS::Queue'
Properties:
QueueName: !Sub '${projectName}-ConsumerQueue'
RedrivePolicy:
deadLetterTargetArn: !GetAtt sqsQueueConsumerDLQ.Arn
maxReceiveCount: 5
VisibilityTimeout: 600
policyQueueConsumer:
Type: 'AWS::SQS::QueuePolicy'
Properties:
PolicyDocument:
Id: !Sub '${projectName}-ConsumerQueuePolicy'
Version: '2012-10-17'
Statement:
- Sid: 'AllowConsumerSnsToSqsPolicy'
Effect: 'Allow'
Principal:
AWS: '*'
Action:
- 'sqs:SendMessage'
Resource: !GetAtt sqsQueue.Arn
Condition:
ArnEquals:
aws:SourceArn: !Sub 'arn:aws:sns:*:*:holding-events']]
Queues:
- !Ref sqsQueue
进入全屏模式 退出全屏模式
第三步:
现在这两个已经到位,我们可以配置触发器:
sqsEventTrigger:
Type: "AWS::Lambda::EventSourceMapping"
Properties:
BatchSize: 5
Enabled: true
EventSourceArn: !GetAtt sqsQueue.Arn
FunctionName: !Sub "${projectName}-queue-consumer"
DependsOn:
- queueConsumerLambda
- queueConsumerExecutionRole
进入全屏模式 退出全屏模式
第四步:
将消息发送到您的 SQS 队列,或者,在我们的例子中,发送到 SNS 主题,然后坐下来观看 Lambda 函数在消息进入时仔细检查它们。老实说,就是这么简单。
使用此配置,这就是正在发生的事情。 AWS Lambda 接管轮询并调用并发 Lambda 函数来处理队列,其中包含高达配置的批处理大小的消息块(在我们的示例中,我们将批处理大小配置为 10 条消息)。 Lambda 函数处理 SQSEvent 中的每条消息。如果其中任何一条消息失败,Lambda 函数就会失败,并且消息会保留在队列中。如果所有消息都成功,则 AWS Lambda 会从队列中删除消息。如果队列配置了死信队列(上述重新驱动策略),则 AWS Lambda 将尝试处理这些消息,直到达到最大接收计数 5。此时,如果可见性超时到期并且消息仍在队列,SQS 将从队列中删除该消息并将其移动到死信队列。
监控
您可以使用 AWS Lambda 和 SQS 服务控制台中的控制面板,也可以配置您自己的 CloudWatch 控制面板来监控进度。我们还使用了 AWS X-Ray,它确实帮助我们尽早发现了微服务中下游资源的问题。
在 AWS Lambda 控制面板中,您可以快速查看该服务如何非常一致地调用您的 Lambda 函数,直到队列为空。在下面的案例中,我们将执行限制为 200 名“工人”。因此,您还可以看到限制,因为 AWS Lambda 对并发执行程序实施了限制。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s---E_msvp5---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to-uploads.s3.amazonaws.com/i/i3sqxuejngfp8o1ccosb.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s---E_msvp5---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to-uploads.s3.amazonaws.com/i/i3sqxuejngfp8o1ccosb.png)
在 SQS 仪表板中,您可以看到进入队列的消息率、接收率和其他有趣的花絮。正如您在下面的图表中看到的那样,我们的工作生成事件的速度比我们的 200 个并发执行器处理它们的速度要快,通过注意到消息的年龄会随着 Lambda 函数完成处理所有消息而上升然后急剧下降。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--6ejFUHyr--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/i/ueydbc134ic4qwxgnymp.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--6ejFUHyr--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/i/ueydbc134ic4qwxgnymp.png)
在 X-Ray 中,您可以看到构成此微服务的所有组件。处理 SNS 消息的 Lambda 函数、处理 SQS 队列的 Lambda 函数以及提供缓存响应的 Lambda 函数。
[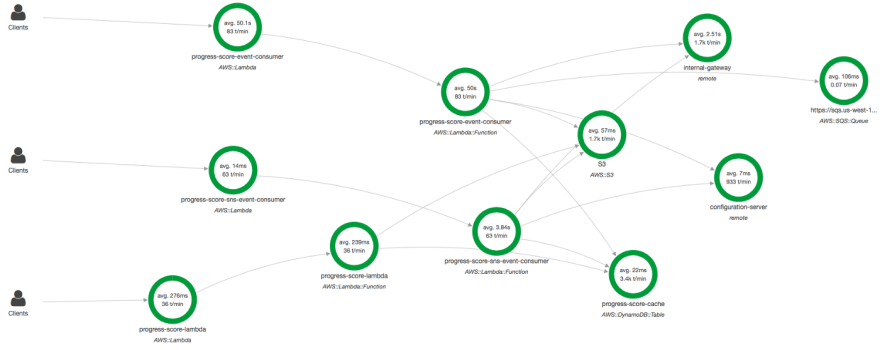 ](https://res.cloudinary.com/practicaldev/image/fetch/s--FBWQCZni--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/ujlm6069629xkrxlqum.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--FBWQCZni--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/ujlm6069629xkrxlqum.png)
高级配置
并发和EventSourceMapping配置
在我们的用例中,我们进一步进行了配置。例如,如果运行一项作业来更新所有客户的资产,那么每分钟的事件率会在短时间内达到相当高的峰值。用于计算进度分数的下游资源(例如数据库)可能无法支持该负载。
在这种情况下,我们所做的是根据一周中的某一天或一天中的时间创建一个包含订阅详细信息的时间表。然后,我们配置了每小时触发 Lambda 函数的 CloudWatch 事件。根据计划的订阅详细信息,该 Lambda 函数会更新 SQS 使用者 Lambda 函数配置或其 SQS 事件映射。
{
"MON-FRI_09:00-04:00_11:00-04:00": {
"queueEnabled":false
},
"MON-FRI_11:00-04:00_22:00-04:00": {
"queueEnabled":true,
"workers":15,
"batchSize":10
},
"MON-FRI_22:00-04:00_09:00-04:00": {
"queueEnabled":true,
"workers":100,
"batchSize":10
}
}
进入全屏模式 退出全屏模式
这种控制水平被证明是非常强大的。白天,在我们负载的高峰期,谨慎的做法是不要冒险在下游资源同时为客户流量提供服务时承受压力。我们可以完全禁用处理(即禁用 EventSourceMapping)或将 Lambda 函数执行并发配置为较低的数字(例如:15)。但是,在晚上,我们可以将并发执行的数量增加到 100。在周末,我们可以将其提高到更高,例如,200 并发执行。
确定我们的并发限制需要跨职能团队的努力和多次运行。有了云端和本地资源,我们需要在不断增加数量的同时密切监控它们。最终,我们的本地关系数据库最终将微服务限制为不超过 200 次并发执行,大致相当于每分钟 5000 条消息和 140 万次数据库调用。
过滤SNS消息
如前所述,我们的用例有两种类型的馆藏更新事件。有用户触发的事件和作业触发的事件。这些 SNS 作业的事件元数据也在 SNS 消息属性字段中配置。
在这种情况下,您可以使用 SDK 配置过滤给定端点的消息。对于我们的 SNS-to-AWS Lambda,我们可以让它只接收 appTypeu003dWEB 的事件。对于我们的 SNS 到 SQS 流程,我们将其配置为仅接收 appTypeu003dJOB 的事件。
Subscription subscription = getSubscriptionForArn(environment.getenv("BATCH_SNS_ENDPOINT"));
if (batchSubscription != null) {
String jsonPolicy = "{\"applicationType\": [\"JOB\"]};
setFilterPolicy(subscription.getSubscriptionArn(), jsonPolicy);
}
进入全屏模式 退出全屏模式
我们更进一步,还过滤了有关启用的金融机构或雇主的消息。这帮助我们显着降低了消息处理的成本,并简化了我们的代码,因为 Lambda 函数不再需要自己进行过滤。
String getBatchSubscriptionFilterPolicy() throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
JsonGenerator generator = (new JsonFactory()).createGenerator(baos, JsonEncoding.UTF8);
generator.writeStartObject();
generator.writeFieldName("applicationType");
generator.writeStartArray();
generator.writeString("JOB");
generator.writeEndArray();
Set<String> financialInstitutions = getFinancialInstitutions();
if (financialInstitutions.isEmpty() == false) {
generator.writeFieldName("financialInstitutionId");
generator.writeStartArray();
for (String financialInstitution : financialInstitutions) {
generator.writeString(financialInstitution);
}
generator.writeEndArray();
}
Set<String> employers = getEmployers();
if (employers.isEmpty() == false) {
generator.writeFieldName("employerId");
generator.writeStartArray();
for (String employer : employers) {
generator.writeString(employer);
}
generator.writeEndArray();
}
generator.writeEndObject();
generator.close();
return baos.toString();
}
进入全屏模式 退出全屏模式
注释/提示/功能请求
虽然这是一个相当强大的功能,但我们希望在未来看到一些东西。
例如,在使用此功能处理死信队列时,实际上您必须手动删除失败的消息,否则它们很快就会变成“毒丸”。如果您不手动删除消息,那么您需要为死信队列创建一个死信队列,以便您可以将最大接收计数设置为 2,例如,忽略进入最终队列的内容。当我认为我可以重用处理主队列的同一个 Lambda 函数时,这比我预期的要繁重一些。如果 AWS 允许您在不指定另一个死信队列的情况下设置重新驱动策略,那就太好了。
另一个问题是 Lambda 函数的节流率。有时,我们看到每分钟有数百次调用受到限制。虽然文档说支持并发执行,但我们假设 AWS Lambda 调用的 Lambda 函数的速率也将受限于并发执行器的数量。我想,从长远来看,如果您限制并发执行,这可能会变得昂贵且有些浪费。我希望看到 AWS 解决这个问题,或者尽量减少受限制的 lambda 的数量。
最后,虽然不是 AWS 可以解决的真正问题,但我们在配置下游资源的自动扩展方面遇到了困难。因为,如前所述,作业可以在一天中的任何时间开始,并在短时间内导致发布事件的突然显着峰值。 DynamoDB 的读/写 Auto Scaling 等下游服务在最初的几分钟内总是滞后响应。这会导致限制激增,从而导致消息失败,这是配置死信队列很重要的另一个原因。 (请注意,仪表板显示每分钟平均值,因此并不总是等同于实际油门。)
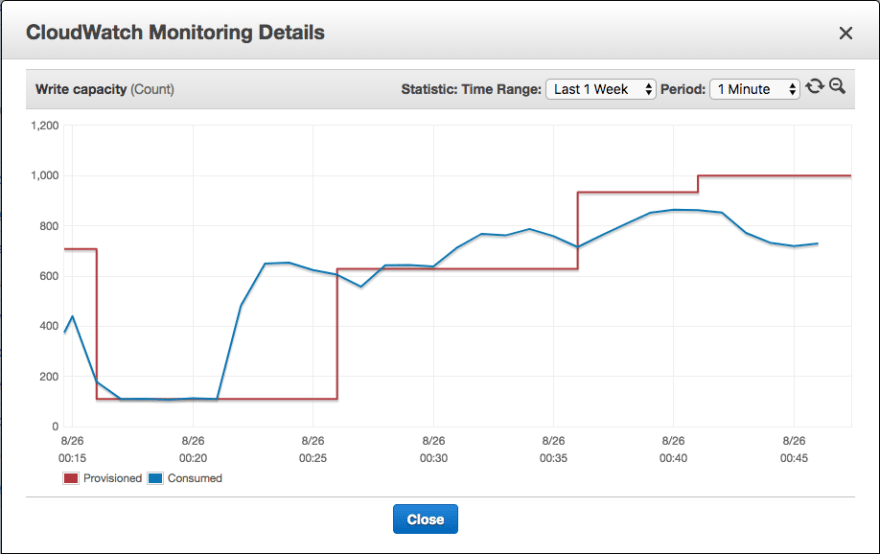
结论
我希望通过这篇文章你可以看到这个新特性是多么的强大,以及它是如何大大减少基础设施的代码/管理来支持队列处理的。
随时提出任何问题并提出您可能有的任何意见。另外,回来查看我们发布的任何新内容。我们一直在玩弄一些最新最好的功能,目的是在团队开始使用这些功能之前找出所有细微差别。
编码快乐!

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35526条内容
已为社区贡献35526条内容

所有评论(0)