Fauna 和 Cloudflare Workers 入门
简介
在本教程中,我们将构建一个简单的 CRUD API 来管理目录库存。我们的代码将部署在全球Cloudflare的基础设施上,并在serverless Workers 运行时上执行,该运行时将使用Fauna作为其数据层。
两种服务共享相同的无服务器全球 DNA。结合起来,它们成为构建可以轻松处理任何负载的低延迟服务的理想平台。
为什么将 Fauna 与 Cloudflare Workers 一起使用?
由于其基于 HTTP 的非持久连接模型,Fauna 可以与 Workers 无缝集成。使用这两种服务的应用程序可以端到端运行无服务器,并且可以无限扩展,无需管理基础设施。
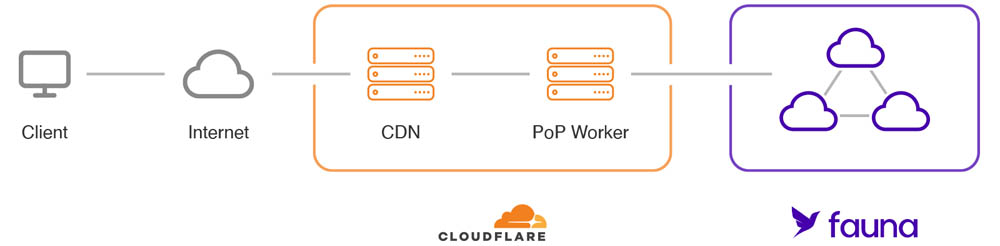
此设置非常适合低延迟服务。通常,服务器端应用程序在单个位置运行其逻辑和数据库。当使用带 Fauna 的 Workers 时,数据和代码将在多个位置运行,并且可以大大减少往返读取延迟。如果您想与 Fauna 专家讨论如何将 Cloudflare Workers 与 Fauna 一起使用,请拨打联系我们。否则,请继续阅读以进行动手练习!
我们正在建造什么
我们的应用程序将包含一个带有 CRUD 功能的 JavaScript REST API,它将管理一个简单的产品库存。
由于 Fauna 是一个基于文档的数据库,我们的产品文档将包含以下数据:
-
title 一个人性化的字符串,表示产品的标题或名称
-
serialNumber 一个机器友好的字符串,用于标识产品
-
weightLbs 一个浮点数,以磅为单位的产品重量
-
quantity 一个整数,详细说明库存中有多少产品
文档将存储在 Products 集合中。 Fauna 中的集合只是文档的桶。
为简单起见,我们 API 的端点将是公开的。检查最后的一些建议,关于如何改进这一点。
最后,我们将使用 Cloudflare Workers 在边缘执行我们应用程序的 JavaScript 代码。
要求
要完成本教程,您需要一个 Fauna 和一个 Cloudflare 帐户。您无需添加任何付款信息,因为我们将使用这两项服务的免费套餐。
您还需要在开发机器上安装以下工具:
-
节点(任何最新版本都可以使用)
-
Cloudflare 的牧马人 CLI
设置动物群
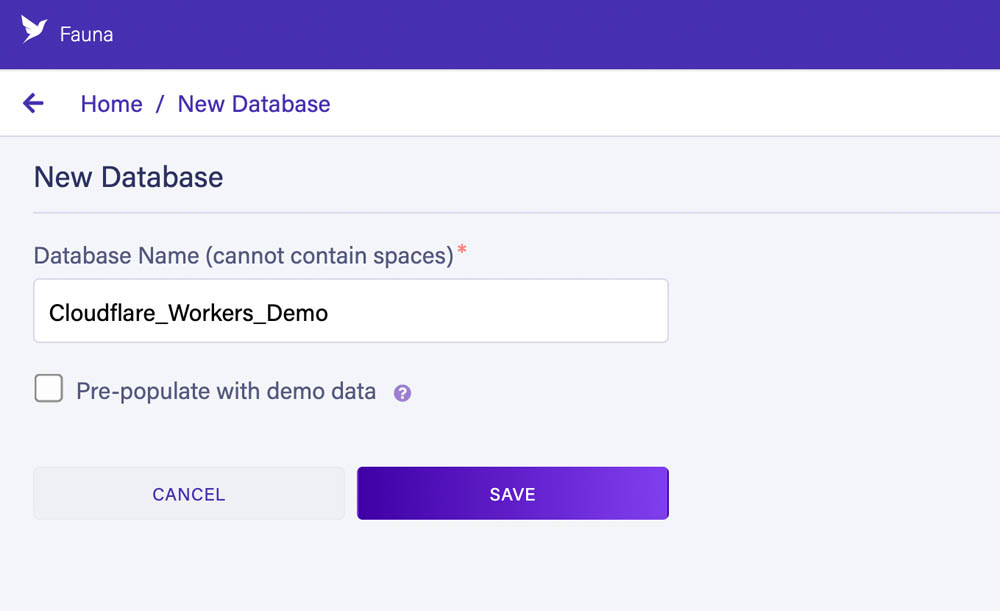
我们的第一步是通过 Fauna 的仪表板配置数据库。
将登录到仪表板后,创建一个名为 Cloudflare_Workers_Demo 的新数据库:
 .jpg
.jpg
创建产品目录
我们现在要创建 Products 集合来存储我们库存的文档。
为此,我们将对仪表板主菜单中的Fauna shell执行FQL查询:
 。
。
要创建集合,只需执行以下使用CreateCollection函数的 FQL 查询:
CreateCollection({name: "Products"})
进入全屏模式 退出全屏模式
结果将与此类似:
{
ref: Collection("Products"),
ts: 1617851434855000,
history_days: 30,
name: "Products"
}
进入全屏模式 退出全屏模式
-
ref 是对集合本身的引用。请参阅集合FQL 函数。
-
ts 是其创建的时间戳,以微秒为单位。
-
history_days 确定 Fauna 将在集合文档上保留更改的时间。
-
name 是集合的名称。
创建服务器密钥
为了能够从 Worker 连接到数据库,我们现在需要创建一个密钥。
转到仪表板的 Security 部分并使用 Server 角色创建一个新密钥:
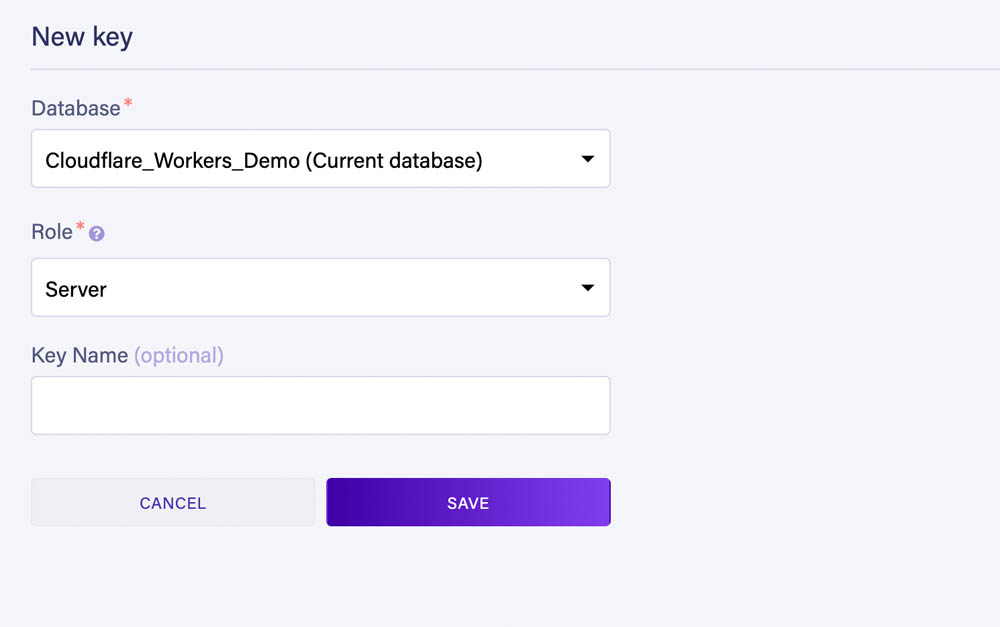
保存后,Fauna 将向我们显示密钥的秘密,我们将使用它来执行来自 Worker 的查询:
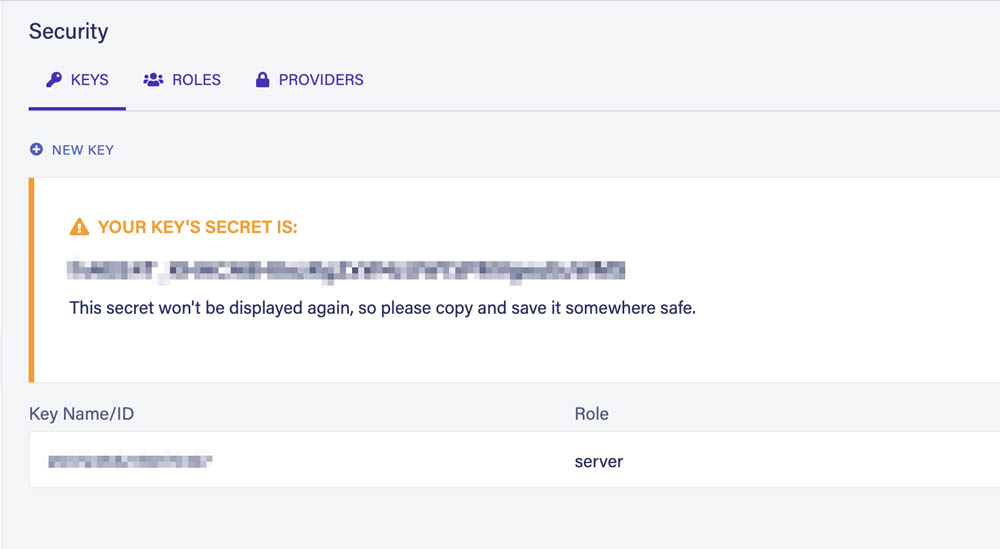
将秘密保存在安全的地方,因为 Fauna 将永远不会再显示它。
此外,永远不要将此秘密提交到您的 Git 存储库。 Server 角色是无所不能的。任何拥有此机密的人都可以完全访问数据库。您可以在文档中了解有关默认角色的更多信息。
Fauna 的初始配置已准备就绪。现在让我们关注应用程序的逻辑。
与工人一起管理我们的库存
首先,如果您还没有这样做,请创建一个免费的 Cloudflare 帐户并配置 Workers 服务:
您还需要在您的开发机器上安装Wrangler CLI。
完成后,使用login命令让 Wrangler 访问您的 Cloudflare 帐户:
wrangler login
进入全屏模式 退出全屏模式
牧马人配置
创建 Cloudflare Worker 的第一步是使用init命令初始化项目:
wrangler init
进入全屏模式 退出全屏模式
这将创建一个带有默认配置的 wrangler.toml 文件,该配置类似于:
name = "fauna-cloudflare-workers-tutorial"
type = "webpack"
account_id = ""
workers_dev = true
route = ""
zone_id = ""
进入全屏模式 退出全屏模式
项目文件夹的名称将用作工作人员名称,但如果您愿意,可以更改它。
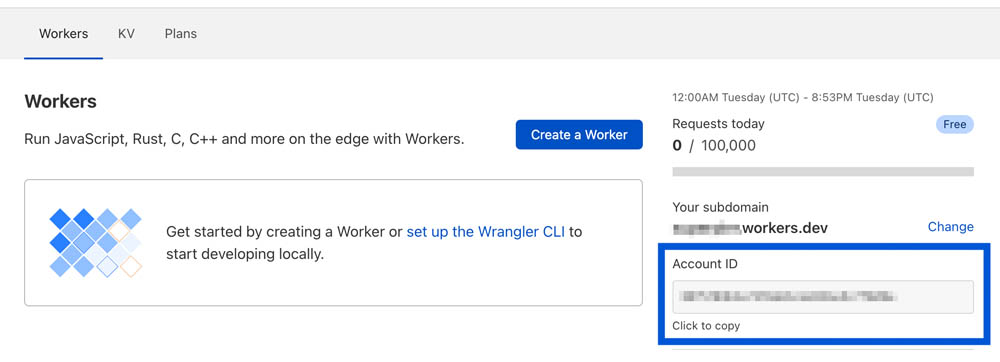
您还需要将 Cloudflare 帐户 ID 添加到 Cloudflare 仪表板的 Workers 部分中的 wrangler.toml 文件中:
创建测试工作者
在继续之前,我们将创建一个最小的工人来测试一切是否按预期工作。
在您的项目文件夹中使用以下内容创建一个 index.js 文件:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request));
});
async function handleRequest(request) {
return new Response('hello world', {status: 200});
}
进入全屏模式 退出全屏模式
然后通过执行以下操作初始化 NPM:
npm init -y
进入全屏模式 退出全屏模式
这将使用默认设置创建一个 package.json 文件。
最后发布 Worker
wrangler publish
进入全屏模式 退出全屏模式
这将创建 Worker 并将其上传到 Cloudflare。部署后,您的 Worker 将在以下位置可用:
[worker name].[workers subdomain].workers.dev
进入全屏模式 退出全屏模式
如果您在浏览器中打开已部署的 URL,您应该会看到:
hello world
进入全屏模式 退出全屏模式
将 Fauna 密码添加为环境变量
创建并部署 Worker 后,我们就可以将 Fauna 机密安全地存储在 Cloudflare 的基础架构上。为此,请使用以下命令:
wrangler secret put FAUNA_SECRET
进入全屏模式 退出全屏模式
运行此命令后,粘贴您之前获得的 Fauna 服务器密码。
FAUNA_SECRET 环境变量现在将在运行时自动注入到我们的 Worker 代码中。
也可以直接在 wrangler.toml 文件上配置环境变量,但在这种情况下,我们希望避免将敏感数据提交到 Git 存储库。
安装依赖
我们将为我们的 Worker 使用 JavaScript,但也可以使用其他可以编译为 Web Assembly 或 JavaScript 的语言。有关这方面的更多信息,请参阅文档。
首先,让我们安装 Fauna JavaScript 驱动程序:
npm install faunadb@^4.2.0
进入全屏模式 退出全屏模式
然后为 Cloudflare Workers 安装Worktop框架:
npm install worktop
进入全屏模式 退出全屏模式
Worktop 将开箱即用地解决常见需求,例如路径参数、查询字符串参数、HTTP 方法、CORS 等。
JavaScript 实用函数
我们将通过关注一些实用函数来开始编码部分。使用以下内容在项目文件夹中创建 utils.js 文件:
export function customFetch (url, params) {
const signal = params.signal;
delete params.signal;
const abortPromise = new Promise((resolve) => {
if (signal) {
signal.onabort = resolve
}
});
return Promise.race([abortPromise, fetch(url, params)])
}
export function getFaunaError (error) {
const {code, description} = error.requestResult.responseContent.errors[0];
let status;
switch (code) {
case 'instance not found':
status = 404;
break;
case 'instance not unique':
status = 409;
break;
case 'permission denied':
status = 403;
break;
case 'unauthorized':
case 'authentication failed':
status = 401;
break;
default:
status = 500;
}
return {code, description, status};
}
进入全屏模式 退出全屏模式
Fauna 客户端需要 customFetch() 函数,因为 Workers 运行时使用自定义版本的 fetch。在Fauna JavaScript 驱动程序文档上有更多信息。
我们将使用 getFaunaError() 函数来提取 Fauna 返回的最常见错误的代码和描述。此函数还将确定每个错误的 HTTP 状态代码。
基础库存逻辑
我们现在可以用我们的 API 框架替换 index.js 文件的内容:
import {Router, listen} from 'worktop';
import faunadb from 'faunadb';
import {customFetch, getFaunaError} from './utils.js';
const router = new Router();
const faunaClient = new faunadb.Client({
secret: FAUNA_SECRET,
fetch: customFetch
});
const {Create, Collection, Match, Index, Get, Ref, Paginate, Sum, Delete, Add, Select, Let, Var, Update} = faunadb.query;
router.add('GET', '/', async (request, response) => {
response.send(200, 'hello world');
});
listen(router.run);
进入全屏模式 退出全屏模式
下面分析一下Fauna客户端的初始化:
const faunaClient = new faunadb.Client({
secret: FAUNA_SECRET,
fetch: customFetch
});
进入全屏模式 退出全屏模式
FAUNA_SECRET 环境变量将在运行时自动注入到我们的应用程序中。 Worker 在自定义 JavaScript 运行时而不是 Node.js 上运行,因此无需使用 process.env 来访问这些变量。我们获得的 Fauna 机密属于具有 Server 角色的密钥,这将使我们的工作人员可以完全访问 Fauna 数据库。
如前所述,我们使用自定义的 fetch() 函数,以便 Fauna 客户端可以在 Workers 运行时上运行。
在实例化客户端之后,我们正在创建对我们将在查询中使用的 FQL 函数的引用:
const {Create, Collection, Match, Index, Get, Ref, Paginate, Sum, Delete, Add, Select, Let, Var, Update} = faunadb.query;
进入全屏模式 退出全屏模式
这将使我们的 JavaScript FQL 查询在以后更加清晰。
在动物群中创造新产品
让我们在 index.js 文件中添加我们的第一个 Worktop 路由。此路由将在 /products REST 端点接受 POST 请求:
router.add('POST', '/products', async (request, response) => {
try {
const {serialNumber, title, weightLbs} = await request.body();
const result = await faunaClient.query(
Create(
Collection('Products'),
{
data: {
serialNumber,
title,
weightLbs,
quantity: 0
}
}
)
);
response.send(200, {
productId: result.ref.id
});
} catch (error) {
const faunaError = getFaunaError(error);
response.send(faunaError.status, faunaError);
}
});
进入全屏模式 退出全屏模式
为简单起见,我们不会在这些示例中验证请求输入。
在这条路线上,我们看到了第一个用 JavaScript 编写的 FQL 查询,它将在 Products 集合中创建一个新文档:
Create(
Collection('Products'),
{
data: {
serialNumber,
title,
weightLbs,
quantity: 0
}
}
)
进入全屏模式 退出全屏模式
在这种情况下,Create函数引用来自Collection函数的集合,以及包含文档内容的对象。
要查看文档的外观,让我们直接在仪表板外壳中运行此查询:
Create(
Collection('Products'),
{
data: {
serialNumber: "A48432348",
title: "Gaming Console",
weightLbs: 5,
quantity: 0
}
}
)
进入全屏模式 退出全屏模式
结果将是创建的文档:
{
ref: Ref(Collection("Products"), "295308099167715846"),
ts: 1617886599610000,
data: {
serialNumber: "A48432348",
title: "Gaming Console",
weightLbs: 5,
quantity: 0
}
}
进入全屏模式 退出全屏模式
-
ref of typeRef是对 Products 集合中的此文档的引用,其中id 29530899167715846。
-
ts 是文档创建的时间戳,以微秒为单位。
-
data 是文档的实际内容。
回到我们的路由,如果查询成功,在响应体中会返回创建文档的id:
response.send(200, {
productId: result.ref.id
});
进入全屏模式 退出全屏模式
最后,如果 Fauna 返回任何错误,客户端将引发异常。我们将捕获该异常并使用 getFaunaError() 实用函数的结果进行响应:
const faunaError = getFaunaError(error);
response.send(faunaError.status, faunaError);
进入全屏模式 退出全屏模式
阅读产品文档
下一条路线将从 Products 集合中读取单个文档。
将此代码添加到 index.js 文件中。它将在 /products/:productId 处处理 GET 请求:
router.add('GET', '/products/:productId', async (request, response) => {
try {
const productId = request.params.productId;
const result = await faunaClient.query(
Get(Ref(Collection('Products'), productId))
);
response.send(200, result);
} catch (error) {
const faunaError = getFaunaError(error);
response.send(faunaError.status, faunaError);
}
});
进入全屏模式 退出全屏模式
FQL 查询使用Get函数从文档引用中检索完整文档:
Get(Ref(Collection('Products'), productId))
进入全屏模式 退出全屏模式
如果文档存在,我们将在响应正文中简单地返回它:
response.send(200, result);
进入全屏模式 退出全屏模式
否则,将返回错误。
删除产品文档
删除文档的逻辑非常相似。将此路由添加到 index.js 文件:
router.add('DELETE', '/products/:productId', async (request, response) => {
try {
const productId = request.params.productId;
const result = await faunaClient.query(
Delete(Ref(Collection('Products'), productId))
);
response.send(200, result);
} catch (error) {
const faunaError = getFaunaError(error);
response.send(faunaError.status, faunaError);
}
});
进入全屏模式 退出全屏模式
与上一条路线的唯一区别是,我们现在使用Delete函数通过其引用删除文档。
如果删除操作成功,Fauna 将返回删除的文档,并在响应正文中发送。如果不是,将返回一个错误。
测试和部署 Worker
在部署 Worker 之前,让我们使用 Wrangler 的dev命令在本地对其进行测试:
wrangler dev
进入全屏模式 退出全屏模式
一旦开发服务器启动并运行,我们就可以开始向我们的 Worker 发出 HTTP 请求。
首先,让我们创建一个新产品:
curl -i -d '{"serialNumber": "H56N33834", "title": "Bluetooth Headphones", "weightLbs": 0.5}' -H 'Content-Type: application/json' -X POST http:///127.0.0.1:8787/products
进入全屏模式 退出全屏模式
我们应该在正文中收到带有此 JSON 的 200 响应:
{"productId":"<document_id>"}
进入全屏模式 退出全屏模式
现在让我们阅读我们刚刚创建的文档:
curl -i -H 'Content-Type: application/json' -X GET http:///127.0.0.1:8787/products/<document_id>
进入全屏模式 退出全屏模式
响应将是序列化为 JSON 的文档:
{"ref":{"@ref":{"id":"<document_id>","collection":{"@ref":{"id":"Products","collection":{"@ref":{"id":"collections"}}}}}},"ts":1617887459975000,"data":{"serialNumber":"H56N33834","title":"Bluetooth Headphones","weightLbs":0.5,"quantity":0}}
进入全屏模式 退出全屏模式
最后,我们可以使用publish命令部署我们的 Worker:
wrangler publish
进入全屏模式 退出全屏模式
这将在 Cloudflare 的网络上发布 Worker,并将在我们的 workers.dev 子域上可用。
更新库存数量
我们现在要更新库存中产品的数量,默认为 0。
但是,这提出了一个问题。要计算产品的总量,我们首先需要确定有多少物品。如果我们在两个查询中解决这个问题,首先读取数量然后更新它,原始数据可能已经改变。
为了解决这个问题,我们将在单个 FQL 事务中读取和更新产品的数量。值得一提的是,所有 FQL 查询实际上都是事务。如果出现任何故障,由于 Fauna 的 ACID 属性,所有更改都将恢复。
将此路由添加到 index.js 文件,该文件将响应 /products/:productId/add-quantity 端点上的 PATCH 请求:
router.add('PATCH', '/products/:productId/add-quantity', async (request, response) => {
try {
const productId = request.params.productId;
const {quantity} = await request.body();
const result = await faunaClient.query(
Let(
{
productRef: Ref(Collection('Products'), productId),
productDocument: Get(Var('productRef')),
currentQuantity: Select(['data', 'quantity'], Var('productDocument'))
},
Update(
Var('productRef'),
{
data: {
quantity: Add(
Var('currentQuantity'),
quantity
)
}
}
)
)
);
response.send(200, result);
} catch (error) {
const faunaError = getFaunaError(error);
response.send(faunaError.status, faunaError);
}
});
进入全屏模式 退出全屏模式
让我们更详细地检查 FQL 查询:
Let(
{
productRef: Ref(Collection('Products'), productId),
productDocument: Get(Var('productRef')),
currentQuantity: Select(['data', 'quantity'], Var('productDocument'))
},
Update(
Var('productRef'),
{
data: {
quantity: Add(
Var('currentQuantity'),
quantity
)
}
}
)
)
进入全屏模式 退出全屏模式
首先,我们使用Let函数来建立我们稍后需要的一些变量:
-
productRef of type Ref 是文档参考
-
productDocument 包含完整的产品文档,由 Get 函数返回。
-
currentQuantity 包含文档中quantity 属性的值。我们使用Select函数提取属性
通过使用Var函数,Let 创建的变量可用于任何后续 FQL 表达式。
声明变量后,Let 接受第二个参数,该参数可以是任何 FQL 表达式,我们将在其中更新文档:
Update(
Var('productRef'),
{
data: {
quantity: Add(
Var('currentQuantity'),
quantity
)
}
}
)
进入全屏模式 退出全屏模式
Update函数只会更新文档的定义属性。在此示例中,将仅更新 quantity 属性。
我们使用 Var("productRef") 来获取相关文档的引用,正如 Let 之前定义的那样。
最后,我们通过使用Add函数将 currentQuantity 与 quantity JavaScript 变量相加来计算总量。
需要指出的一个重要方面是,即使多个 Worker 正在从世界不同地区更新这些数量,Fauna 也将保证所有 Fauna 地区的数据的一致性。
这是一篇文章,详细介绍了 Fauna 的分布式协议如何在不需要原子钟的情况下工作。
现在让我们测试一下我们的路线:
curl -i -d '{"quantity": 5}' -H 'Content-Type: application/json' -X PATCH http:///127.0.0.1:8787/products/<document_id>/add-quantity
进入全屏模式 退出全屏模式
响应应该是我们完整更新的文档,其中包含五个额外的项目:
{"ref":{"@ref":{"id":"<document_id>","collection":{"@ref":{"id":"Products","collection":{"@ref":{"id":"collections"}}}}}},"ts":1617890383200000,"data":{"serialNumber":"H56N33834","title":"Bluetooth Headphones","weightLbs":0.5,"quantity":5}}
进入全屏模式 退出全屏模式
要更新 Cloudflare 网络中的 Worker,只需再次发布即可:
wrangler publish
进入全屏模式 退出全屏模式
清理
尽管我们一直在使用 Fauna 和 Cloudflare Workers 免费套餐,但最好删除已使用的资源以防止未来产生任何额外费用。
可以从 Fauna 仪表板的设置中删除 Fauna 数据库:
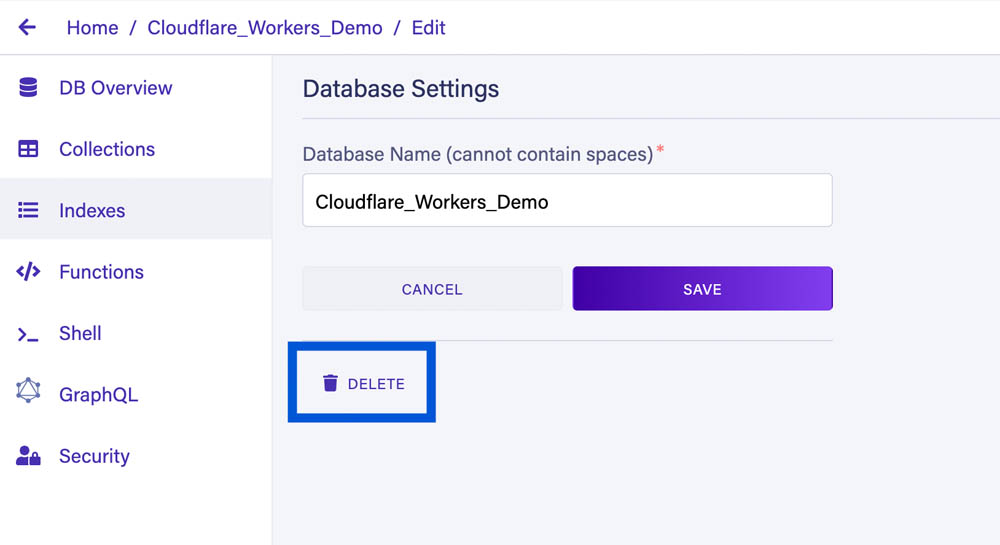
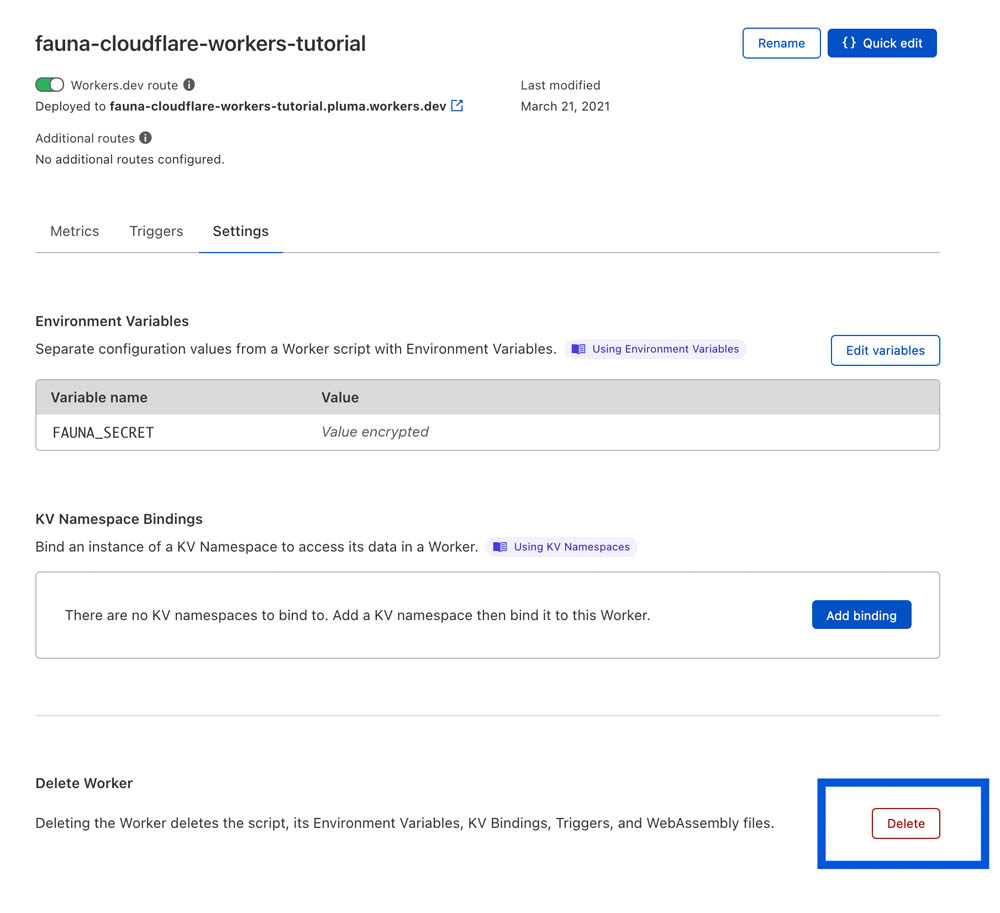
Cloudflare Worker 可以从 Cloudflare 仪表板的 Worker 设置中删除:
后续步骤
在这篇文章中,您了解了如何将 Fauna 与 Cloudflare Workers 结合使用来创建下一代无服务器应用程序,该应用程序可以轻松处理超连接的全球受众的需求。
当这两种技术结合起来时,我们只触及了表面。
对应用程序的进一步改进
此库存应用程序故意保持非常简单,但缺乏基本功能。
例如,API 的所有端点都是公共的。以下是一些指南,将教您如何在 Fauna 中使用身份验证和细粒度授权:
-
Fauna 身份验证和授权简介
-
将 Fauna 与 Node.js 结合使用的介绍将扩展本教程中介绍的一些概念。
另一个重要的改进是添加一些报告功能。为此,您需要更深入地了解动物区系索引和数据聚合:
-
动物区系索引介绍
-
动物区系数据聚合简介
最后,我们可以将更新库存数量的逻辑封装到自定义 FQL 函数中。这些在 Fauna 术语(用户定义函数)中称为 UDF,在概念上类似于存储过程:
- Fauna 自定义函数介绍
学习FQL
以下是一些 FQL 指南,将教您如何利用 Fauna 的全部力量:
**开始使用 FQL **
-
第 1 部分:基本动物群概念
-
第 2 部分:深入研究索引
-
第 3 部分:使用动物群建模数据
-
第 4 部分:在动物群中运行自定义函数
-
第 5 部分:动物群中的身份验证和授权
核心 FQL 概念
-
第 1 部分:使用日期和时间
-
第 2 部分:动物群的时间性
-
第 3 部分:数据聚合
-
第 4 部分:范围查询和高级过滤
-
第 5 部分:连接
不要忘记加入Fauna 开发者社区!

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35526条内容
已为社区贡献35526条内容

所有评论(0)